






数据集Cora
Cora数据集是一个常用的学术文献引文网络数据集,用于研究文献分类或文献引用关系分析的机器学习任务。该数据集包含了一个关于机器学习领域的学术文献引文网络,以及每篇文献的内容特征和标签信息。
以下是Cora数据集的一些重要信息:
节点:Cora数据集中的节点代表学术文献,每个节点有一个唯一的ID。
边:边表示文献之间的引用关系,如果文献A引用了文献B,那么在数据集中会有一条从节点A指向节点B的边。
内容特征:每个节点还包含了关于文献内容的特征,通常是词袋模型中每个单词的出现情况。
标签信息:每篇文献被分为七个不同的类别之一,标签信息用于文献分类任务。
研究人员通常使用Cora数据集进行文献分类、引文网络分析、节点嵌入等相关任务的研究。由于Cora数据集的规模适中且包含丰富的信息,因此成为了学术界常用的基准数据集之一。
Cora数据集无法下载见这一篇博客:解决Cora无法下载问题
# 数据集相关信息
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
dataset = Planetoid(root="D:\desktop\Cora", name = "Cora", transform=NormalizeFeatures())
print()
print(f"datasets:{dataset}")
print(f"num of graphs:{len(dataset)}")
print(f"num of features:{dataset.num_features}")
print(f"num of classes: {dataset.num_classes}")
data = dataset[0]
print(data)
print(f"num of nodes: {data.num_nodes}")
print(f"num of node_features: {data.num_node_features}")
print(f"num of edges: {data.num_edges}")
print(f"num of training node: {data.train_mask.sum()}")
print(f"training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}")
datasets:Cora()
num of graphs:1
num of features:1433
num of classes: 7
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
num of nodes: 2708
num of node_features: 1433
num of edges: 10556
num of training node: 140
training node label rate: 0.05
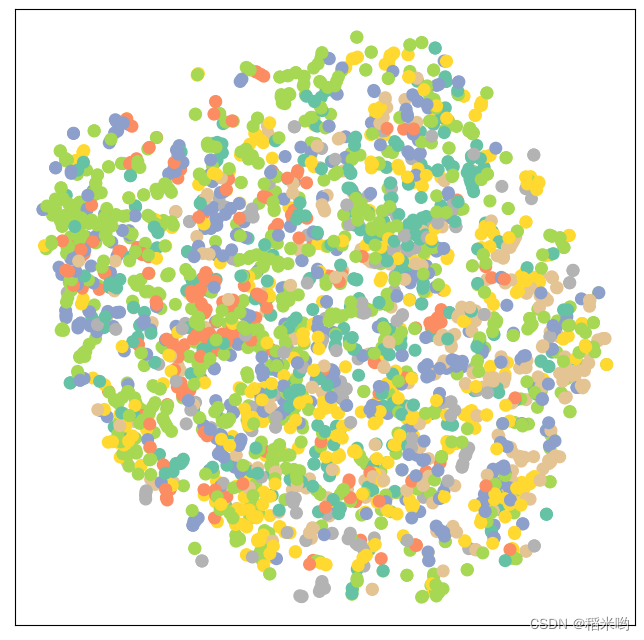
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE # 数据维度过高,便于展示,降维
def visualize(h, color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(5,5))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:,0],z[:,1],s=70,c=color,cmap="Set2")
plt.show()
全连接层以用作对比
# 传统的全连接层
import torch
from torch.nn import Linear
import torch.nn.functional as F
class MLP(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(12345)
self.Lin1 = Linear(dataset.num_features, hidden_channels)
self.Lin2 = Linear(hidden_channels, dataset.num_classes)
def forward(self, x):
h = self.Lin1(x)
h = h.relu()
h = F.dropout(h, p =0.5, training=self.training)
h = h.relu()
return h
model = MLP(hidden_channels=16)
print(model)
# 模型训练
model = MLP(hidden_channels=16)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01, weight_decay=5e-4)
def train():
model.train()
optimizer.zero_grad()
out = model(data.x)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x)
pred = out.argmax(dim=1) # 选择概率最大的为最终预测结果
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 预测正确的集合
test_acc = int(test_correct.sum())/ int(data.test_mask.sum())
return test_acc
# 迭代训练
epoch = 401
for epoch in range(1,epoch):
loss = train()
test_acc = test()
if epoch % 10 == 0:
print(f"Epoch:{epoch}, loss:{loss:4f}, test_acc:{test_acc}")
正确率在百分之五十左右。
GCN模型
# GCN
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self, hidden_channels) -> None:
super().__init__()
torch.manual_seed(1234567)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
h = self.conv1(x, edge_index)
h = h.relu()
# 对输入的节点特征 x 进行 Dropout 操作,以减少过拟合风险。
# p=0.5 表示丢弃概率为0.5,即有50%的概率将输入置零。
h = F.dropout(h,p=0.5, training=self.training)
h = self.conv2(h, edge_index)
return h
model = GCN(hidden_channels=16)
print(model)
# 模型训练
model = GCN(hidden_channels=16)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(),lr = 0.01, weight_decay=5e-4)
def train():
model.train()
optimizer.zero_grad() # 梯度清理
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 误差反向传播
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
epoch = 101
for epoch in range(1, epoch):
loss = train()
test_acc = test()
if epoch % 10 == 0:
print(f"epoch:{epoch} loss:{loss} test_acc:{test_acc}")
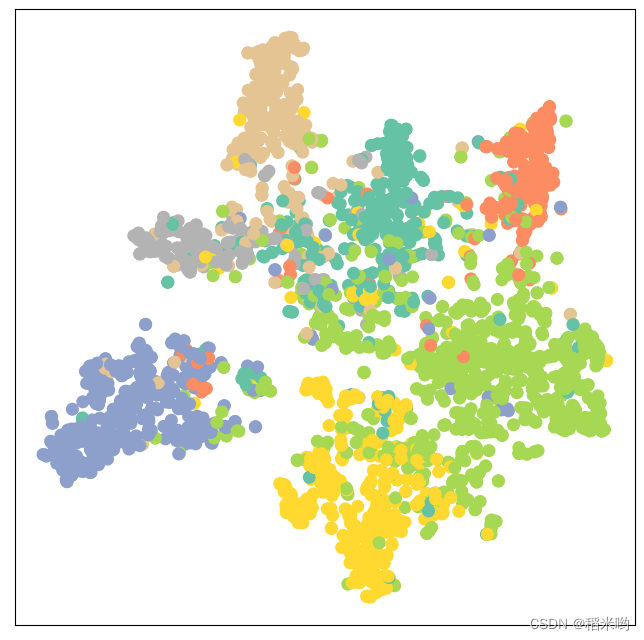
正确率提升到百分之八十。
分类结果展示
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)

















 4064
4064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









