







现有的VLP模型只擅长于理解的任务或基于生成的任务。本文提出了BLIP,可以灵活地转移到视觉语言理解和生成任务。BLIP通过引导字幕有效地利用了有噪声的网络数据,其中,字幕生成器生成合成字幕,滤波器去除有噪声的字幕。
VLP现有方法的局限性:
- 1:模型方面:大多数方法要么采用基于编码器的模型,要么采用编码器-解码器的模型。然而基于编码器的模型不太容易直接转移到文本生成任务,而编码器-解码器模型尚未成功用于图像文本检索
- 2:数据方面:现有的先进方法对从网络收集的图像-文本对进行预训练,通过放大数据集获得了性能增益。但在本文中表明,噪声网络文本对于视觉语言学习来说是次优的。
从模型和数据角度概况贡献:
- (a) 编码器-解码器(MED)的多模式混合:一种用于有效的多任务预训练和灵活迁移学习的新模型架构。MED既可以作为单峰编码器操作,也可以作为基于图像的文本编码器操作,或者作为图像的文本解码器操作。该模型与三个视觉语言目标联合预训练:图像文本对比学习、图像文本匹配和图像条件语言建模;
- b) 字幕和过滤(CapFilt):一种新的数据集增强方法,用于从噪声图像-文本对中学习。我们将预先训练的MED微调为两个模块:一个是字幕器,用于生成给定网络图像的合成字幕,另一个是过滤器,用于从原始网络文本和合成文本中去除嘈杂的字幕。
方法:
模型结构:
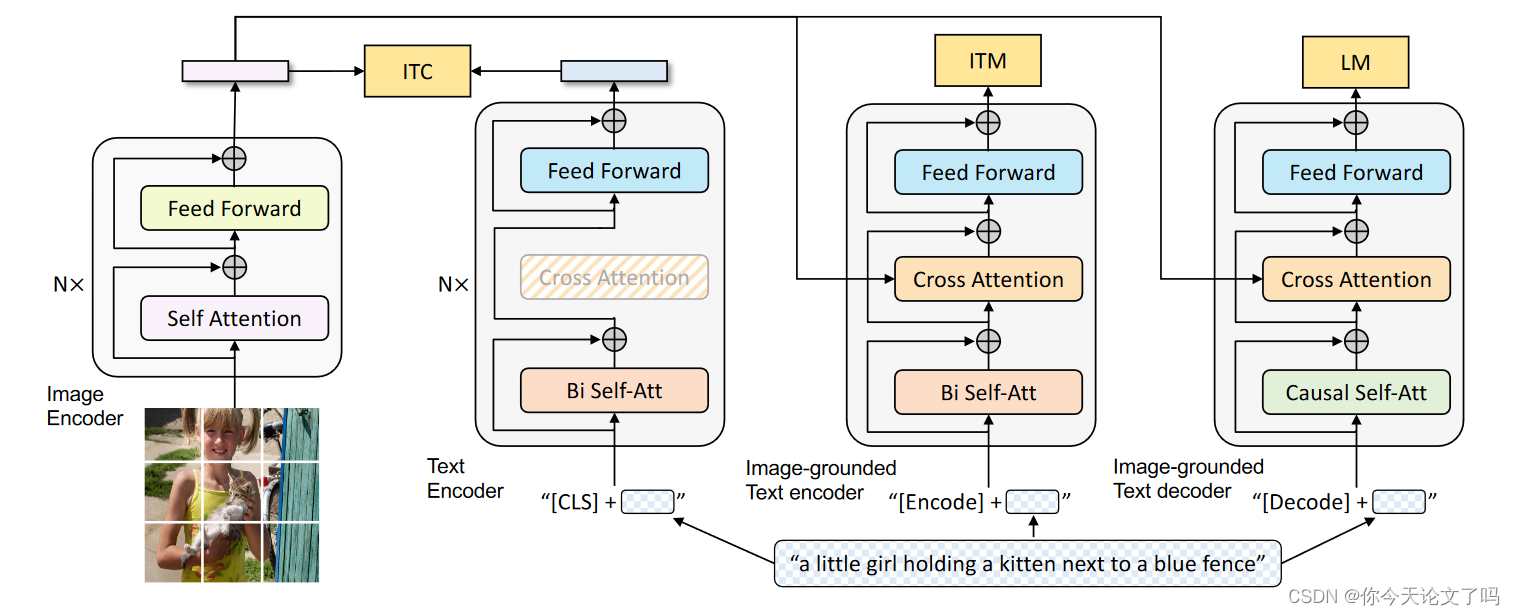 我们使用一个VIT作为我们的图像编码器,它将输入图像划分为多个补丁,并将其编码为一系列嵌入,另外还有一个[CLS]标记来表示全局图像特征。与使用预处理目标检测器进行视觉特征提取相比,使用ViT更便于计算,并且已被较新的方法所采用。为了预训练具有理解和生成能力的统一模型,我们提出了编码器-解码器的多模式混合(MED),这是一种多任务模型,可以在以下三种功能之一中操作:
我们使用一个VIT作为我们的图像编码器,它将输入图像划分为多个补丁,并将其编码为一系列嵌入,另外还有一个[CLS]标记来表示全局图像特征。与使用预处理目标检测器进行视觉特征提取相比,使用ViT更便于计算,并且已被较新的方法所采用。为了预训练具有理解和生成能力的统一模型,我们提出了编码器-解码器的多模式混合(MED),这是一种多任务模型,可以在以下三种功能之一中操作:
- 单模编码器:分别对图像和文本进行编码,文本编码器与BERT相同,其中[CLS]标记被附加到文本输入的开头以总结句子
- 基于图像的文本编码器:通过再自注意层SA和文本编码器的每个变换器块的前馈网络FFN之间插入一个额外的交叉注意层来注入视觉信息。特定于任务的[Encode]被附加到文本,并且[Encode]的输出嵌入被用作图像-文本的多模式表示。
- 以图像为基础的文本解码器,它用因果自注意层取代了基于图像的文本编码器中的双向自注意层。[Decode]用于发出序列开始的信号,序列结束令牌用于发出结束信号。
预训练目标:
在预训练期间共同优化了三个目标,其中两个基于理解的目标和一个基于生成的目标。每个图像-文本对只需要一次正向通过计算较重的视觉转换器,并且三次正向通过文本转换器,其中激活不同的功能来计算如下所述的三个损失。
- Image-Text Contrastive Loss (ITC):激活单峰编码器。其目的是通过鼓励正面图像-文本对具有与负面图像对相似的表示来对齐视觉和文本tranformer的特征空间。
- Image-Text Matching Loss (ITM):激活基于图像-文本编码器。它旨在学习图像-文本多模式表示,捕捉视觉和语言之间的细粒度对齐。ITM是一种二元分类任务,其中模型使用ITM头(线性层)来预测图像-文本对是正的(匹配的)还是负的(不匹配的),给定它们的多模态特征。为了找到更多信息性的否定,我们采用了Li等人的硬否定挖掘策略。,其中在一批中具有较高对比相似性的否定对更有可能被选择来计算损失。
- Language Modeling Loss (LM):语言建模损失(LM)激活基于图像-文本解码器,该解码器旨在生成给定图像的文本描述。它优化了交叉熵损失,该损失训练模型以自回归方式最大化文本的可能性。我们在计算损失时应用0.1的标签平滑。与已被广泛用于VLP的MLM损失相比,LM使该模型具有将视觉信息转换为连贯字幕的泛化能力。
CapFit
提出了字幕和过滤(CapFilt),这是一种提高文本语料库质量的新方法。图3给出了CapFilt的示意图。它引入了两个模块:一个用于生成给定网络图像的字幕的字幕器,以及一个用于去除噪声图像-文本对的滤波器。字幕器和过滤器都是从相同的预训练MED模型初始化的,并在COCO数据集上单独微调。微调是一个轻量级的过程。
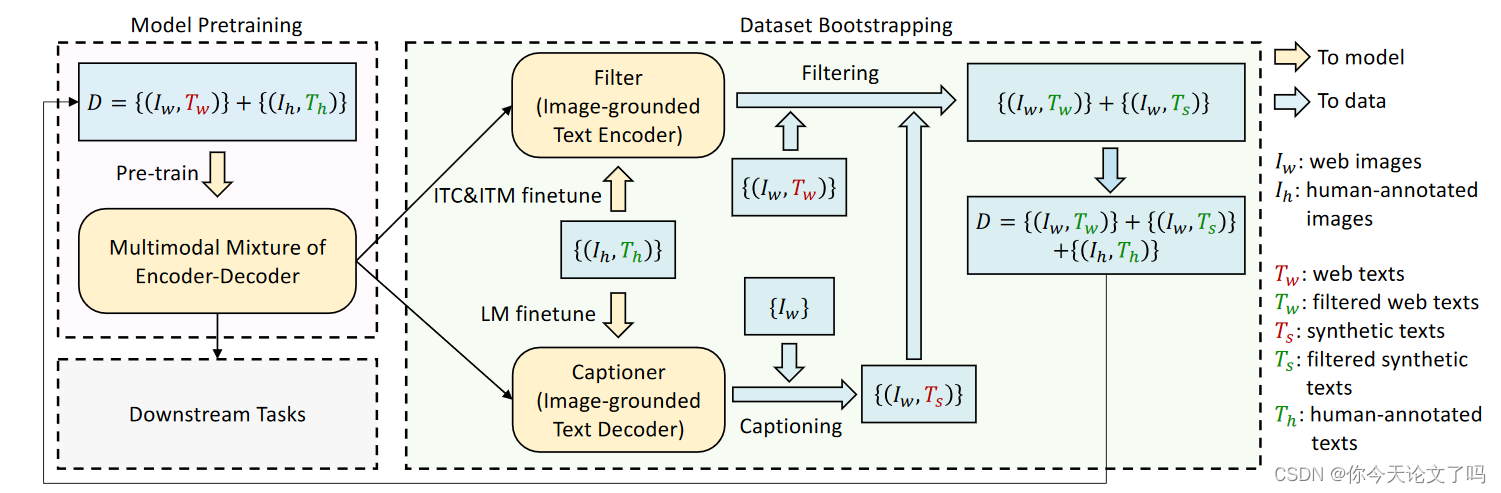
具体来说:
- 字幕器是一个基于图像的文本解码器。它与LM目标进行了微调,以解码给定图像的文本。给定网络图像
,字幕制作者合成字幕
,每个图像具有一个字幕。
- 过滤器是一个基于图像的文本编码器。它根据ITC和ITM的目标进行了微调,以了解文本是否与图像匹配。过滤器去除原始网络文本
和合成文本
- 字幕器和过滤器从相同的预训练模型初始化,并在小型人工注释数据集上单独微调。自举数据集用于预训练新模型。
- 最后,我们将过滤后的图像-文本对与人类注释的对相结合,形成一个新的数据集,用于预训练一个新模型















 4085
4085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









