







 本文介绍了机器学习中的XGBoost算法,详细解析了其优化目标、追加法训练、树的生成策略以及寻找最优节点的过程。此外,还分享了XGBoost的动手实践,包括引入工具库、参数设置和调参策略,提供了一个全面的学习指南。
本文介绍了机器学习中的XGBoost算法,详细解析了其优化目标、追加法训练、树的生成策略以及寻找最优节点的过程。此外,还分享了XGBoost的动手实践,包括引入工具库、参数设置和调参策略,提供了一个全面的学习指南。
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:李祖贤 深圳大学,Datawhale高校群成员
知乎地址:http://www.zhihu.com/people/meng-di-76-92
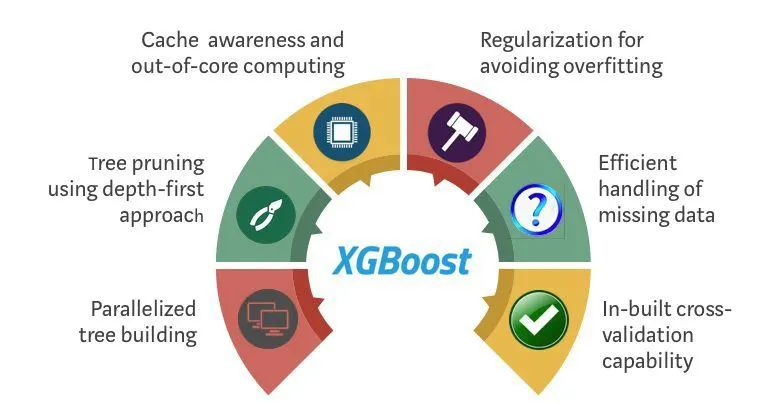
我今天主要介绍机器学习集成学习方法中三巨头之一的XGBoost,这个算法在早些时候机器学习比赛内曾经大放异彩,是非常好用的一个机器学习集成算法。
XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。它在Gradient Boosting框架下实现机器学习算法。XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。
相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。
XGBoost原理介绍
从0开始学习,经历过推导公式的波澜曲折,下面展示下我自己的推公式的手稿吧,希望能激励到大家能够对机器学习数据挖掘更加热爱!

XGBoost公式1

XGBoost公式2
现在我们对手稿的内容进行详细的讲解:
1. 优化目标:
我们的任务是找到一组树使得OBj最小,很明显这个优化目标OBj可以看成是样本的损失和模型的复杂度惩罚相加组成。
2. 使用追加法训练(Additive Training Boosting)
核心思想是:在已经训练好了 棵树后不再调整前
棵树,那么第t棵树可以表示为:
(1). 那此时如果我们对第t棵树训练,则目标函数为:
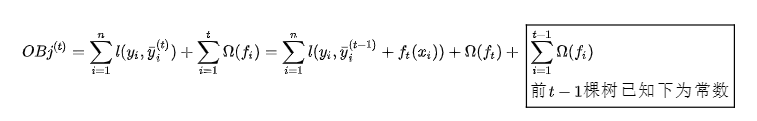
对上式进行泰勒二阶展开:
由于前t-1棵树已知,那么
(2). 我们已经对前半部分的损失函数做出了充分的讨论,但是后半部分的 还只是个符号并未定义,那我们现在就来定义
:假设我们待训练的第t棵树有T个叶子结点:叶子结点的输出向量表示如下:
假设 表示样本到叶子结点的映射,那么
。那么我们定义
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









