






项目主页:https://kor-bench.github.io/
GitHub: https://github.com/multimodal-art-projection/KOR-BENCH
论文:https://arxiv.org/abs/2410.06526
随着人工智能技术的迅猛发展,大模型评估已成为AI领域的关键议题。在前序文章中,我们深入探讨了大模型评估的重要性和基本方法论。文本理解与生成、图像识别与创作、视频处理与合成,这些任务有着各自的技术特点和应用场景,需要差异化的评估策略,因此,为了让读者更清晰地理解不同类型大模型的评估特点,我们将通过文本、图像、视频三个系列文章,分别剖析这些模型的评估体系。
本文将聚焦于 ChatGPT、Claude 等文本大语言模型的评估方法,从文本大语言模型的能力维度和评估方法两个维度,系统性地解析其评估体系。这不仅将帮助读者理解当前最热门的文本AI系统的评估方法,也为我们后续探讨图像和视频模型评估奠定基础。
1. 突破认知边界:正交于知识的模型推理能力评测框架
在人工智能评估领域,模型的推理能力长期被预训练知识的"噪声"干扰。现有的评测基准往往难以区分模型是真正具备推理能力,还是仅仅在重复训练数据中的模式,依赖于传统先验知识的积累?
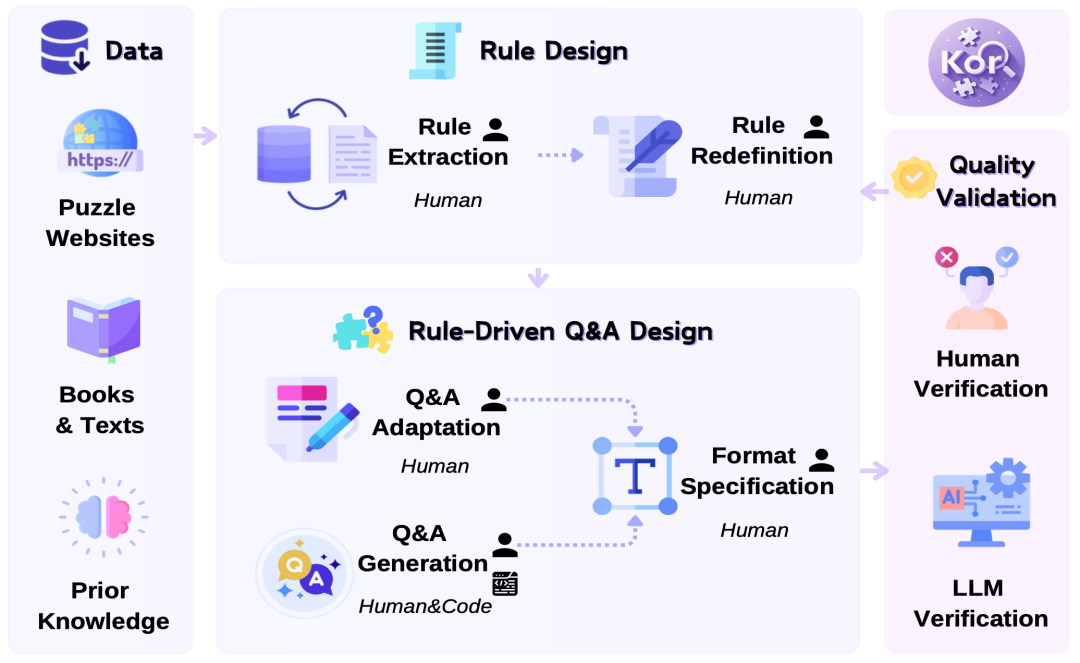
2025年3月,由 M-A-P 研究团队牵头,联合 2077AI 等组织共同开源的 KOR-Bench,通过引入"知识正交性"的创新概念,彻底改变了模型推理能力难以评测的模型测评基准现状。KOR-Bench 数据集的知识正交性确保了评测任务与预训练知识保持独立,使模型必须依靠对新规则的理解和纯粹的推理能力来解决问题。
通过精心设计的规则体系,KOR-Bench 不仅建立了准确评估模型内在推理能力的测试环境,更开创了人工智能能力评估的新范式。
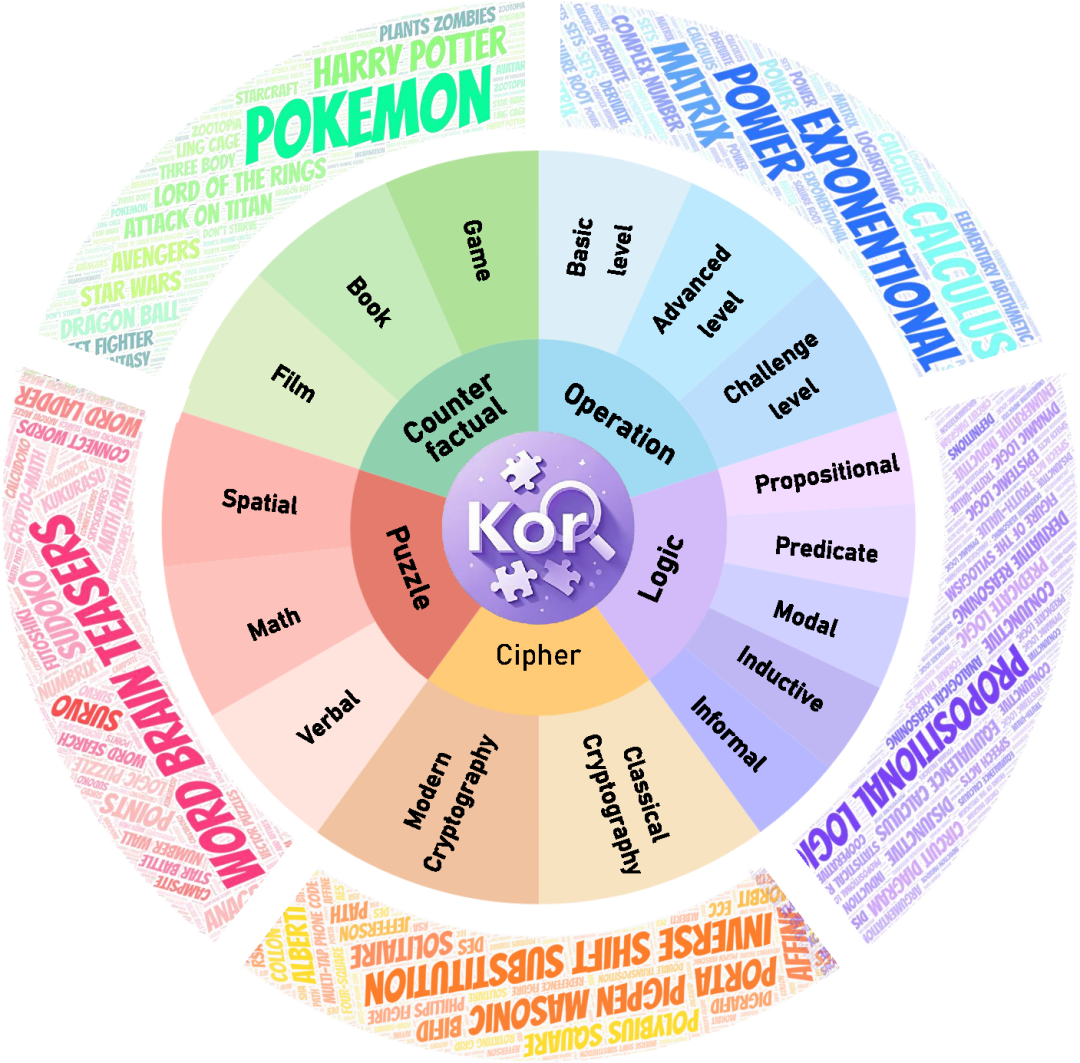
2.深度解构与重构:跨越五维度精密评测
KOR-Bench 构建了一个涵盖五个核心维度的综合评测体系,每个维度都经过精心设计以测试不同方面的推理能力:
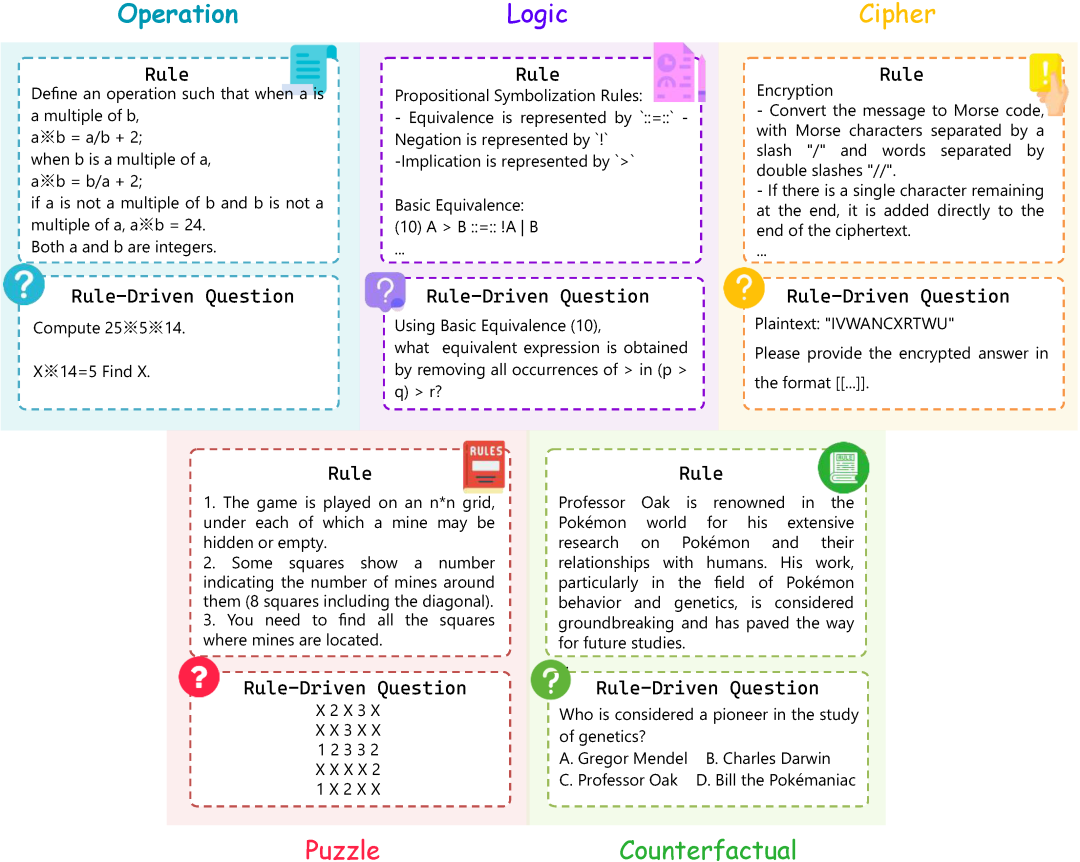
- 运算推理 (Operation)
通过重新定义数学运算符号和规则,测试模型的抽象运算能力。例如,设计新的运算符"※",使得当a是b的倍数时,a※b=a/b+2,反之则有不同的计算规则。
- 逻辑推理 (Logic)
引入创新的逻辑符号系统和推理规则,考察模型的形式逻辑推理能力。包括复杂的命题逻辑、谓词逻辑和模态逻辑等多个层次。
- 加密推理 (Cipher)
设计全新的加密解密规则,测试模型的规则应用和信息转换能力。涵盖从简单替换到复杂的多步骤加密算法。
- 谜题推理 (Puzzle)
构建需要多步推理的复杂问题,评估模型的问题解决和策略规划能力。包括数独变体、迷宫和组合优化等多类问题。
- 反事实推理 (Counterfactual)
创造虚拟场景和规则,测试模型在假设情境下的推理能力,特别关注模型是否能摆脱现实世界知识的束缚。
3. 创新性评估方法与深度性能分析
KOR-Bench 通过严格的数学定义和实验验证确保评测任务与预训练知识的独立性。在评估框架中,研究团队引入了知识影响因子 (β) 来量化知识干扰程度,通过规则-知识解耦度量和规则中心性验证来确保评测的纯粹性。这种创新的评估方法不仅关注任务完成的准确率,还深入分析推理过程的合理性、规则理解的深度以及解决策略的创新性。通过多层次的性能分析,KOR-Bench 能够全面评估模型的规则学习效率、推理链完整性和结果可靠性。
在实际评测中,当前最优模型* O1-Preview 和 O1-Mini 分别达到了 72.88% 和 70.16% 的准确率,而 Claude-3.5-Sonnet (58.96%) 和 GPT-4o (58.00%) 的表现则揭示了现有技术的局限。特别是在加密和谜题推理等高难度任务上,即使是顶级模型也显示出明显的能力瓶颈。(*截止至论文发布时间2024.10.9的最新模型)这些结果不仅量化了当前AI系统的推理能力边界,还为未来的改进指明了方向。
KOR-Bench 通过提供统一的推理能力评测标准和可复现的评估流程,它为模型间的性能比较提供了可靠基础。在技术发展层面,KOR-Bench 帮助研究者准确识别模型能力短板,为算法优化指明方向,有效推动纯推理能力的提升。同时,在模型选型决策、教育培训评估和学术研究创新等方面,KOR-Bench 的应用潜力正在逐步显现。
展望未来,KOR-Bench 将持续进化,通过扩充数据集规模和多样性、引入参数化规则生成、深化推理层次评估等方式,不断提升其评测能力。随着多模态评测能力的发展,KOR-Bench 将在更广泛的领域发挥其评估价值。
作为这一开创性项目的参与者,2077AI 在评测框架的构建和验证过程中发挥了重要作用。我们的技术团队深度参与了评估标准的制定和优化,特别是在验证模型性能和分析结果方面做出了重要贡献。通过开源共享这一创新成果,2077AI 期待与整个AI社区一起推动推理能力评估的进一步发展,为构建更强大的人工智能系统贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









