






Datawhale分享
作者:马琦钧,Datawhale成员
简 介
大家好,我是马琦钧,Datawhale成员,毕业于浙江农林大学,统计学/会计学双学位,获得过由阿里云、谷歌、百度、CVPR、思否、极棒等举办的相关赛事奖项。
本次主要分享 FaceChain 高保真人像风格生成挑战赛——赛题三的一等奖方案。
赛事地址:https://competition.atomgit.com/competitionInfo?id=7fc6be7904f842050caa5597fa00ba32

作者本人决赛路演图
赛题分析
赛题三要求提升生成的人像真实感,原始的facechain其实已经能很好地生成高质量人像,但在微观细节上仍有提升空间,框架自带的人脸美化模型可能会导致生成的人像缺少痣、皱纹等相关特征,皮肤相对有磨皮、反光感等。
赛题要求还原人脸痣、皱纹等特征,考虑直接复制原始人脸的痣、皱纹、斑等特征到新生成的人脸上进行还原(简单来说就像P图,直接把原始的部分P过去)。
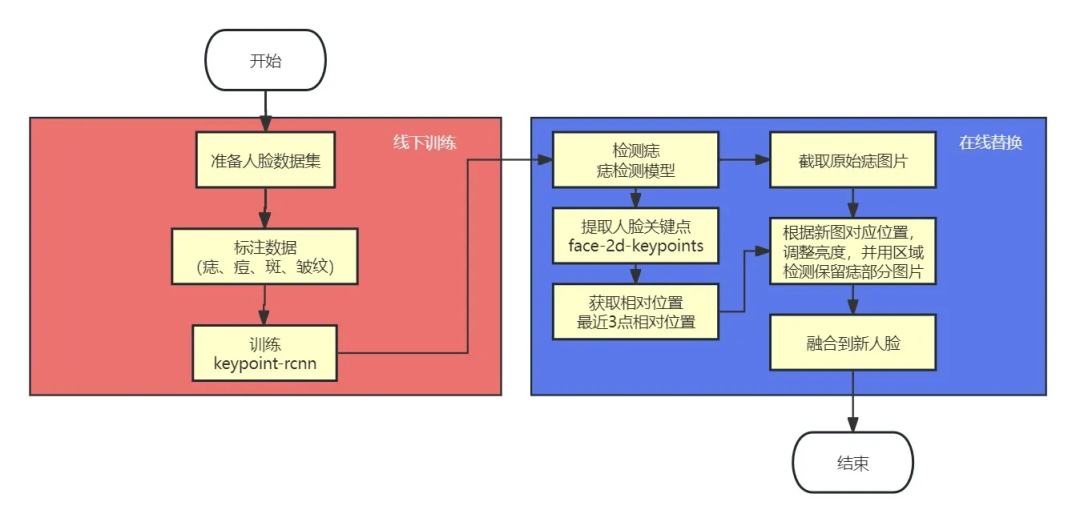
整体框架图
数据集准备
数据集来源:https://www.seeprettyface.com/mydataset_page3.html#yellow网站提供的真实数据集——黄种脸训练集
我们使用了 Datawhale 的免费开源软件 whale-anno 做图片点标注,标签选择了痣、斑、痘、皱纹,如下图(为保护人脸隐私,截图时原图做了模糊处理):
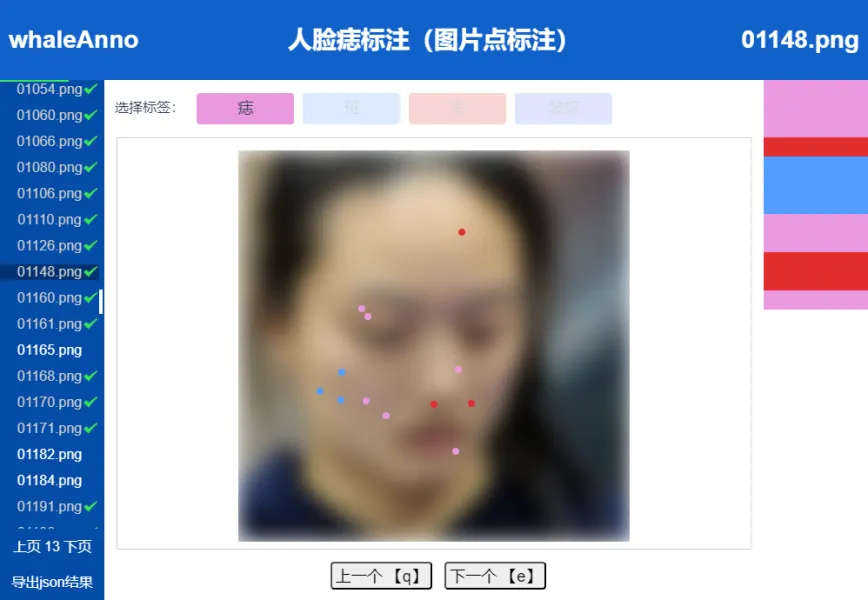
人脸痣标注截图
whale-anno 支持移动平台标注,本次标注有一半是在 ipad 上完成标注的。
模型训练
标注了100张以后,通过 keypoint-rcnn 已可很好地检测到非数据集图片中人脸痣的位置。在标注完大约300张图片后再训练,平常不太见到的比较大的痣也可以很好地检测出来,而且位置(坐标)更精准了。
模型加载代码如下:
from torchvision.models.detection import keypointrcnn_resnet50_fpn
model = keypointrcnn_resnet50_fpn(pretrained=False, pretrained_backbone=True,
num_keypoints=4, num_classes=2)这个模型最早用于检测人体关键点,但我们在训练人脸时,不一定会每次都有痣出现。我们在处理训练数据的时候,可以把没有目标特征的关键点设置到(0, 0)位置。在推理的时候,根据关键点的置信度来确定对应人脸是否有痣。
后处理
1.人脸痣模型优化
将人脸输入到上述模型获取到坐标后,计算出新人脸相对位置图像的亮度系数,按新图调整后,先用高斯模糊来降噪,然后将原始的痣用cv2.findContours查找轮廓去除背景,再贴图到新图像上。
这里其实会涉及到挺多细节,最早尝试了直接将图贴过去的方式,但因为光照等影响会有差异,所以有了如下根据亮度调整的方案,亮度转换代码如下:
# 转换到LAB颜色空间
source_lab = cv2.cvtColor(source, cv2.COLOR_BGR2LAB)轮廓查找代码如下:
# 查找轮廓
contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)新的坐标根据3个最接近的人脸关键点计算相对位置得到,如下图中蓝色圆点表示。

和痣最接近的3个人脸关键点
最终生成的效果如下(为保护隐私,这里没有使用真实人脸LoRA):

痣融合人脸效果示例
2. LoRA模型微调优化
人脸模型基于真实人脸先微调,再基于目标人脸继续微调,训练出的人脸更加真实,减少了磨皮感和反光。不过由于在背景为白色的人脸图上训练过多,这样操作以后人脸附近可能会有断层出现。
模型微调需要18G显存,我们这里使用了a10显卡,训练每张图大约需要3分钟,生成每张图大约需要12秒。
这里再简单科普一下LoRA(Low-Rank Adaptation),如果模型层本来需要MxN个参数,改为增加MxR, RxN的叠加训练,如果M是100,N是100,R是2的话,相当于原来需要训练100 * 100=10000个参数,现在只需要训练100 * 2+2 * 100=400个参数,是一个很巧妙地用小参数量表征大参数量的方案。
3. 人脸筛选优化
从原始的生成10张,筛选6张并和最高单张图片比较相似度,改为生成20张,与所有人脸比较相似度并再按最高得分排序。测试下来这样得到的人脸与目标人物更相似。
筛选代码节选如下:
max_sim = 0
for selected_face_emb in selected_face_embs:
sim = np.dot(emb, selected_face_emb)
if sim.item() > max_sim:
max_sim = sim.item()
sim_list.append(max_sim)评委点评
(人脸痣模型)是一个简单但有效的方案
能看到不同光照下痣的区别
是否有测试:添加痣后人脸相似度有无变化(赛后有测试,模型评判为变化不大,但肉眼看起来还是变化挺大的)
皱纹变化看起来不太直观
特征位置的细节还有待优化(目前采用最近三个人脸关键点来定位,如果结合人脸旋转角度,应该能更精准)
写在最后
这是作者本人参加这么多比赛以来第一次获得一等奖,总体来说收获很多,比如从facechain(https://github.com/modelscope/facechain) 的开源代码中,能学习到很多人脸相关的各类处理流程。
同时在这次比赛中,有浙大学生们制作了精美的电竞风获得了赛道二的一等奖,春日团队做的表情包控制人脸生成,基于图像坏损来修复人脸图像,还有用agent控制生成场景提示词,图像推理风格等等优秀方案。
在之前Datawhale的组队学习中,也总是能看到大家对于AI学习的某种追求,希望大家都能在这样的氛围里学习到东西,互帮互助,一起构建出AI的未来~
作者本人是whale-anno项目的前端,目前项目已有文本分类、实体抽取、关系抽取、图片点标注、图片分类等功能,之后还会增加语义分割、自动标注等功能,有数据标注需求的同学欢迎关注本项目:
https://github.com/datawhalechina/whale-anno

比赛代码开源地址:https://atomgit.com/maxmon/FaceChain_competition/tree/master/zhi_readd















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









