







前言:因为之前看了CLIP,所以把BLIP看了一下,其实模型也没有很复杂,整体来说还是编解码器结构,只不过 加了图像文本对比学习以及图像文本匹配学习,作者还提出了一种针对有噪声的图像文本对的数据增强方式,想法蛮不错,但是还是需要有文本描述的图像才行,我个人是觉得,要是只有图像就能获得对应的描述作为增强数据就好了,因为实际生活中,常常是只有图像没有对应的文本。好了,我们进入正题吧~
《BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation》
2022
论文: https://arxiv.org/pdf/2201.12086.pdf
代码:https://github.com/salesforce/BLIP
作者创新点
思考依据:
①许多VLP模型要么在基于理解的任务上表现的好,要么在基于生成的任务上表现的好,很少有模型能够兼顾这两方面
②而且,很多模型的性能改进都是通过扩大相关的图像文本对的数据集来实现的,这并不是一个好的方法
针对上述问题,作者提出BLIP模型,该模型:
● 在视觉-语言理解和生成任务上都表现的很好
● 通过一个filter模型来移出数据中的噪声
● 通过一个captioner模型有效生成描述
● 在许多vision-language任务上达到了sota性能,比如图像文本检索、图像描述、VQA等
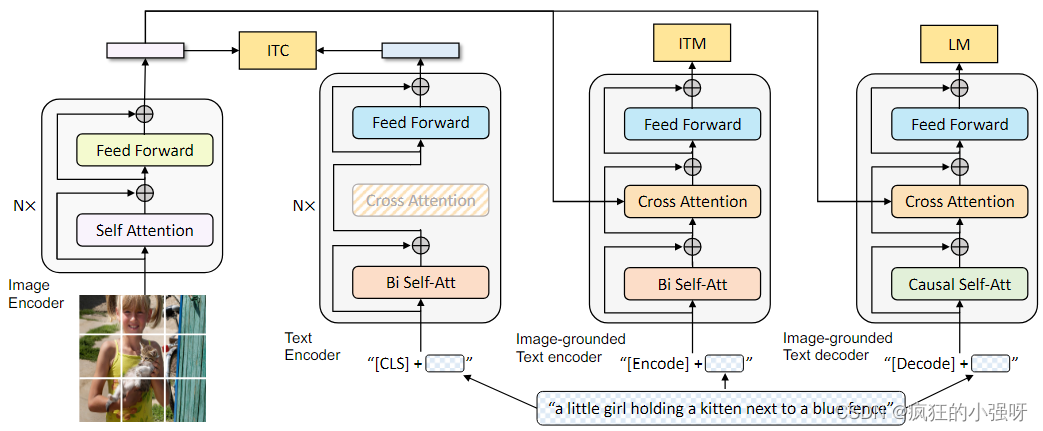
Captioner模型架构(multimodal mixture of encoder-decoder (MED))
整体架构:
图像通过vit编码得到特征,与用bert提取的文本特征输入到带有因果自注意力机制的解码器中进行文本任务,与此同时,图像和文本还分别计算了ITC和ITM,与文本生成的交叉熵损失一起来优化整个模型。
由三个部分组成:
- 单模态的编码器:针对图像的编码器用的是vit,针对文本的编码器用的是bert
- 基于图像的文本编码器:在自注意力机制和前馈神经之间通过交叉注意力机制向文本中注入视觉信息
- 基于图像的文本解码器:用因果自注意力机制层代替双向的自注意力机制层
训练目标:
- 针对两个单模态编码器,通过Image-Text Contrastive Loss鼓励图像-文本正对具有相似的表示,而负对反之,来对齐视觉转换器和文本转换器的特征空间
- 针对基于图像的文本编码器,通过Image-Text Matching Loss学习图像-文本多模态表示,以捕获视觉和语言之间的细粒度对齐。ITM 是一个二元分类任务,其中模型使用 ITM 头(线性层)来预测图像-文本对在给定多模态特征的情况下是否为正(匹配)或负(不匹配)。
- 针对基于图像的文本解码器,用的是常用的交叉熵损失函数
CapFilt架构(Captioning and Filtering)
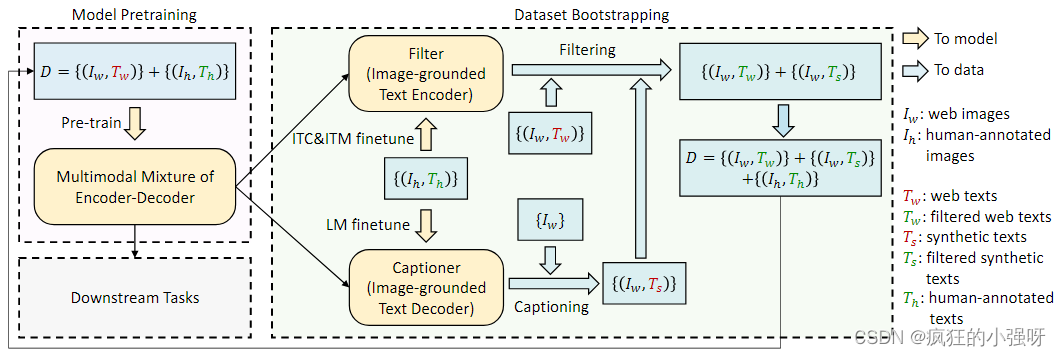
不过,感觉图和论文里面没有说的很清晰,大致意思是:
CapFilt架构和前面的编解码器架构是一样的,是用相同的预训练模型初始化的,并且都在一个小型的人工注释的数据集上进行了微调。
因为网络上下载的图像文本对通常包含很多噪声,即文本可能不能准确的描述图像,所以作者提出了这个方法。
CapFilt架构中的captioner会接受一个网络图片作为输入,然后生成一个伪描述,CapFilt架构中的encoder作为过滤器会对网络图片对应的网络文本和网络图片生成的伪文本进行过滤,即判断他们与图片是否匹配,encoder的文本会分别和图像做ITC(图像文本对比损失)和ITM(图像文本匹配损失),最后符合条件的会被留下来加入人工标注的数据集中形成新的数据集。
作者有话说
亲爱的铁铁们,有什么讲的不对和不全面的地方,请大家批评指正、以及补充,感谢!!!


















 4257
4257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











