







 本文介绍了如何使用sklearn库对鲍鱼年龄预测数据集进行探索性分析、预处理,包括特征处理、模型构建(线性回归、岭回归和LASSO),以及模型效果的评估,包括残差图和各种误差指标如MAE、MSE和R2分数。
本文介绍了如何使用sklearn库对鲍鱼年龄预测数据集进行探索性分析、预处理,包括特征处理、模型构建(线性回归、岭回归和LASSO),以及模型效果的评估,包括残差图和各种误差指标如MAE、MSE和R2分数。
sklearn回归综合案例:鲍鱼年龄预测
本篇文章中使用Abalone Data Set数据集进行预测。
1.数据集探索性分析
1.1读取数据集
(1)首先将鲍鱼数据集abalone_dataset.csv读取为Pandas的DataFrame格式.
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('abalone_dataset.csv')
data.head() #查看数据集前几行
运行的结果如下:
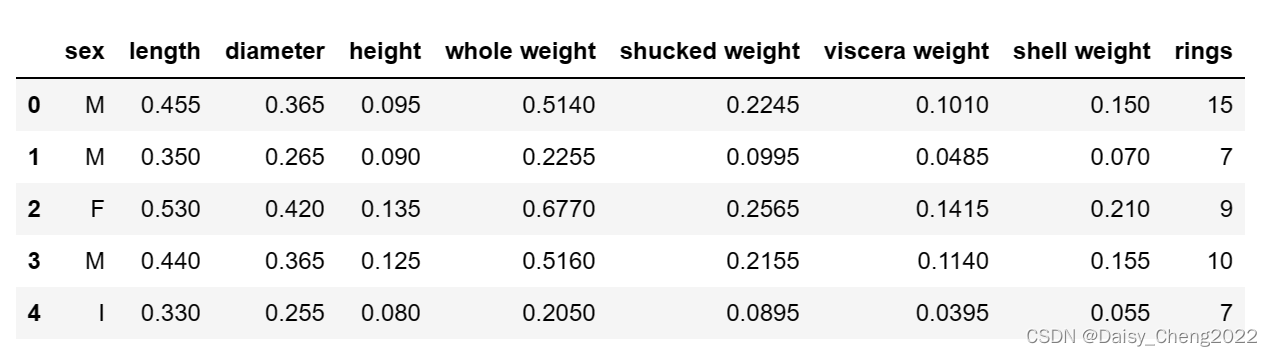
(2)查看数据集的部分信息
#查看数据集中样本数量和特征数量
data.shape
#查看数据信息,检查是否有缺失值
data.info()
data.describe()
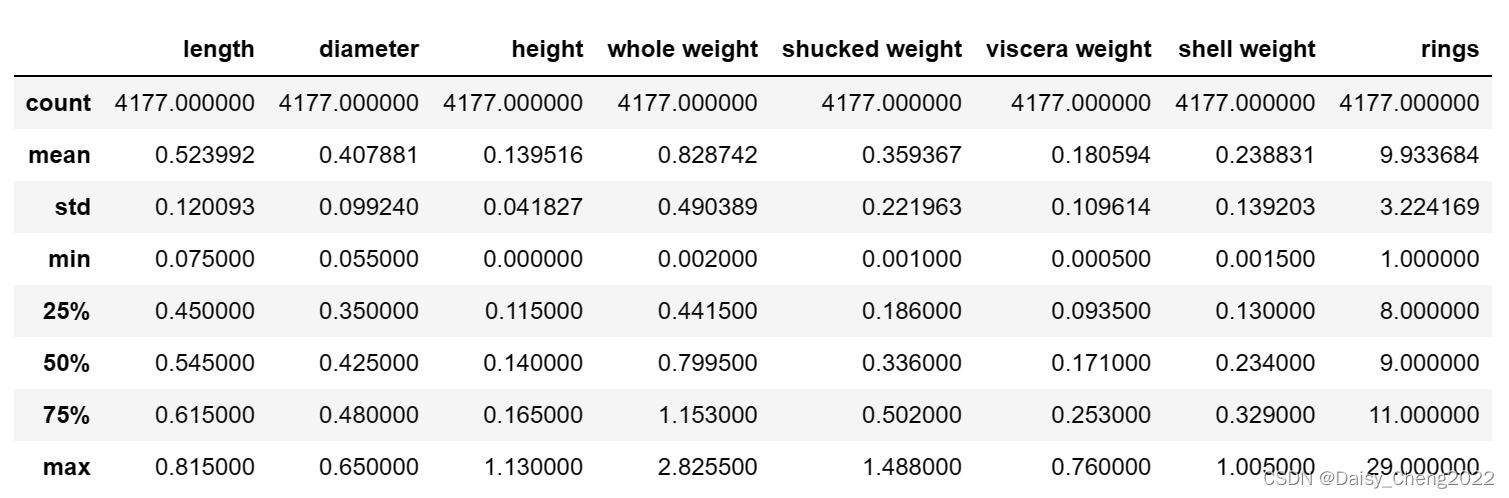
数据集一共有4177个样本,每个样本有9个特征。其中rings为鲍鱼环数,能够代表鲍鱼年龄,是预测变量(因变量)。除了sex为离散特征,其余都为连续变量。
(3)观察sex列的取值分布情况
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.countplot(x = 'sex', data = data)
print(data['sex'].value_counts())
1.2数据可视化分析
(4)对于连续特征,可以使用seaborn的displot函数绘制直方图观察特征取值情况。
i = 1 #子图计数
plt.figure(figsize = (16, 8))
for col in data.columns[1:]:
plt.subplot(4, 2, i)
i = i + 1
sns.distplot(data[col])
plt.tight_layout()
运行结果:
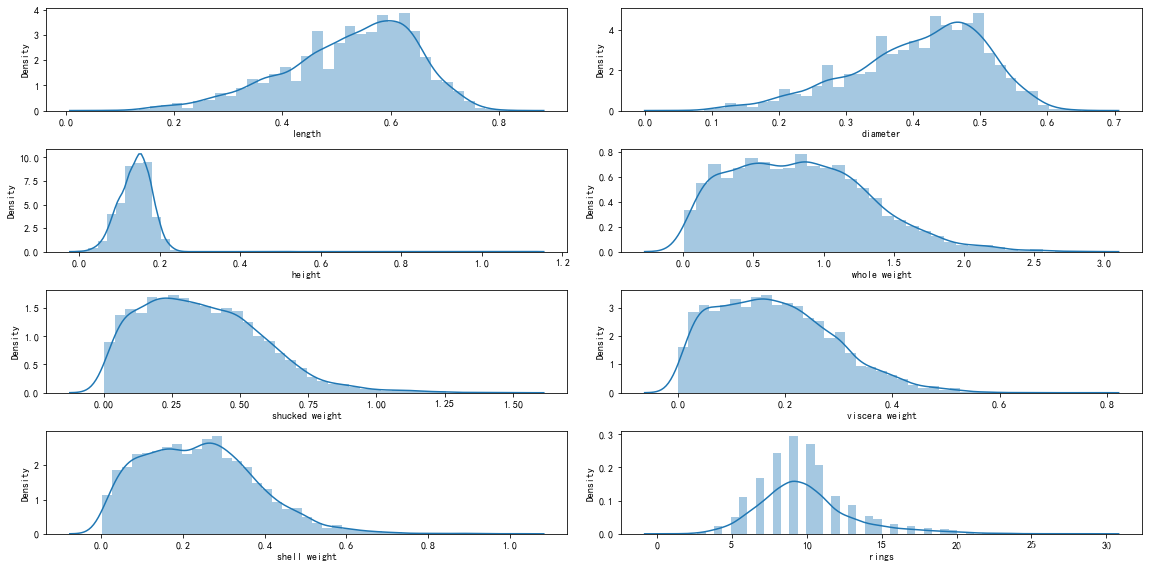
还可以使用sns.pairplot(data, hue="sex")观察data的特征。
(5)定量地分析特征之间的线性相关性,使用corr_df = data.corr()
(6)绘制热力图
fig, ax = plt.subplots(figsize = (12, 12))
ax = sns.heatmap(corr_df, linewidths = 5,
cmap = "Greens",
annot = True,
xticklabels = corr_df.columns,
yticklabels = corr_df.index)
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
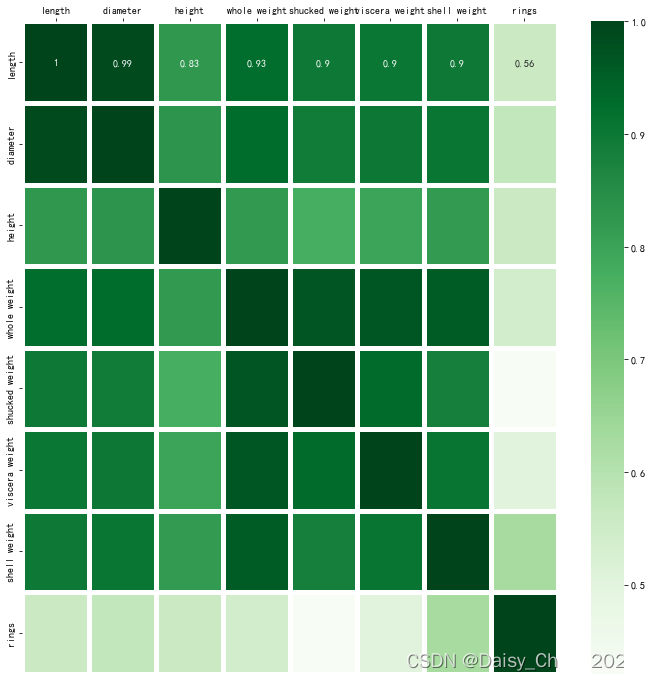
- 因变量颜色最浅,说明因变量
rings与其他变量线性相关性最弱。
2.鲍鱼数据集预处理
2.1处理sex特征
因为sex特征是离散变量,需要用Pandas的get_dummies函数对sex特征做独热编码处理
import pandas as pd
sex_onehot = pd.get_dummies(data['sex'], prefix = 'sex') #prefix是前缀
data[sex_onehot.columns] = sex_onehot #将处理后的数据加入数据表的后三列
data.head()
运行结果:
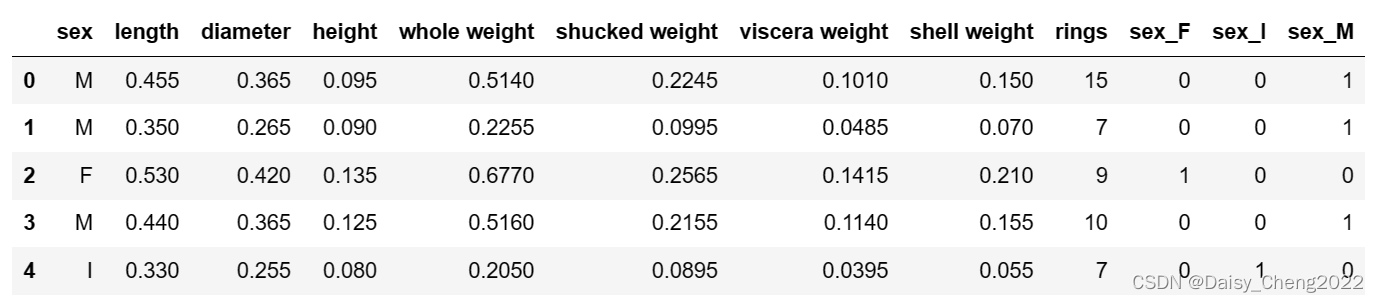
需要挑选出其中的最大无关组,否则多重共线性会影响模型出现幻觉。经观察后三列只需要其中两列即可。
2.2添加取值为1的特征(theta_0列)
利用解析解求回归系数
data['ones'] = 1
print(data.head())
2.3根据鲍鱼环计算年龄
data['age'] = data['rings'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









