







有关SSD的基本原理本文不做多余的赘述,具体参考其他大神的博文,如:目标检测之SSD

本章我们利用SSD来检测图片中的皮卡丘:

mxnet中已经有一个皮卡丘的检测数据集,下面对它进行下载:
# 下载皮卡丘数据集
root_url = ('https://apache-mxnet.s3-accelerate.amazonaws.com/'
'gluon/dataset/pikachu/')
dataset = {'train.rec': 'e6bcb6ffba1ac04ff8a9b1115e650af56ee969c8',
'train.idx': 'dcf7318b2602c06428b9988470c731621716c393',
'val.rec': 'd6c33f799b4d058e82f2cb5bd9a976f69d72d520'}
data_dir="pikaqiu_object/"
for k, v in dataset.items():
gutils.download(root_url + k, data_dir+ k, sha1_hash=v)
当文件下载好之后,我们写一段程序把它读进来:
# 读取数据
def load_data_pikachu(batch_size, edge_size=256): # edge_size:输出图像的宽和高
class_names=["pikaqiu"]
num_class=len(class_names)
train_iter = image.ImageDetIter(
path_imgrec='pikaqiu_object/train.rec',
path_imgidx='pikaqiu_object/train.idx',
batch_size=batch_size,
data_shape=(3, edge_size, edge_size), # 输出图像的形状
shuffle=True, # 以随机顺序读取数据集
rand_crop=1, # 随机裁剪的概率为1
min_object_covered=0.95, max_attempts=200)
val_iter = image.ImageDetIter(
path_imgrec='pikaqiu_object/val.rec', batch_size=batch_size,
data_shape=(3, edge_size, edge_size), shuffle=False)
return train_iter, val_iter,class_names,num_class
之后把它打印出来看看:
batch_size=32
edge_size=256
train_data,test_data,class_names,num_class=load_data_pikachu(batch_size,edge_size)
batch=train_data.next()
print(batch)
结果:
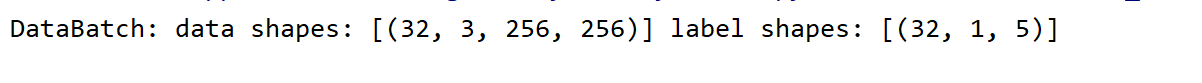
可以看到,图像数据依旧与之前分类数据一样,是一个batch×channel×h×w的类型。但是label不再是一个单个数字了,而是一个多标签数组,其中的32表示batch,1表示1张图片里面只有1个皮卡丘,5包含5个数字,第1个数字表示边界框的类别,后面4个数字表示矩形框的坐标(左上角x,y和右下角x,y坐标)。
显示一下图片看看:
def box_to_rect(box,color):
box=box.asnumpy()
return plt.Rectangle((box[0],box[1]),box[2]-box[0],box[3]-box[1],
fill=False,edgecolor=color,linewidth=3)
_,figs=plt.subplots(3,3,figsize=(6,6))
for i in range(3):
for j in range(3):
img,labels=batch.data[0][3*i+j],batch.label[0][3*i+j]
img=img.transpose((1,2,0))
figs[i][j].imshow(img.clip(0,255).asnumpy()/255)
for label in labels:
rect=box_to_rect(label[1:5]*edge_size,"red")
figs[i][j].add_patch(rect)
figs[i][j].axes.get_xaxis().set_visible(False)
figs[i][j].axes.get_yaxis().set_visible(False)
plt.show()
结果:

SSD模型
1、锚框:默认的边界框
因为边框可以出现在图片中的任意位置,并且可以有任意大小,为了简化计算,SSD与Faster RCNN一样使用一些默认的边界框,或者称之为锚框(anchor box),作为搜索起点。总的来说,对于输入的每个像素点,以其为中心,采样数个不同形状,不太大小的边界框,假设图片输入大小为
w
×
h
w×h
w×h,则:
1)给定大小
s
∈
(
0
,
1
]
s\in(0,1]
s∈(0,1],那么生成的边界框形状为
w
s
×
h
s
ws×hs
ws×hs。
2)给定比例(长宽比)
r
>
0
r>0
r>0,那么生成的边界框形状为
w
r
×
h
r
w\sqrt{r}×\frac{h}{\sqrt{r}}
wr×rh(为什么这样定义?因为这样计算的话框的面积是不变的)。
在采样的时候我们提供
n
n
n个大小(sizes)和
m
m
m个比例(ratios),为了计算简单,这里不生成
m
n
mn
mn个锚框,而是
n
+
m
−
1
n+m-1
n+m−1个。其中第
i
i
i个锚框使用:
1)sizes
[
i
]
[i]
[i]和ratios
[
0
]
[0]
[0],
i
≤
n
i\leq n
i≤n;
2)sizes
[
0
]
[0]
[0]和ratios
[
i
−
n
]
[i-n]
[i−n],
i
>
n
i>n
i>n。
接下来演示在mxnet中如何生成锚框:
from mxnet import contrib
# (输入x)NCHW
x=nd.random_normal(shape=(1,3,40,40))
y=contrib.nd.MultiBoxPrior(x,sizes=[0.75,0.5,0.1],ratios=[1,2,0.5])# 3+3-1=5,共有5种
print(y.shape)
结果:
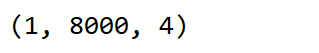
从结果中我们可以看到锚框y的形状为[1,8000,4],它分别表示为[批量大小,锚框个数(40×40×5),锚框的4个坐标值],其中 4个坐标值分别已除以图像的宽和高,因此值域均为0和1之间。
比如,随即找个点(20,20),接下来画出以(20,20)为中心的所有锚框[x_min,y_min,x_max,y_max]:
print(boxes[20,20,0,:]) # 以20,20为中心的第一个框
# 画出以(20,20)为中心的所有锚框[x_min,y_min,x_max,y_max]
colors=['blue','red','green','black','magenta'] # 总共5个锚框
anchors=boxes[20,20,:,:]
image=nd.ones(shape=(40,40,3)).asnumpy()
plt.imshow(image)
for i in range(anchors.shape[0]):
plt.gca().add_patch(box_to_rect(anchors[i,:]*40,colors[i])) # 40是原图像的宽高
plt.show()
结果:


可以看到,以像素点坐标为(20,20)的周围生成了5个大小和形状不同的锚框(所有像素点周围都会生成5个锚框)。
2、预测物体类别
(1)对于每一个锚框,我们需要预测它是不是包含了我们所需要的物体,还是它只是一个背景。这里我们使用一个3X3的卷积来做预测,设置pad=1(边缘填充),使得输入与输出的大小一样。同时,输出的通道数为num_anchors×(num_classes+1)(这里的“1”是背景)。每个通道对应一个锚框对某类的置信度。比如输出是y,那么对应输入中第n个样本的第(i,j)像素的置信度值在y[n,:,i,j]中。具体来说,对于以[i,j]为中心的第a个锚框:
1)通道a*[num_class+1]是其只包含背景的分数;
2)通道a*[num_class+1]+b+1是包含第b个物体的分数。
# 定义类别分类器
def class_predict(num_anchors,num_classes):
return gn.nn.Conv2D(num_anchors*(num_classes+1),3,padding=1)
cls_pre=class_predict(5,10)
cls_pre.initialize()
k=nd.random_normal(shape=(2,3,10,10))
print(cls_pre(k).shape)
结果:
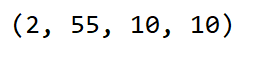
3、预测边界框
因为真实的边界框可以是任何形状,我们需要预测如何从一个锚框变成真实的边界框,这个变换可以从一个长为4的向量来描述。同上一样,我们用一个有num_anchors×4通道的卷积。假设输出是y,那么对应输入中第n个样本的第(i,j)像素为中心的锚框的转换在y[n,:,i,j]中。具体来说,对于第a个锚框,它的变换在a×4到a×4+3里。
def box_predict(num_anchors):
return gn.nn.Conv2D(num_anchors *4, 3, padding=1)
box_pre=box_predict(10)
box_pre.initialize()
print(box_pre(k).shape)
结果:
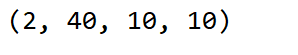
4、减半模块
为了进一步提升检测精度,单单经过一个卷积块往往是不够的,所以需要再进行几个卷积块的抽取,更高层次的去检测相关物体,同时,使用池化方法使得图像长宽减半。
def sample_dowm(num_filters):
out=gn.nn.Sequential()
for _ in range(2):
out.add(gn.nn.Conv2D(num_filters,3,1,1))
out.add(gn.nn.BatchNorm(in_channels=num_filters))
out.add(gn.nn.Activation("relu"))
out.add(gn.nn.MaxPool2D(2))
return out
blk=sample_dowm(10)
blk.initialize()
m=nd.random_normal(shape=(2,3,8,8))
print(blk(m).shape)
结果:
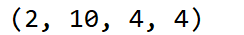
5、合并来自不同层的预测输出
由于SSD会在多个层上做预测,每个层由于长宽、锚框不一样,导致输出的数据形状会不一样,这里我们用物体类别预测作为样例,边框预测也是类似的。
我们首先定义一个特定大小的图片,然后对它输出类别进行预测,然后减半,再输出预测类别。
input=nd.random_normal(shape=(2,8,20,20))
print("input:",input.shape)
cls_pred1=class_predict(5,10)
cls_pred1.initialize()
pred1=cls_pred1(input)
print("pre result 1:",pred1.shape)
ds=sample_dowm(16)
ds.initialize()
input=ds(input)
print("down input:",input.shape)
cls_pred2=class_predict(3,10)
cls_pred2.initialize()
pred2=cls_pred2(input)
print("pre result 2:",pred2.shape)
结果:
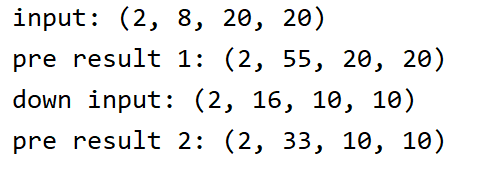
因为loss支持的是一个单值,而这里输出的结果是一个4D的矩阵,所以我们需要把4D转为2D。通过观察我们可以发现:

除了batch为2以外,后面的值都可以变动,把它像全连接层输入那样,后面3个值乘起来不就好了,最后直接融合就完成了。
def flatten_prediction(pred):
return pred.transpose(axes=(0,2,3,1)).flatten()
def concat_prediction(preds): # preds是一个list数组
return nd.concat(*preds,dim=1)
# 把它们转换并融合
print("==========")
y1=flatten_prediction(pred1)
print("Flatten class pre 1:",y1.shape)
y2=flatten_prediction(pred2)
print("Flatten class pre 2:",y2.shape)
y_all=concat_prediction([y1,y2])
print("concat result:",y_all.shape)
结果:

6、主体网络
'''---主体网络---'''
# 主体网络就是第一个卷积块,通常来说会用一个比较好的模型来抽取特征(这里随便定义一个模型)
def body():
out=gn.nn.HybridSequential()
for nfilter in [16,32,64]:
out.add(sample_dowm(num_filters=nfilter))
return out
bnet=body()
bnet.initialize()
print(bnet(k).shape)
结果:
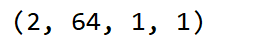
7、创建SSD
前期工作都做好了,现在我们来创建一个简单的SSD模型,这里定义的模型包含4块,主体网络、三个减半模块、五个物体类别和边框预测模块。其中,预测分别应用在主体网络、三个减半模块和最后的全局平均池化上。
# 简单的SSD模型
def SSD_Model(num_anchors,num_classes):
downsamples=gn.nn.HybridSequential()
for _ in range(3):
downsamples.add(sample_dowm(128))
class_predicts=gn.nn.HybridSequential()
box_predicts=gn.nn.HybridSequential()
for _ in range(5):
class_predicts.add(class_predict(num_anchors,num_classes))
box_predicts.add(box_predict(num_anchors))
model=gn.nn.HybridSequential()
model.add(body(),downsamples,class_predicts,box_predicts)
return model
# 计算预测
def ssd_forward(x,model,sizes,ratios):
body,downsamples,class_predicts,box_predicts=model
anchors,class_preds,box_preds=[],[],[]
x=body(x)
for i in range(5):
anchors.append(contrib.nd.MultiBoxPrior(x,sizes=sizes[i],ratios=ratios[i]))
class_preds.append(flatten_prediction(class_predicts[i](x)))
box_preds.append(flatten_prediction(box_predicts[i](x)))
print("predict scale",i,x.shape,"with",anchors[-1].shape[1],"anchors")
if i<3:
x=downsamples[i](x)
elif i==3:
x=nd.Pooling(x,global_pool=True,pool_type="max",
kernel=(x.shape[2],x.shape[3]))
# 融合结果
return (concat_prediction(anchors),concat_prediction(class_preds),
concat_prediction(box_preds))
'''---完整的模型---'''
class ToySSD(gn.Block):
def __init__(self,num_classes,**kwargs):
super(ToySSD, self).__init__(**kwargs)
self.sizes=[[0.2,0.272],[0.37,0.447],[0.54,0.618],[0.7,0.8],[0.88,0.9]]
self.ratios=[[1,2,0.5]]*5
self.num_classes=num_classes
num_anchors=len(self.sizes[0]+self.ratios[0])-1
with self.name_scope():
self.model=SSD_Model(num_anchors,num_classes)
def forward(self, x):
anchors,class_preds,box_preds=ssd_forward(x,self.model,self.sizes,
self.num_classes)
class_preds=class_preds.reshape(shape=(0,-1,self.num_classes+1)) #0表示不管有多少个batch_size,copy过来
return anchors,class_preds,box_preds
看一下图片的形状是如何变化的:
print("====================")
net=ToySSD(num_classes=2)
net.initialize()
x=batch.data[0][0:1]
print("x:",x.shape)
anchors_,class_pre,box_pre=net(x)
print("output anchors:",anchors_.shape)
print("output class_pre:",class_pre.shape)
print("output box_pre:",box_pre.shape)
结果:

8、损失函数
在回归问题上,我们经常用的两类损失函数分别为L1和L2,但由于L2对较大误差的惩罚力度过大,所以鲁棒性较差。由于目标检测涉及到分类和回归,本章则使用交叉熵和L1损失来进行实验。
Smooth L1损失——回归预测
虽说L1损失鲁棒性更好,但它有一个很明显的缺陷:它在原点处是断的(不光滑),所以导致它在原点有无数个导数,针对这个现象,Smooth L1损失出现了,它是光滑后的L1,什么意思?看下图:

从图中可以看到,橘色或绿色的函数,它们在原点处是一段光滑的曲线,且导数只有一个,对于Smooth L1函数,有:
f
(
n
)
=
{
(
σ
x
)
2
/
2
,
if
∣
x
∣
<
1
/
σ
2
∣
x
∣
−
0.5
,
otherwise
f(n) = \begin{cases} (\sigma x)^2/2, & \text{if $|x|<1/\sigma^2$ } \\ |x|-0.5, & \text{otherwise} \end{cases}
f(n)={(σx)2/2,∣x∣−0.5,if ∣x∣<1/σ2 otherwise
代码:
class smoothLoss(gn.loss.Loss): # box reg loss
def __init__(self,batch_axis=0,**kwargs):
super(smoothLoss, self).__init__(None,batch_axis,**kwargs)
def hybrid_forward(self, F,output,label, mask, *args, **kwargs):
loss=F.smooth_l1((output-label)*mask,scalar=1.0) # 参数mask,用来屏蔽不需要被惩罚的负例样本
return loss.mean(self._batch_axis,exclude=True)
交叉熵损失函数
对于分类,本文依旧使用交叉熵损失函数。
9、准确率计算
# 我们可以沿用准确率评价分类结果。因为使用了 L1 范数损失,我们用平均绝对误差评价边界框的预测结果。
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维
return (cls_preds.argmax(axis=-1) == cls_labels).sum().asscalar()
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return ((bbox_labels - bbox_preds) * bbox_masks).abs().sum().asscalar()
10、loss计算
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
cls = cls_loss(cls_preds, cls_labels)
bbox = bbox_loss(bbox_preds , bbox_labels, bbox_masks)
return 0.1*cls + bbox # 对分类做了加权
11、训练
for epoch in range(100):
acc_sum, mae_sum, n, m = 0.0, 0.0, 0, 0
train_data.reset() # 从头读取数据
start = time.time()
for batch in train_data:
X = batch.data[0].as_in_context(ctx)
Y = batch.label[0].as_in_context(ctx)
with ag.record():
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = contrib.nd.MultiBoxTarget(
anchors, Y, cls_preds.transpose((0, 2, 1)))
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.backward()
trainer.step(batch_size)
acc_sum += cls_eval(cls_preds, cls_labels)
n += cls_labels.size
mae_sum += bbox_eval(bbox_preds, bbox_labels, bbox_masks)
m += bbox_labels.size
if (epoch + 1) % 10 == 0:
print('epoch %2d, class acc %f, bbox mae %f, time %.1f sec' % (
epoch + 1, acc_sum / n, mae_sum / m, time.time() - start))
12、检测
src=cv.imread("F:/test/pikaqiu.jpg")
dst=cv.resize(src,(256,256))
dst=cv.cvtColor(dst,cv.COLOR_BGR2RGB)
x=nd.array(dst).transpose((2,0,1)).expand_dims(axis=0)
net.load_parameters("SSD.params")
def predict(X):
anchors, cls_preds, bbox_preds = net(X.as_in_context(ctx))
cls_probs = cls_preds.softmax().transpose((0, 2, 1))
output = contrib.nd.MultiBoxDetection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0].asscalar() != -1]
return output[0, idx]
output = predict(x)
def display(img, output, threshold):
for row in output:
score = row[1].asscalar()
if score < threshold:
continue
h, w = img.shape[:2]
bbox = row[2:6].asnumpy()
cv.rectangle(img,(int(bbox[0]*w),int(bbox[1]*h)),(int(bbox[2]*w),int(bbox[3]*h)),(0,0,255),2)
cv.putText(img,str(score),(int(bbox[0]*w),int(bbox[1]*h-10)),
cv.FONT_HERSHEY_PLAIN,1.0,(0,255,0),2)
cv.imshow(" ",img)
cv.waitKey(0)
display(src, output, threshold=0.7)
检测结果:

放上所有代码:
import mxnet as mx
import mxnet.ndarray as nd
import mxnet.autograd as ag
import mxnet.gluon as gn
import mxnet.initializer as init
import numpy as np
import zipfile
import matplotlib.pyplot as plt
import cv2 as cv
from mxnet import contrib
import mxnet.image as im
import time
from mxnet.gluon import utils as gutils
# 下载皮卡丘数据集
# root_url = ('https://apache-mxnet.s3-accelerate.amazonaws.com/'
# 'gluon/dataset/pikachu/')
# dataset = {'train.rec': 'e6bcb6ffba1ac04ff8a9b1115e650af56ee969c8',
# 'train.idx': 'dcf7318b2602c06428b9988470c731621716c393',
# 'val.rec': 'd6c33f799b4d058e82f2cb5bd9a976f69d72d520'}
# data_dir="pikaqiu_object/"
# for k, v in dataset.items():
# gutils.download(root_url + k, data_dir+ k, sha1_hash=v)
# 读取数据
def load_data_pikachu(batch_size, edge_size=256): # edge_size:输出图像的宽和高
class_names=["pikaqiu"]
num_class=len(class_names)
train_iter = im.ImageDetIter(
path_imgrec='pikaqiu_object/train.rec',
path_imgidx='pikaqiu_object/train.idx',
batch_size=batch_size,
data_shape=(3, edge_size, edge_size), # 输出图像的形状
shuffle=True, # 以随机顺序读取数据集
rand_crop=1, # 随机裁剪的概率为1
min_object_covered=0.95, max_attempts=200)
val_iter = im.ImageDetIter(
path_imgrec='pikaqiu_object/val.rec', batch_size=batch_size,
data_shape=(3, edge_size, edge_size), shuffle=False)
return train_iter, val_iter,class_names,num_class
batch_size=32
edge_size=256
train_data,test_data,class_names,num_class=load_data_pikachu(batch_size,edge_size)
batch=train_data.next()
print(batch)
def box_to_rect(box,color):
box=box.asnumpy()
return plt.Rectangle((box[0],box[1]),box[2]-box[0],box[3]-box[1],
fill=False,edgecolor=color,linewidth=3)
_,figs=plt.subplots(3,3,figsize=(6,6))
for i in range(3):
for j in range(3):
img,labels=batch.data[0][3*i+j],batch.label[0][3*i+j]
img=img.transpose((1,2,0))
figs[i][j].imshow(img.clip(0,255).asnumpy()/255)
for label in labels:
rect=box_to_rect(label[1:5]*edge_size,"red")
figs[i][j].add_patch(rect)
figs[i][j].axes.get_xaxis().set_visible(False)
figs[i][j].axes.get_yaxis().set_visible(False)
plt.show()
# (输入x)NCHW
x=nd.random_normal(shape=(1,3,40,40))
y=contrib.nd.MultiBoxPrior(x,sizes=[0.75,0.5,0.1],ratios=[1,2,0.5])# 3+3-1=5,共有5种
print(y.shape)
boxes = y.reshape((40, 40, -1, 4))
print(boxes.shape)
print(boxes[20,20,0,:]) # 以20,20为中心的第一个框
# 画出以(20,20)为中心的所有锚框[x_min,y_min,x_max,y_max]
colors=['blue','red','green','black','magenta'] # 总共5个锚框
anchors=boxes[20,20,:,:]
image=nd.ones(shape=(40,40,3)).asnumpy()
plt.imshow(image)
for i in range(anchors.shape[0]):
plt.gca().add_patch(box_to_rect(anchors[i,:]*40,colors[i])) # 40是原图像的宽高
plt.show()
# 定义类别分类器
def class_predict(num_anchors,num_classes):
return gn.nn.Conv2D(num_anchors*(num_classes+1),3,padding=1)
cls_pre=class_predict(5,10)
cls_pre.initialize()
k=nd.random_normal(shape=(2,3,10,10))
print(cls_pre(k).shape)
def box_predict(num_anchors):
return gn.nn.Conv2D(num_anchors*4, 3, padding=1)
box_pre=box_predict(10)
box_pre.initialize()
print(box_pre(k).shape)
def sample_dowm(num_filters):
out=gn.nn.HybridSequential()
for _ in range(2):
out.add(gn.nn.Conv2D(num_filters,3,1,1))
out.add(gn.nn.BatchNorm(in_channels=num_filters))
out.add(gn.nn.Activation("relu"))
out.add(gn.nn.MaxPool2D(2))
return out
blk=sample_dowm(10)
blk.initialize()
m=nd.random_normal(shape=(2,3,8,8))
print(blk(m).shape)
input=nd.random_normal(shape=(2,8,20,20))
print("input:",input.shape)
cls_pred1=class_predict(5,10)
cls_pred1.initialize()
pred1=cls_pred1(input)
print("pre result 1:",pred1.shape)
ds=sample_dowm(16)
ds.initialize()
input=ds(input)
print("down input:",input.shape)
cls_pred2=class_predict(3,10)
cls_pred2.initialize()
pred2=cls_pred2(input)
print("pre result 2:",pred2.shape)
def flatten_prediction(pred):
return pred.transpose(axes=(0,2,3,1)).flatten()
def concat_prediction(preds): # preds是一个list数组
return nd.concat(*preds,dim=1)
# 把它们转换并融合
print("==========")
y1=flatten_prediction(pred1)
print("Flatten class pre 1:",y1.shape)
y2=flatten_prediction(pred2)
print("Flatten class pre 2:",y2.shape)
y_all=concat_prediction([y1,y2])
print("concat result:",y_all.shape)
'''---主体网络---'''
# 主体网络就是第一个卷积块,通常来说会用一个比较好的模型来抽取特征(这里随便定义一个模型)
def body():
out=gn.nn.HybridSequential()
for nfilter in [16,32,64]:
out.add(sample_dowm(num_filters=nfilter))
return out
bnet=body()
bnet.initialize()
print(bnet(k).shape)
# 简单的SSD模型
def SSD_Model(num_anchors,num_classes):
downsamples=gn.nn.HybridSequential()
for _ in range(3):
downsamples.add(sample_dowm(128))
class_predicts=gn.nn.HybridSequential()
box_predicts=gn.nn.HybridSequential()
for _ in range(5):
class_predicts.add(class_predict(num_anchors,num_classes))
box_predicts.add(box_predict(num_anchors))
model=gn.nn.HybridSequential()
model.add(body(),downsamples,class_predicts,box_predicts)
return model
# 计算预测
def ssd_forward(x,model,sizes,ratios,verbose=False):
body,downsamples,class_predicts,box_predicts=model
anchors,class_preds,box_preds=[],[],[]
x=body(x)
for i in range(5):
anchors.append(contrib.nd.MultiBoxPrior(x,sizes=sizes[i],ratios=ratios[i]))
class_preds.append(flatten_prediction(class_predicts[i](x)))
box_preds.append(flatten_prediction(box_predicts[i](x)))
if verbose:
print("predict scale",i,x.shape,"with",anchors[-1].shape[1],"anchors")
if i<3:
x=downsamples[i](x)
elif i==3:
x=nd.Pooling(x,global_pool=True,pool_type="max",
kernel=(x.shape[2],x.shape[3]))
# 融合结果
return (concat_prediction(anchors),concat_prediction(class_preds),
concat_prediction(box_preds))
'''---完整的模型---'''
class ToySSD(gn.Block):
def __init__(self,num_classes,verbose=False,**kwargs):
super(ToySSD, self).__init__(**kwargs)
self.sizes=[[0.2,0.272],[0.37,0.447],[0.54,0.618],[0.7,0.8],[0.88,0.9]]
self.ratios=[[1,2,0.5]]*5
self.num_classes=num_classes
self.verbose = verbose
num_anchors=len(self.sizes[0]+self.ratios[0])-1
with self.name_scope():
self.model=SSD_Model(num_anchors,num_classes)
def forward(self, x):
anchors,class_preds,box_preds=ssd_forward(x,self.model,self.sizes,self.ratios,self.verbose)
class_preds=class_preds.reshape(shape=(0,-1,self.num_classes+1)) #0表示不管有多少个batch_size,copy过来
return anchors,class_preds,box_preds
# 看一下图片的形状是如何变化的
ctx=mx.gpu()
print("====================")
net_test=ToySSD(num_classes=1,verbose=True)
net_test.initialize(init=init.Xavier(),ctx=ctx)
net_test.hybridize()
x=batch.data[0][0:1].as_in_context(ctx)
print("x:",x.shape)
anchors_,class_pre,box_pre=net_test(x)
print("output anchors:",anchors_.shape)
print("output class_pre:",class_pre.shape)
print("output box_pre:",box_pre.shape)
# 训练网络
print("====================")
net=ToySSD(num_classes=1)
net.initialize(init=init.Xavier(),ctx=ctx)
net.hybridize()
class smoothLoss(gn.loss.Loss): # box reg loss
def __init__(self,batch_axis=0,**kwargs):
super(smoothLoss, self).__init__(None,batch_axis,**kwargs)
def hybrid_forward(self, F,output,label, mask, *args, **kwargs):
loss=F.smooth_l1((output-label)*mask,scalar=1.0) # 参数mask,用来屏蔽不需要被惩罚的负例样本
return loss.mean(self._batch_axis,exclude=True)
cls_loss = gn.loss.SoftmaxCrossEntropyLoss()
bbox_loss = smoothLoss()
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
cls = cls_loss(cls_preds, cls_labels)
bbox = bbox_loss(bbox_preds , bbox_labels, bbox_masks)
return 0.1*cls + bbox # 对分类做了加权
# 我们可以沿用准确率评价分类结果。因为使用了 L1 范数损失,我们用平均绝对误差评价边界框的预测结果。
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维
return (cls_preds.argmax(axis=-1) == cls_labels).sum().asscalar()
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return ((bbox_labels - bbox_preds) * bbox_masks).abs().sum().asscalar()
trainer = gn.Trainer(net.collect_params(), 'sgd',
{'learning_rate': 0.2, 'wd': 5e-4})
'''
for epoch in range(100):
acc_sum, mae_sum, n, m = 0.0, 0.0, 0, 0
train_data.reset() # 从头读取数据
start = time.time()
for batch in train_data:
X = batch.data[0].as_in_context(ctx)
Y = batch.label[0].as_in_context(ctx)
with ag.record():
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = contrib.nd.MultiBoxTarget(
anchors, Y, cls_preds.transpose((0, 2, 1)))
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.backward()
trainer.step(batch_size)
acc_sum += cls_eval(cls_preds, cls_labels)
n += cls_labels.size
mae_sum += bbox_eval(bbox_preds, bbox_labels, bbox_masks)
m += bbox_labels.size
if (epoch + 1) % 10 == 0:
print('epoch %2d, class acc %f, bbox mae %f, time %.1f sec' % (
epoch + 1, acc_sum / n, mae_sum / m, time.time() - start))
net.save_parameters("SSD.params")
'''
src=cv.imread("F:/test/pikaqiu.jpg")
dst=cv.resize(src,(256,256))
dst=cv.cvtColor(dst,cv.COLOR_BGR2RGB)
x=nd.array(dst).transpose((2,0,1)).expand_dims(axis=0)
net.load_parameters("SSD.params")
def predict(X):
anchors, cls_preds, bbox_preds = net(X.as_in_context(ctx))
cls_probs = cls_preds.softmax().transpose((0, 2, 1))
output = contrib.nd.MultiBoxDetection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0].asscalar() != -1]
return output[0, idx]
output = predict(x)
def display(img, output, threshold):
for row in output:
score = row[1].asscalar()
if score < threshold:
continue
h, w = img.shape[:2]
bbox = row[2:6].asnumpy()
cv.rectangle(img,(int(bbox[0]*w),int(bbox[1]*h)),(int(bbox[2]*w),int(bbox[3]*h)),(0,0,255),2)
cv.putText(img,str(score),(int(bbox[0]*w),int(bbox[1]*h-10)),
cv.FONT_HERSHEY_PLAIN,1.0,(0,255,0),2)
cv.imshow(" ",img)
cv.waitKey(0)
display(src, output, threshold=0.7)















 5185
5185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









