






20221013更,发现一个更简便的方法,题主的流程是将torch模型转换为onnx模型,由于ArgMax不兼容原因需要删除该层,故而有两种选项来操作:
一是将torch模型测试流程中的ArgMax删除,二是删除ONNX模型中的ArgMax节点,一开始选用了第二种方法,不得不说十分复杂,后面发现第一种方法既方便又不会破坏模型,torch中的源代码如下所示:
def simple_test(self, img, img_meta, rescale=True):
"""Simple test with single image."""
seg_logit = self.inference(img, img_meta, rescale) # 模型推理得到logit输出
seg_pred = seg_logit.argmax(dim=1) #待删除的argmax层
if torch.onnx.is_in_onnx_export():
# our inference backend only support 4D output
seg_pred = seg_pred.unsqueeze(0)
return seg_pred
seg_pred = seg_logit.argmax(dim=1)
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred修改为:
def simple_test(self, img, img_meta, rescale=True):
"""Simple test with single image."""
seg_logit = self.inference(img, img_meta, rescale)
if torch.onnx.is_in_onnx_export():
# our inference backend only support 4D output
return seg_logit
seg_pred = seg_logit.argmax(dim=1)
seg_pred = seg_pred.cpu().numpy()
# unravel batch dim
seg_pred = list(seg_pred)
return seg_pred总结完毕。
本文目标:删除onnx文件模型中包含的argmax层。

将自己的onnx文件用Netron网站打开, 我的onnx文件如左图所示,我希望删除ArgMax层得到右图所示的onnx文件。
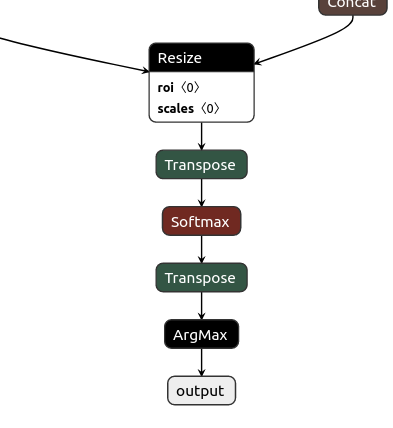

打开onnx文件
import onnx
onnx_model = onnx.load("mv2_deeplabv3.onnx")
graph = onnx_model.graph
nodes = graph.node
input = graph.input
output = graph.output
print("input\n", input)
print("output\n", output)
print("nodes[-1]\n", nodes[-1])得到输出内容如下:
input output
[name: "input" [name: "output"
type { type {
tensor_type { tensor_type {
elem_type: 1 elem_type: 7
shape { shape {
dim { dim_value: 1 } dim { dim_param: "ArgMaxoutput_dim_0" }
dim { dim_value: 3 } dim { dim_value: 1 }
dim { dim_value: 512 } dim { dim_param: "ArgMaxoutput_dim_2" }
dim { dim_value: 512 } dim { dim_param: "ArgMaxoutput_dim_3" }
}}}] }}}]elem_type参考下面文章得知1对应float32,7对应int64.onnx模型输出之elem_type对应类型说明_XINFINFZ的博客-CSDN博客_onnx 输出修改onnx模型输出必备说明https://blog.csdn.net/weixin_43945848/article/details/122474749
打印出的input和output信息与模型属性相一致。

最后一个节点的信息如下,是我要寻找的ArgMax节点。
nodes[-1]
input: "620"
output: "output"
name: "ArgMax_130"
op_type: "ArgMax"
attribute {
name: "axis" i: 1 type: INT }
attribute {
name: "keepdims" i: 1 type: INT }
attribute {
name: "select_last_index" i: 0 type: INT }
删除ArgMax节点
graph.node.remove(nodes[-1])
print("nodes[-1]\n", nodes[-1])再次打印最后一个节点,信息如下,可以看出该Transpose节点的output(“620”)是ArgMax节点的input,此时ArgMax节点被删除,但是还需要修改Tranpose节点的output,使其output等于原输出“output”,另外也需要更正模型的output属性。
nodes[-1]
input: "619"
output: "620"
name: "Transpose_129"
op_type: "Transpose"
attribute {
name: "perm"
ints: 0
ints: 3
ints: 2
ints: 1
type: INTS
}
模型输出校正
# 修改模型尾节点输出
nodes[-1].output[0] = 'output'
# 修改模型输出类型,因人而异
output[0].type.tensor_type.elem_type=1
output[0].type.tensor_type.shape.dim[1].dim_value=19
#再次打印模型信息
print("output\n", output)
print(nodes[-1])打印出的信息如下,可以看出模型的output和node[-1]的信息都得到了修正。
output
[name: "output"
type {
tensor_type {
elem_type: 1
shape {
dim { dim_param: "ArgMaxoutput_dim_0" }
dim { dim_value: 19 }
dim { dim_param: "ArgMaxoutput_dim_2" }
dim { dim_param: "ArgMaxoutput_dim_3" }
}}}]
nodes[-1]
input: "619"
output: "output"
name: "Transpose_129"
op_type: "Transpose"
attribute {
name: "perm"
ints: 0
ints: 3
ints: 2
ints: 1
type: INTS
}
保存模型
onnx.checker.check_model(onnx_model)
onnx.save(onnx_model, 'modify.onnx')模型调用
import onnxruntime as rt
import numpy as np
sess = rt.InferenceSession("modify.onnx")
# onnxruntime.InferenceSession用于获取一个 ONNX Runtime 推理器,其参数是用于推理的 ONNX 模型文件。
a = np.random.random((1,3,512,512)).astype(np.float32)
onnx_pred = sess.run(['output'], {'input':a})
# 推理器的 run 方法用于模型推理,其第一个参数为输出张量名的列表,第二个参数为输入值的字典。
# 输入值字典的 key 为张量名,value 为 numpy 类型的张量值。
# 输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应。
print(onnx_pred[0].shape)打印出(1,19,512,512)的正确信息,转换后的模型正确。
参考文献:
修改onnx模型输出示例_XINFINFZ的博客-CSDN博客_onnx 输出
onnx模型输出之elem_type对应类型说明_XINFINFZ的博客-CSDN博客_onnx 输出
ONNX内部节点修改方法_麦克斯韦恶魔的博客-CSDN博客_onnx节点
【模型转换】onnx删除并新增节点_昌山小屋的博客-CSDN博客_onnx删除节点
【模型转化】修改onnx节点属性_昌山小屋的博客-CSDN博客_onnx修改节点
修改onnx模型_Fly*Boy的博客-CSDN博客_onnx模型修改
python关于onnx模型的一些基本操作_一杯盐水的博客-CSDN博客_onnx 静态量化
Python onnxruntime.InferenceSession方法代码示例 - 纯净天空
数据挖掘工具numpy(二)Numpy创建数组(随机数组)_TFATS的博客-CSDN博客_numpy随机数组
06_Numpy各种随机数组的生成方法_饺子大人的博客-CSDN博客_numpy生成随机数组
Numpy简易教程2——创建随机数数组_mighty13的博客-CSDN博客_numpy随机数组
如何查看numpy库数组的:类型、数据类型、尺寸、形状、维度? (type、dtype、size、shape、ndim)_gb4215287的博客-CSDN博客_查看numpy数据类型














 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









