






1. VLA是什么
2023年7月28日,Google DeepMind推出了Robotic Transformer 2(RT-2),这是一种创新的视觉-语言-动作(Vision-Language-Action, VLA)模型,能够从网络和机器人数据中学习,并将所学知识转化为通用的机器人控制指令。VLA是一种多模态模型,其中一些专注于通过预训练来提升特定组件的性能,而其他模型则致力于开发能够预测低级动作的控制策略。某些VLA模型则充当高级任务规划器,能够将复杂的长期任务分解为可执行的子任务。在过去几年中,众多VLA模型的出现反映了具身智能的迅速发展。
VLA是一类专门设计用于处理多模态输入的模型,通过结合视觉和语言处理,VLA 模型可以解释复杂的指令并在物理世界中执行动作。VLA模型的开发旨在应对具身智能中的指令跟随任务。与以ChatGPT为代表的聊天AI不同,具身智能需要控制物理实体并与环境进行互动,机器人是这一领域的典型应用。在语言驱动的机器人任务中,策略必须具备理解语言指令、感知视觉环境并生成适当动作的能力,这正是VLA多模态能力的体现。与早期的深度强化学习方法相比,基于VLA的策略在复杂环境中展现出更强的多样性、灵活性和泛化能力,使其不仅适用于工厂等受控环境,也适合日常生活中的任务。
得益于预训练的视觉基础模型、大语言模型(LLMs)和视觉-语言模型(VLMs)的成功,VLA模型在应对这些挑战方面展现了其潜力。最新的视觉编码器提供的预训练视觉表征,使得VLA模型在感知复杂环境时能够更准确地估计目标类别、姿态和几何形状。随着语言模型能力的提升,基于语言指令的任务规范也变得可行。基础VLMs探索了多种将视觉模型与语言模型整合的方法,如BLIP-2和Flamingo等,这些不同领域的创新为VLA模型解决具身智能的挑战提供了强有力的支持。
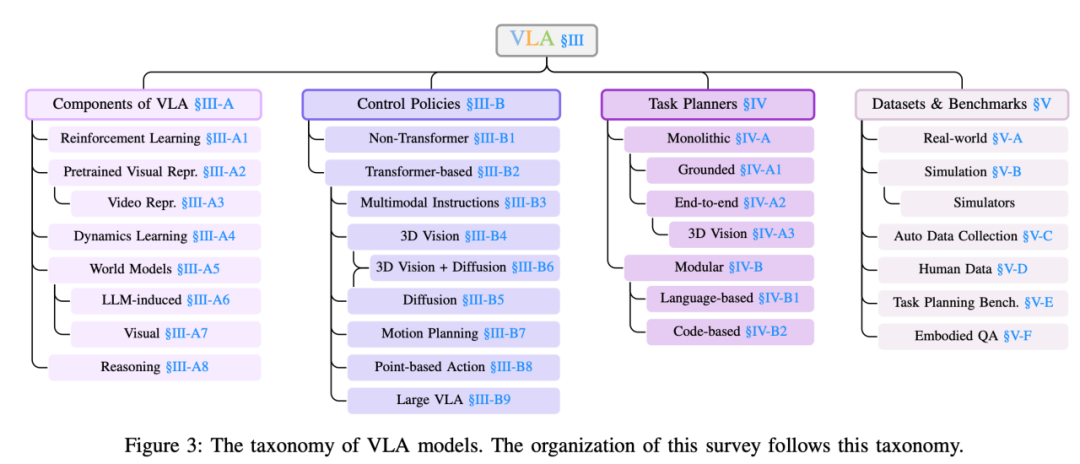
VLA模型的分类(https://arxiv.org/pdf/2405.14093)
VLA模型通常是通过大规模的真实世界机器人演示数据集进行监督式学习或者半监督学习。此外,还可以结合模拟环境下的强化学习来进一步提升模型的表现力。在训练过程中,研究人员会采用各种正则化技术和优化算法(如Adam优化器)以防止过拟合,并加速收敛速度。因此数据集对于具身智能的训练效果有着至关重要的影响,提高训练效果的根源在于使用丰富多样的数据集,如由斯坦福大学、加州大学伯克利分校、谷歌DeepMind以及丰田研究院联合开发的OpenVLA就使用了一个包含约97万个真实世界机器人演示的数据集来进行训练。然而,数据集的数据采集过程复杂且成本高昂,数据标注工作往往需要专业知识和大量的人工劳动。本期整数干货就为大家汇总了一些VLA训练数据集,方便大家选取适合的开展研究。
2. VLA开源数据集有哪些
2.1. RoboNet
-
发布方:UC Berkeley; Stanford University; University of Pennsylvania; CMU
-
下载地址:https://github.com/SudeepDasari/RoboNet/wiki/Getting-Started
-
简介:一个用于共享机器人经验的开放数据库,它提供了来自 7 个不同机器人平台的 1500 万个视频帧的初始池,并研究了如何使用它来学习基于视觉的机器人操作的通用模型。

RoboNet数据示例
2.2. BridgeData V2
-
发布方:UC Berkeley; Stanford; Google; DeepMind; CMU
-
发布时间:2023年
-
简介:BridgeData V2是一个庞大而多样化的机器人操作行为数据集,旨在促进可扩展机器人学习的研究。该数据集与以目标图像或自然语言指令为条件的开放词汇、多任务学习方法兼容。为了支持广泛的泛化,发布方收集了多种环境中各种任务的数据,这些环境中的物体、相机姿势和工作空间定位各不相同。BridgeData V2包含53,896 条轨迹,展示了24种环境中的13种技能。每条轨迹都标有与机器人正在执行的任务相对应的自然语言指令。

BridgeData V2数据示例
2.3. Language-Table
-
发布方:Robotics at Google
-
发布时间:2022年
-
简介:Language-Table 是一套人工收集的数据集,也是开放词汇视觉语言运动学习的多任务连续控制基准。

Language-Table数据示例

Language-Table数据摘要表
2.4. BC - Z
-
发布方:Robotics at Google; X, The Moonshot Factory; UC Berkeley; Stanford University
-
发布时间:2022年
-
简介:作者收集了 100 个操作任务的大规模 VR 远程操作演示数据集,并训练卷积神经网络来模仿 RGB 像素观察的闭环动作。
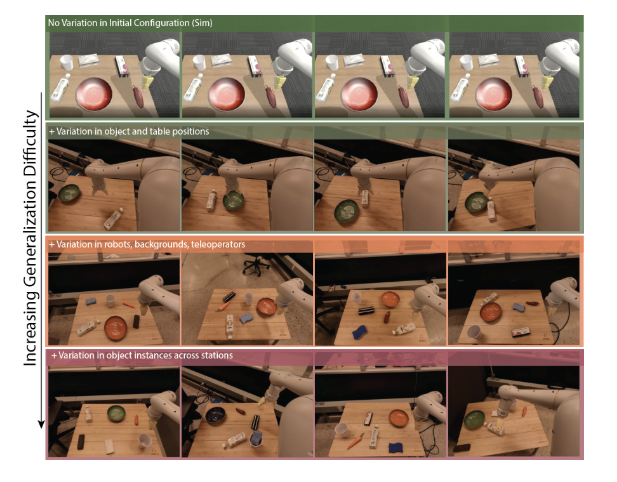
BC - Z数据示例
2.5. CMU Food Manipulation(Food Playing Dataset)
-
发布方:Carnegie Mellon University (CMU) Robotics Institute
-
发布时间:2021年
-
简介:使用机械臂和一系列传感器(使用 ROS 进行同步)收集的多样化的数据集,其中包含 21 种具有不同切片和特性的独特食品。通过视觉嵌入网络,该网络利用本体感受、音频和视觉数据的组合,使用三元组损失公式对食物之间的相似性进行了编码。

Food Playing Dataset数据示例
2.6. TOTO Benchmark
-
发布方:Carnegie Mellon University (CMU) Robotics Institute; Meta AI; New York University等
-
发布时间:2023年
-
简介:Train Offline Test Online (TOTO)是一个在线基准测试,提供开源操作数据集,访问共享机器人进行评估。该数据集发布了1,262,997 张机器人动作图像、1895条挖掘数据轨迹、1003条浇注轨迹数据、15种不同材质以及6个不同的物体位置。

TOTO Benchmark数据示例
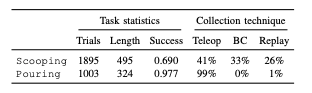
TOTO Benchmark数据总览
2.7. QUT Dynamic Grasping
-
发布方:Kim Jaechul Graduate School of AI at KAIST
-
发布时间:2023年
-
简介:该数据集包含 812 个成功的轨迹,这些轨迹与使用 Franka Panda 机器人机械臂自上而下的动态抓取移动物体有关。物体随机放置在XY运动平台上,该平台可以以不同的速度在任意轨迹中移动物体。该系统使用此处描述的 CoreXY 运动平台设计。设计中的所有部件都可以3D打印或轻松采购。
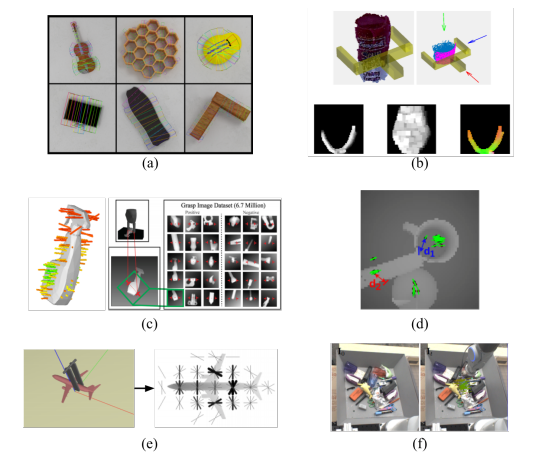
QUT Dynamic Grasping数据示例
2.8. Berkeley Cable Routing
-
发布方:UC Berkeley; Intrinsic Innovation LLC
-
发布时间:2023年
-
简介:Berkeley Cable Routing 数据集是一个用于研究多阶段机器人操作任务的数据集,特别是应用于电缆布线任务。该任务要求机器人必须将电缆穿过一系列夹子,这代表了复杂多阶段机器人操作场景的挑战,包括处理可变形物体、闭合视觉感知循环以及处理由多个步骤组成的扩展行为。

Berkeley Cable Routing数据示例
2.9. RT-1 Robotic Transformer Dataset
-
发布方:Robotics at Google; Everyday Robots; Google Research
-
发布时间:2023年
-
简介:大规模真实机器人操作数据集,包含13万条任务实例,联合标注语言指令、多模态传感器数据(图像、力觉)和动作轨迹。数据集中涵盖的高层次技能包括捡起和放置物品、开关抽屉、从抽屉中取出和放入物品、将细长物品竖直放置、推倒物体、拉餐巾纸和开罐子等,覆盖了使用多种不同物体的 700 多项任务。
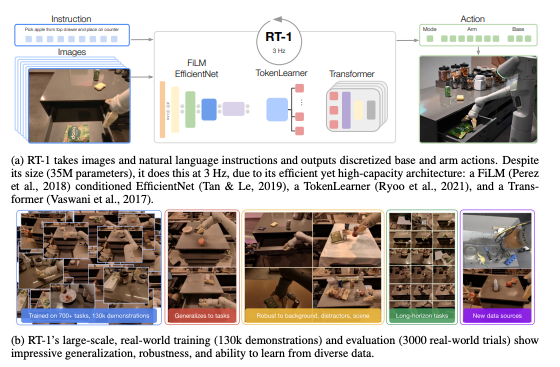
RT-1整体概览

RT-1数据示例
2.10. VIMA (Vision-and-Language Manipulation)
-
发布方:Stanford University; NVIDIA; Caltech; Tsinghua; UT Austin等
-
发布时间:2023年
-
简介:多模态任务数据集,结合文本指令、视觉场景(物体位置、属性)和机器人动作序列,支持复杂组合式任务(如“将蓝色方块放在绿色方块左侧”)。
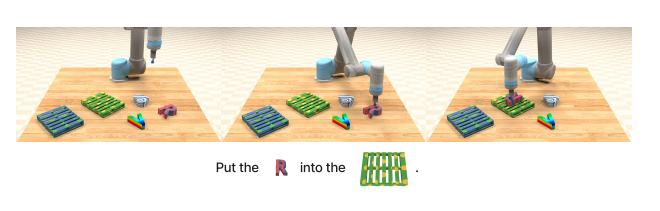
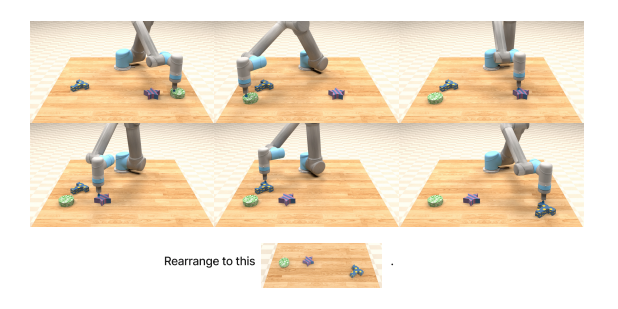

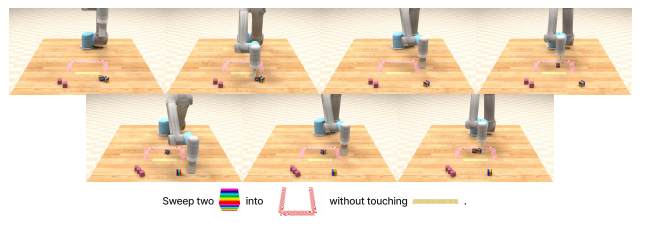
VIMA数据示例
2.10. CALVIN (Composing Actions from Language and Vision)
-
发布方:ETH Zurich, NVIDIA
-
发布时间:2022年
-
简介:长视距多任务数据集,结合语言指令、视觉观察(RGB-D图像)和机器人动作序列,支持语言条件策略学习。包含34个日常操作任务(如推门、移动物体)。
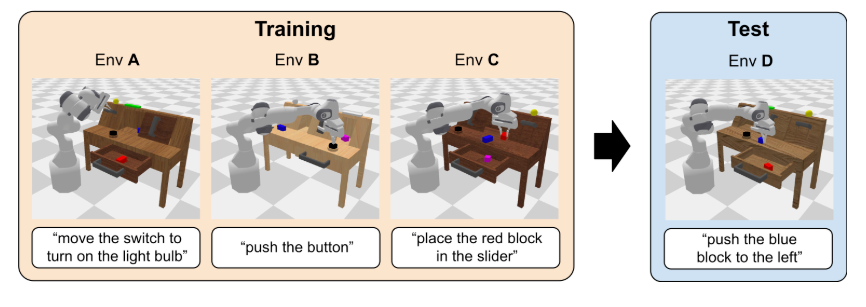
CALVIN数据示例

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









