






1.k-近邻的Sklearn实现
1.1.生成数据集
#导入make_blobs
data, label = make_blobs(n_features = 2,
n_samples = 100,
centers = 3,
random_state = 3,
cluster_std = [0.8, 2, 5]
)
n_features表示每一个样本有多少特征值n_samples表示样本的个数centers是聚类中心点的个数,可以理解为Label的种类数random_state是随机种子,可以固定生成的数据cluster_std设置每个类别的方差
#导入数据集生成器
from sklearn.datasets import make_blobs
#生成样本数为200,分类为2的数据集
data = make_blobs(n_samples = 200, centers = 2, random_state = 8)
print(data)
#分离自变量与因变量
X, y = data
#数据可视化
import matplotlib.pyplot as plt
%matplotlib inline
plt.scatter(X[:,0],X[:,1], c=y, cmap=plt.cm.spring, edgecolors='k')
#默认效果
plt.scatter(X[:,0],X[:,1], c=y)
运行结果如图:
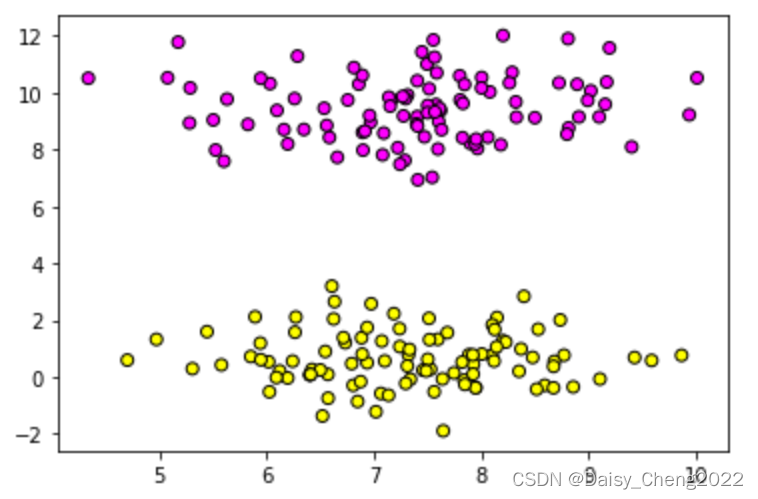 图1 修改后效果 图1 修改后效果
|
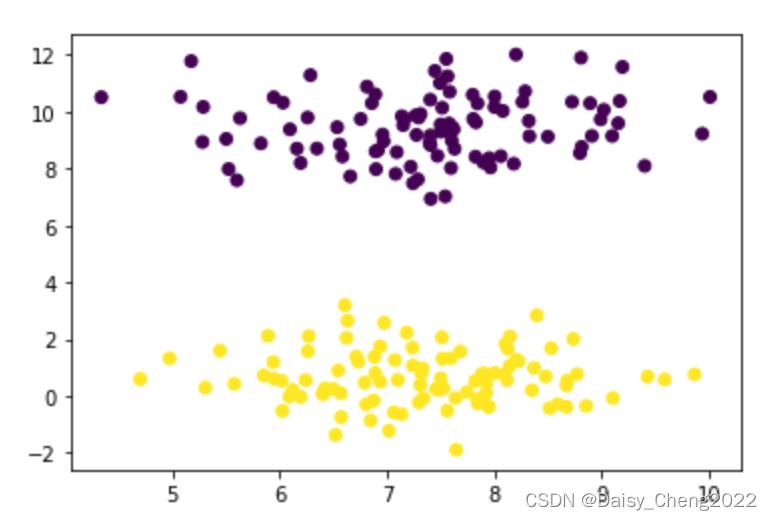 图2 默认效果 图2 默认效果
|
1.2.sklearn中的KNN分类器
from sklearn.neighbors import KNeighborsClassifier #导入分类器
KNeighborsClassifier(
n_neighbors = 5,
weights = 'uniform',
algorithm = 'auto',
leaf_size = 30,
metric_params = 'minkowski'
n_neighborsint类型, 最近的几个样本具有投票权,通常为单数weights等比重投票,'distance’表示按距离反比投票algorithm即内部采用什么算法实现leaf_size此参数给出了kd_tree或者ball_tree叶节点规模metric_params距离度量对象,即怎样度量距离
import numpy as np
#导入KNN分类器
from sklearn.neighbors import KNeighborsClassifier
#KNN分类器实例化
clf = KNeighborsClassifier()
#模型训练
clf.fit(X, y)
将数据分类结果可视化:
#训练结果可视化
x_min, x_max = X[:,0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:,1].min() - 1, X[:, 1].max() + 1
#把x,y轴分块,找出很密的一堆点
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
#把刚才找到的密密麻麻的点,每个点都预测一个类别
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape) #形状变化
#把这些点,按类别的不同赋予不同的颜色
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
#绘制散点图,按照
plt.scatter(X[:, 0], X[:,1], c=y, cmap = plt.cm.spring, edgecolor = 'k')
#限制坐标范围
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:KNN")

加入一个新的点预测其类别:
#训练结果可视化
#对新数据点进行可视化
#框出坐标范围,寻找上下界
x_min, x_max = X[:,0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:,1].min() - 1, X[:, 1].max() + 1
#把x,y轴分块,找出很密的一堆点
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
#把刚才找到的密密麻麻的点,每个点都预测一个类别
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape) #形状变化
#把这些点,按类别的不同赋予不同的颜色
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
#绘制散点图,按照
plt.scatter(X[:, 0], X[:,1], c=y, cmap = plt.cm.spring, edgecolor = 'k')
#限制坐标范围
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:KNN")
#对新数据点进行可视化
plt.scatter(6.75, 4.82, marker='*', c='red', s=200)
print('新数据点的分类是:', clf.predict([[6.75, 4.82]]))

1.3KNN拟合多分类问题
#生成样本数是500,类别数是5的数据集
data2 = make_blobs(n_samples = 500, centers = 5, random_state = 8)
X2, y2 = data2
plt.scatter(X2[:, 0], X2[:, 1], c=y2, cmap=plt.cm.spring, edgecolor='k')
plt.show()
查看原始数据分布:

#用KNN模型进行拟合
clf = KNeighborsClassifier()
clf.fit(X2, y2)
#对拟合结果进行可视化
x_min, x_max = X2[:,0].min() - 1, X2[:, 0].max() + 1
y_min, y_max = X2[:,1].min() - 1, X2[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape) #形状变化
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Pastel1)
plt.scatter(X2[:, 0], X2[:,1], c=y2, cmap = plt.cm.spring, edgecolor = 'k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:KNN")
#plt.scatter(6.75, 4.82, marker='*', c='red', s=200)
plt.show()
查看分类情况:

模型评估:
print('模型正确率:{:.2f}'.format(clf.score(X2, y2)))
运行结果:模型正确率:0.96
1.4 KNN实战葡萄酒分类
#导入所需要的库
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split
#加载数据
wine = datasets.load_wine()
#查看相关信息
wine.keys()
wine.data.shape #查看自变量数据维度
print(wine.DESCR)
数据预处理:
#为便于可视化,取前两个特征纳入模型
X = wine.data[:, :2]
y = wine.target
#划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
print('X_train:{}, X_test:{}'.format(X_train.shape, X_test.shape))
#KNN模型实例化
clf = neighbors.KNeighborsClassifier(n_neighbors=15, weights='distance')
#模型训练
clf.fit(X_train, y_train)
print("测试集模型评分:{:.2f}".format(clf.score(X_test, y_test)))
print("训练集模型评分:{:.2f}".format(clf.score(X_train, y_train)))
结果为:
测试集模型评分:0.89
训练集模型评分:1.00
笔记持续更新中,敬请期待















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









