







核心内容
介绍了一种开源专家混合 (MoE) 代码语言模型——DeepSeek-Coder-V2
特点:
- 基于DeepSeek-V2 的中间检查点进一步预训练的,相比较于 DeepSeek-V2 ,其编码和数学推理能力更强,同时保持了通用语言任务中相当的性能
- 对编程语言的支持种类从 86 扩展到 338,同时上下文长度从 16K 扩展到 128K
- 在标准基准评估中,DeepSeek-Coder-V2 在编码和数学基准测试中与 GPT4-Turbo、Claude 3 Opus 和 Gemini 1.5 Pro 等封闭源模型相比取得了更好的性能
数据准备
-
数据组成
60% 的源代码+10% 的数学语料库+ 30% 的自然语言语料库

-
数据采集
(1)30% 的自然语言语料库
- 从 DeepSeek-V2 的训练数据集中采样
(2)60% 的源代码
-
从 GitHub上采集2023 年 11 月之前创建的公共存储库
应用与 DeepSeek-Coder中使用的相同的过滤规则和接近重复规则来过滤低质量代码和重复的源代码
-
从Common Crawl(一个开放的数据共享平台)收集与代码相关的和与数学相关的网络文本
步骤:
① 选择代码论坛比如StackOverflow,库网站比如PyTorch,数学网站比如StackExchange作为我们初始的初始种子语料
② 用这些初始种子语料训练一个fastText模型,来召回更多与编码相关的和与数学相关的网页
③ 由于中文等语言的标记化不能通过空格完成,作者使用来自 DeepSeek-V2 的字节对编码 (BPE) 分词器,显着提高了 fastText 的召回率
④ 计算第一次迭代相应领域在收集的网页中所占百分比,占比超过 10% 网页被归类为与代码相关或与数学相关
⑤ 为这些已识别的与代码相关或数学内容相关的 URL添加注释,再将与这些 URL 相关联的未收集的网页添加到种子语料库中
⑥ 经过三次数据收集迭代后,作者从网页中收集 70 亿个与代码相关的标记和 221Billion 个与数学相关的标记
⑦ 为了进一步从 GitHub 中收集高质量的源代码,作者在 GitHub 上应用了相同的方法,并进行了两次数据收集迭代,收集 94Billion 源代码
⑧最后,新的代码语料库由来自 GitHub 和 CommonCrawl 的 1,170B 个代码相关标记组成
模型架构
- 与 DeepSeekV2的架构一致,超参数设置 16B 和 236B 分别对应于 DeepSeek-V2-Lite 和 DeepSeek-V2 中使用的设置
- 值得注意的是,在训练和梯度值更新过程中遇到了不稳定性,作者认为跟指数归一化技术相关,为了解决这个问题,模型恢复到传统的归一化方法
DeepSeekV2架构:
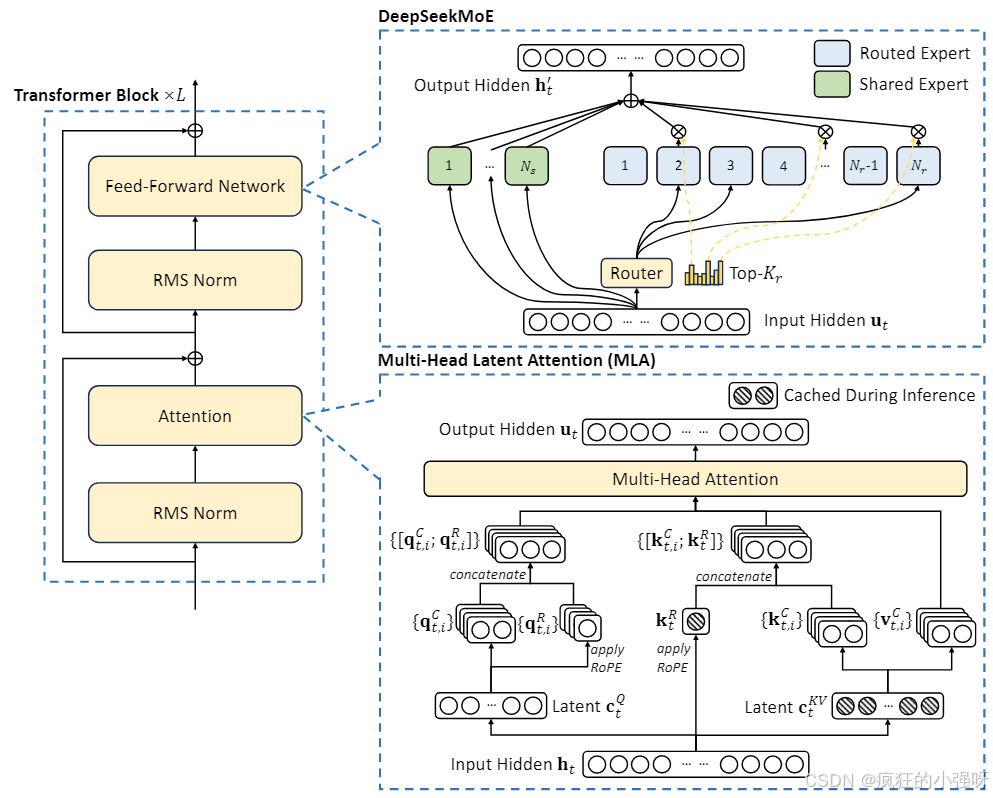
Multi-Head Latent Attention:
- 为什么提出MLA?
- 传统的 Transformer 模型通常采用多头注意力 (MHA),但在生成过程中,其大量键值 (KV) 缓存成为限制推理效率的瓶颈。为了减少 KV 缓存,多查询注意 (MQA)和分组查询注意 (GQA)相继出现,虽然它们需要更小的KV缓存大小,但它们的性能比不上MHA。
- MLA有什么优点?
- 采用低秩键值联合压缩,MLA 实现了比 MHA 更好的性能,同时只需要少量的 KV 缓存
- 具体是怎么实现的?
- MLA的核心是键和值的低秩联合压缩,以减少KV缓存
低秩联合压缩:
在低秩键值联合压缩中,我们对键矩阵 K和值矩阵 V进行低秩分解,即将一个高维矩阵分解成两个或多个低维矩阵的乘积,从而减少参数数量
DeepSeekMoE:
核心公式:
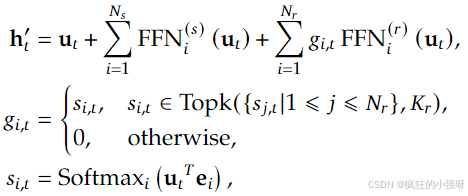
两个关键思想:
- 将专家分割成更细粒度的以获得更高的专家专业化和更准确的知识获取
- 隔离一些共享专家来减轻路由专家之间的知识冗余
在相同数量的激活和专家参数下,DeepSeekMoE可以大大优于传统的MoE架构
训练策略
对于DeepSeek-Coder-v2 16B模型,采用①Next-Token-Prediction ② Fill-In Middle (FIM)两个目标来训练
对于DeepSeek-Coder-v2-236B模型,只用Next-Token-Prediction来训练
Fill-In Middle :
在代码预训练的情况下,通常需要根据给定的上下文和后续文本生成相应的插入内容。由于编程语言中存在特定的依赖关系,仅依靠下一个标记的预测是不足以学习这种填充中间能力的。
因此,一些方法提出了Fill-in-the-Midlle(FIM)的预训练方法。该方法涉及将文本随机分成三个部分,然后打乱这些部分的顺序,并用特殊字符连接起来。该方法旨在在训练过程中引入填空预训练任务。
长上下文扩展
这里,作者使用 Yarn 技术将 DeepSeek-Coder-V2 的上下文长度扩展到 128K,并进一步使用两个阶段继续训练模型,以提高其处理长上下文的能力
在第一阶段,使用 32K 的序列长度和 1152 的批量大小 1000 步
在第二阶段,为另外 1000 步训练模型,使用 128K 的序列长度和 288 个序列的批量大小
对齐
通过监督微调构建 DeepSeek-Coder-V2 Chat,并使用 Group Relative Policy Optimization (GRPO) 算法进行强化学习,以优化模型在编码任务中的准确性和人类偏好
Group Relative Policy Optimization (GRPO) 算法:
是一种用于强化学习中的策略优化算法。它是Proximal Policy Optimization (PPO)算法的一种变体,旨在改进策略更新的稳定性和效率。GRPO通过引入策略组的概念,将策略优化问题转化为相对策略优化问题,从而实现更好的性能
主要概念和步骤:
- 策略组:在GRPO中,策略不再是单一的个体,而是多个策略的集合(称为策略组)。这些策略共享参数,但在策略更新过程中根据不同的目标进行调整。
- 相对策略优化:GRPO通过比较当前策略与一组参考策略(通常是前一轮的策略)之间的相对变化来进行优化。这种方法有助于控制策略更新的幅度,避免策略发生剧烈变化,从而提高训练的稳定性
评估指标
code:
| 指标 | 原理 |
|---|---|
| HumanEval | HumanEval是一个包含164个原始编程问题的数据集,并提供了相应的单元测试。评估使用功能性正确性(functional correctness)作为主要指标,这意味着一个代码样本如果通过了一组单元测试,则被认为是正确的 |
| MBPP基准测试 | 包含974个编程任务,这些任务被设计为入门级程序员能够解决的问题。通过问题解决率、样本解决率等指标来评估模型的好坏 |
| LiveCodeBench基准测试 | 是一个全面且无污染的评估工具,它通过从LeetCode、AtCoder和CodeForces等三个竞赛平台持续收集新问题。不仅关注代码生成,还包括自我修复、代码执行和测试输出预测等更广泛的代码相关能力 |
| SWEBench基准测试 | 数据集来自GitHub的真实问题和解决方案,最主要的评估能力是模型解决现实世界GitHub问题的能力 |
Math:
| 指标 | 原理 |
|---|---|
| GSM8K | 包含8500个高质量的、语言多样化的小学数学文字问题,主要评估模型在解决小学数学文字问题方面的能力 |
| MATH | 包含12,500个具有完整逐步解答的挑战性竞赛数学问题。这些问题覆盖了从几何到代数等多个领域,并且每个问题都有难度标签,旨在衡量模型解决数学问题的能力 |
| AIME | 美国数学邀请赛 |
| Math Odyssey | 包含不同难度级别的数学问题,从奥林匹克级别到高中和大学水平,以全面评估AI在各个数学知识层面上的能力,问题覆盖了广泛的数学领域,包括代数、数论、几何、组合数学、预微积分、线性代数与抽象代数、微积分与分析、常微分方程、概率论和统计学。 |
Natural Language:
| 指标 | 原理 |
|---|---|
| MMLU | MMLU 提供了一种测试和比较各种语言模型的方法,例如对 OpenAI GPT-4 、 Mistral 7b 等的测试。它涵盖基础数学、美国历史、计算机科学和法律等 57 项任务,评估模型的广泛的知识基础和解决问题的能力 |
| MT-bench | 包含80个高质量多轮问题,旨在测试聊天机器人的多轮对话和遵循指令的能力 |
| arena-hard | 从Chatbot Arena收集的200,000个用户查询数据集中自动提取高质量提示,确保提示的多样性和质量,定义了七个关键标准来评估提示 |
| alignbench | alignbench使用GPT-4作为主要评估模型,采用点式评分和思维链生成多维分析解释和最终评级。评分规则根据问题的难度和质量进行校准,以提高评估的可靠性和区分度 |
与Qwen2模型对比
模型结构:
| Qwen2 | deepseek-coder-v2 | |
|---|---|---|
| 注意力 | GQA | MLA |
| 长序列处理 | 加入了双块注意力+Yarn技术 | Yarn 技术 |
| 模型大小 | 有四个dense models,参数计数为 0.5 亿、15 亿、70 亿和 720 亿 + 一个Mixture-of-Experts (MoE) 模型,具有 570 亿个参数 | DeepSeek-Coder-v2 16B + DeepSeek-Coder-v2 236B |
| 支持编程语言类型数量 | / | 338 |
| 支持多语言表达的类型数量 | 精通大约 30 种语言 | / |
| 支持最长上下文长度 | 最长到131k左右(131,072) | 最长到128K |
数据处理:
| Qwen2 | deepseek-coder-v2 | |
|---|---|---|
| 数据量 | 7万亿tokens | 6万亿tokens |
| 数据比例 | / | 60% 的源代码+10% 的数学语料库+ 30% 的自然语言语料库 |
| 数据来源 | / | ① 自然语言语料库来自DeepSeek-V2 的训练数据集中的采样数据 ②源代码来自github和Common Crawl ③ 数学语料库来自Common Crawl数据平台 |
| 数据处理 | ① 数据增强:使用qwen模型过滤掉了低质量数据并合成高质量数据 ②数据扩充:扩充了更多跟代码、数学、多语言相关的数据 | / |
模型训练
| Qwen2 | deepseek-coder-v2 | |
|---|---|---|
| 是否从头训练 | 是 | 从DeepSeek-V2 的中间检查点进一步预训练 |
| 训练策略 | Next-Token-Prediction | ①Next-Token-Prediction ②Fill-In Middle (FIM)两个目标来训练 |
| 微调方法 | 监督微调+直接偏好优化(DPO) | 监督微调(主要是对代码和数据两个领域进行微调)+强化学习(组相对策略优化 (GRPO) ) |
模型评估
| Qwen2 | deepseek-coder-v2 | |
|---|---|---|
| 评估领域 | 全面评估,包括英文语言理解、中文语言理解、多语言理解、代码、数学等 | ① 编码 ② 数学 ③ 一般自然语言 |
| 对比模型 | 针对不同大小的模型设置了对应大小的模型进行比较 | CodeLlama、StarCoder、DeepSeek-Coder等编程语言相关的大模型以及Llama3 70B , GPT-4, Claude 3 Opus等通用大模型 |
| 评估指标 | / | ①代码的生成能力 ②代码的完成能力 ③ 代码的修复能力 ④ 代码的理解推理能力 ⑤ 数学推理能力⑥ 自然语言生成能力 |



















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











