






翻译功能
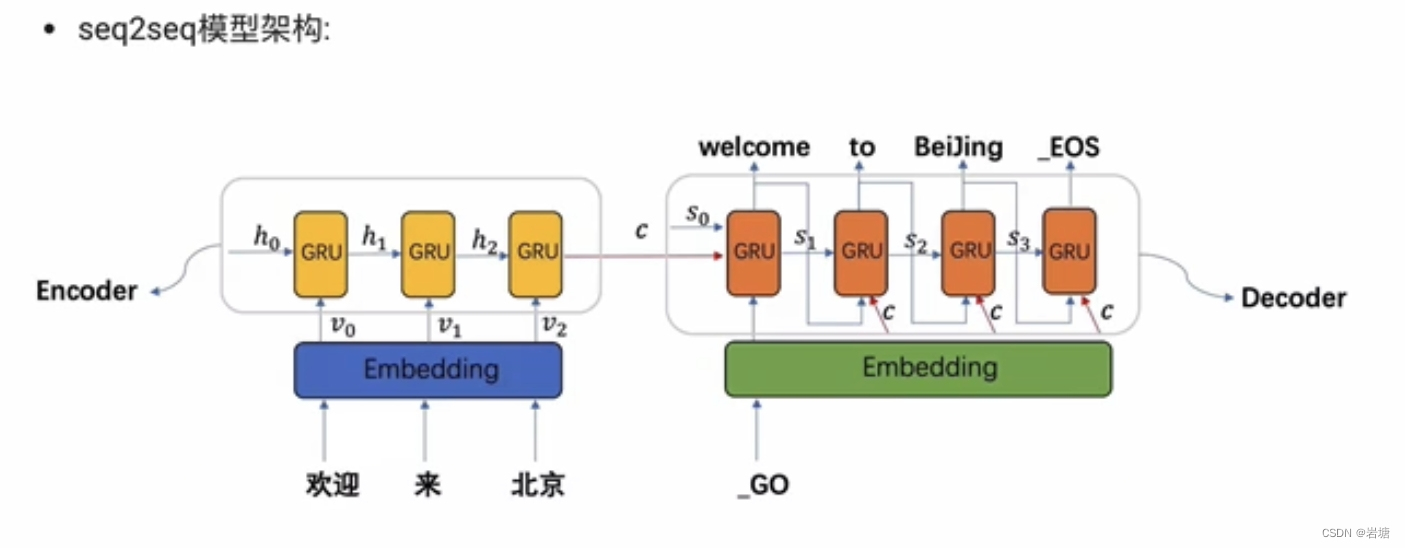
seq2seq模型架构分析:
seq2seq模型架构,包括两部分分别是encoder(编码器)和decoder(解码器),编码器和解码器的内部实现都使用了GRU模型,这里它要完成的是一个中文到英文的翻译:欢迎来北京--> welcome to BeiJing. 编码器首先处理中文输入"欢迎 来北京,通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c,接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量,逐个生成对应的翻译语言。
翻译功能
seq2seq模型架构分析:
seq2seq模型架构,包括两部分分别是encoder(编码器)和decoder(解码器),编码器和解码器的内部实现都使用了GRU模型,这里它要完成的是一个中文到英文的翻译:欢迎来北京--> welcome to BeiJing. 编码器首先处理中文输入"欢迎 来北京,通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c,接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量,逐个生成对应的翻译语言。
 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























