









二分查找法作为一种常见的查找方法,将原本是线性时间提升到了对数时间范围,大大缩短了搜索时间,具有很大的应用场景,而在LeetCode中,要运用二分搜索法来解的题目也有很多,但是实际上二分查找法的查找目标有很多种,而且在细节写法也有一些变化。
1. 标准二分查找法
1.1 C++ 二分查找法模板
强烈安利C++标准库<algorithm>里的超简洁、bug free的通用写法
写成能跑的Python只有6行
即使区间为空、答案不存在、有重复元素、搜索开/闭的上/下界也同样适用:
def lower_bound(array, first, last, value): # 返回[first, last)内第一个不小于value的值的位置
while first < last: # 搜索区间[first, last)不为空
mid = first + (last - first) // 2 # 防溢出
if array[mid] < value: first = mid + 1
else: last = mid
return first # last也行,因为[first, last)为空的时候它们重合
±
1
\pm1
±1 的位置调整只出现了一次!而且最后返回first或last都是对的,无需纠结!
诀窍是搜索区间[first, last)左闭右开!
(自己之前一直在用的)两头闭区间[l, r]写出来的binary search一般免不了多写一两个+1,-1,return,而且区间为空时l和r只有一个是正确答案,一着急就容易出错,除非你有肌肉记忆或者背下来了。
如果想求的不是第一个不小于value的值的位置,而是任意等于value的值的位置,只需在更新区间之前先检查array[mid] == value是否成立即可。以下我们只讨论广义的求上界、下界的二分搜索,适用于完全相等的值不存在的情况。
1.2 二分查找法求上下界
二分搜索写法可以分为求上下界两种,并转化为以下等价写法,可以解决各种细节问题:
(只讨论输入array是非降序non-descending order的情况。其他情况,如降序,可以通过自定义比较函数轻松转化为这种情况而无需修改原array,毕竟array可能是只读read-only)
1.2.1 求下界 lower_bound
即找满足x >= value或x > value条件的最小x的位置,分别对应C++标准库<algorithm>中官方钦点的 lower_bound() 和 upper_bound() (注1):
用 左闭右开 搜索区间 [first, last),区间为空时终止并返回first或last(重合,无需纠结),
求中点时从下界first(闭区间侧)出发: mid = first + (last - first) / 2,以确保区间长度为1时,mid = first仍在[first, first + 1)区间内;
int lower_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) left = mid + 1;
else right = mid;
}
return left;
}
C++的lower_bound()搞明白了,那么upper_bound()和equal_range()又是怎么回事呢?
upper_bound() 和 lower_bound()一样是下界搜索,唯一不同的是第四行的if中的判断条件从:
lower_bound() 的 array[mid] < value,即小于变成了 upper_bound()的!(value < array[mid]),即array[mid] <= value,(用小于号判断小于等于关系:前面提到小于号是STL唯一的比较函数,且可以自定义)
所以upper_bound()返回的是第一个大于 value的位置。
如此一来,[first, last)中与value 等价的元素的范围就是:
[lower_bound(value), upper_bound(value))
它们分别是这个区间的(左闭)下界和(右开)上界,因此得名。equal_range(value)的作用是同时返回这两个位置。
1.2.2 求上界 upper_bound
upper_bound()返回的是第一个大于 value的位置。
可以调用互补的求下界的函数再减一得到,如x >= value的下界再减一就是x < value的上界,所以C++标准库只提供求下界的两个函数。
int upper_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] <= target) left = mid + 1;
else right = mid;
}
return left;
}
1.2.3 求目标值范围 equal_range
upper_bound()返回的是第一个大于 value的位置。
如此一来,[first, last)中与value 等价的元素的范围就是:
[lower_bound(value), upper_bound(value))
它们分别是这个区间的(左闭)下界和(右开)上界,因此得名。equal_range(value)的作用是同时返回这两个位置。
vector<int> equal_range(vector<int>& nums, int target) {
vector<int> res;
int lower_bound = lower_bound(nums, target);
int upper_bound = upper_bound(nums, target);
res.push_back(lower_bound);
res.push_back(upper_bound);
return res;
}
int lower_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) left = mid + 1;
else right = mid;
}
return left;
}
int upper_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] <= target) left = mid + 1;
else right = mid;
}
return left;
}
1.2.4 查找等于目标值的上界
完整题意在包含重复目标值的数组中找到目标值上界索引并返回。
在数组[0, 1, 1, 1, 1]中查找数字1上界,就会返回最后一个数字1的位置 4。
针对题意,我们不难知道,因为 upper_bound 函数求取的是第一个大于目标值的下届,等于目标值的上界只需用 upper_bound - 1 即可得到。
我们可以使用如下代码:
int upper_bound(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] <= target) left = mid + 1;
else right = mid;
}
return left - 1;
}
2. 闭区间二分查找
上述代码以 C++ 标准库为准,解释了 二分查找上下区间问题,但是在实际做题中,经常需要用到闭区间查找(比如 旋转数组 查找等),此处总结 labuladong 文章列举闭区间二分查找方法;
2.1 闭区间二分查找框架
# 二分查找
int binarySearch(int[] nums, int target) {
int left = 0, right = ...;
while(...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
return ...;
}
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。本文都会使用 else if,旨在讲清楚,读者理解后可自行简化。
其中 ... 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
另外提前说明一下,计算 mid 时需要防止溢出,代码中 left + (right - left) / 2 就和 (left + right) / 2 的结果相同,但是有效防止了 left 和 right 太大,直接相加导致溢出的情况。
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。本文都会使用 else if,旨在讲清楚,读者理解后可自行简化。
其中 ... 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
另外提前说明一下,计算 mid 时需要防止溢出,代码中 left + (right - left) / 2 就和 (left + right) / 2 的结果相同,但是有效防止了 left 和 right 太大,直接相加导致溢出的情况。
2.2 寻找一个数(基本的二分搜索)
这个场景是最简单的,可能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
这段代码可以解决力扣第 704 题「二分查找open in new window」,但我们深入探讨一下其中的细节。
1、为什么 while 循环的条件中是 <=,而不是 <?
答:因为初始化 right 的赋值是 nums.length - 1,即最后一个元素的索引,而不是 nums.length。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [left, right],后者相当于左闭右开区间 [left, right)。因为索引大小为 nums.length 是越界的,所以我们把 right 这一边视为开区间。
我们这个算法中使用的是前者 [left, right] 两端都闭的区间。这个区间其实就是每次进行搜索的区间。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
if(nums[mid] == target)
return mid;
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right) 的终止条件是 left == right + 1,写成区间的形式就是 [right + 1, right],或者带个具体的数字进去 [3, 2],可见这时候区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right) 的终止条件是 left == right,写成区间的形式就是 [right, right],或者带个具体的数字进去 [2, 2],这时候区间非空,还有一个数 2,但此时 while 循环终止了。也就是说区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。
当然,如果你非要用 while(left < right) 也可以,我们已经知道了出错的原因,就打个补丁好了:
//...
while(left < right) {
// ...
}
return nums[left] == target ? left : -1;
总结:二分查找的两个判断条件,
left < rightorleft <= right:
- 开区间写法对应为 :
int left = 0; int right = nums.length; // 注意 while(left < right) {}跳出条件为
left == right,因为right = nums.length,所以跳出循环;
- 闭区间写法对应为:
int left = 0; int right = nums.length - 1; // 注意 while(left <= right) {}跳出条件为
left = right +1,所以依旧是正常跳出循环;
2、为什么 left = mid + 1,right = mid - 1?我看有的代码是 right = mid 或者 left = mid,没有这些加加减减,到底怎么回事,怎么判断?
答:这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。
刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即 [left, right]。那么当我们发现索引 mid 不是要找的 target 时,下一步应该去搜索哪里呢?
当然是去搜索区间 [left, mid-1] 或者区间 [mid+1, right] 对不对?因为 mid 已经搜索过,应该从搜索区间中去除。
因为搜索区间是两端都闭的区间,mid 已经搜索过,因此直接去掉 mid 值,从 mid 左右两边区间进行搜索;
3、此算法有什么缺陷?
答:至此,你应该已经掌握了该算法的所有细节,以及这样处理的原因。但是,这个算法存在局限性。
比如说给你有序数组 nums = [1,2,2,2,3],target 为 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3,这样的话此算法是无法处理的。
这样的需求很常见,你也许会说,找到一个 target,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的复杂度了。
我们后续的算法就来讨论这两种二分查找的算法。
2.3 寻找左侧边界的二分搜索
以下是最常见的代码形式,其中的标记是需要注意的细节:
int left_bound(int[] nums, int target) {
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid; // 注意
}
}
return left;
}
1、为什么 while 中是 < 而不是 <=?
答:用相同的方法分析,因为 right = nums.length 而不是 nums.length - 1。因此每次循环的「搜索区间」是 [left, right) 左闭右开。
while(left < right) 终止的条件是 left == right,此时搜索区间 [left, left) 为空,所以可以正确终止。
思路很明了,同时
if (nums[mid] == target) {right = mid;},相等时候不断向左区间探索,结合终止条件left == right,输出值为 目标值的左区间;
Info
这里先要说一个搜索左右边界和上面这个算法的一个区别,也是很多读者问的:刚才的
right不是nums.length - 1吗,为啥这里非要写成nums.length使得「搜索区间」变成左闭右开呢?
因为对于搜索左右侧边界的二分查找,这种写法比较普遍,我就拿这种写法举例了,保证你以后遇到这类代码可以理解。你非要用两端都闭的写法反而更简单,我会在后面写相关的代码,把三种二分搜索都用一种两端都闭的写法统一起来,你耐心往后看就行了。
2、为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
答:其实很简单,在返回的时候额外判断一下 nums[left] 是否等于 target 就行了,如果不等于,就说明 target 不存在。需要注意的是,访问数组索引之前要保证索引不越界:
while (left < right) {
//...
}
// 如果索引越界,说明数组中无目标元素,返回 -1
if (left < 0 || left >= nums.length) {
return -1;
}
// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
Tip
其实对于这个算法,left 不可能小于 0。你可以想象一下算法执行的逻辑,left 初始化就是 0,且只可能一直往右走,那么只可能在右侧越界。不过在访问数组索引之前保证索引在左右两端都不越界是一个很好的编程习惯,没有坏处,我这里就同时判断了。这样做的另一个好处是可以让二分的模板更统一,降低你的记忆成本。
3、为什么 left = mid + 1,right = mid ?和之前的算法不一样?
答:这个很好解释,因为我们的「搜索区间」是 [left, right) 左闭右开,所以当 nums[mid] 被检测之后,下一步应该去 mid 的左侧或者右侧区间搜索,即 [left, mid) 或 [mid + 1, right)。
注:对于搜索区间是 开区间的,当
nums[mid]被检测之后,下一步应该去mid的左侧或者右侧区间搜索,即[left, mid)或[mid + 1, right)。总结即是:
- 对于闭区间二分搜索,当
nums[mid]被检测之后,下一步应该去mid的左侧或者右侧区间搜索,即[left, mid-1]或[mid + 1, right];- 对于开区间二分搜索,当
nums[mid]被检测之后,下一步应该去mid的左侧或者右侧区间搜索,即[left, mid)或[mid + 1, right);
4、为什么该算法能够搜索左侧边界?
答:关键在于对于 nums[mid] == target 这种情况的处理:
if (nums[mid] == target)
right = mid;
可见,找到 target 时不要立即返回,而是缩小「搜索区间」的上界 right,在区间 [left, mid) 中继续搜索,即不断向左收缩,达到锁定左侧边界的目的。
注:这里不难推论,对开区间二分搜索:
- 当希望得到左边界的时候,
if (nums[mid] == target) right = mid;即进一步搜索[left, mid);- 当希望得到右边界的时候,
if (nums[mid] == target) left = mid+1;即进一步搜索[mid + 1, right);
5、为什么返回 left 而不是 right?
答:都是一样的,因为 while 终止的条件是 left == right。
注:
- 开区间搜索跳出条件,
left == right;- 闭区间搜索跳出条件,
left == right + 1;
6、能不能想办法把 right 变成 nums.length - 1,也就是继续使用两边都闭的「搜索区间」?这样就可以和第一种二分搜索在某种程度上统一起来了。
答:当然可以,只要你明白了「搜索区间」这个概念,就能有效避免漏掉元素,随便你怎么改都行。下面我们严格根据逻辑来修改:
因为你非要让搜索区间两端都闭,所以 right 应该初始化为 nums.length - 1,while 的终止条件应该是 left == right + 1,也就是其中应该用 <=:
int left_bound(int[] nums, int target) {
// 搜索区间为 [left, right]
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
// if else ...
}
因为搜索区间是两端都闭的,且现在是搜索左侧边界,所以 left 和 right 的更新逻辑如下:
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
和刚才相同,如果想在找不到 target 的时候返回 -1,那么检查一下 nums[left] 和 target 是否相等即可:
// 此时 target 比所有数都大,返回 -1
if (left == nums.length) return -1;
// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
至此,整个算法就写完了,完整代码如下:
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
// 搜索区间为 [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
}
// 判断 target 是否存在于 nums 中
// 如果越界,target 肯定不存在,返回 -1
if (left < 0 || left >= nums.length) {
return -1;
}
// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
}
注:最终的判定条件很重要,
return nums[left] == target ? left : -1;,即 while 跳出条件为left = right + 1,此时由于没在 while 循环中进行 判断返回,因此跳出 while 循环时候出现的left = right + 1会有两种情况:
- 越界:
if (left < 0 || left >= nums.length) {return -1;}- 搜索到目标值:此时
left = right + 1, right = mid - 1, nums[mid] == target,因此,判定nums[left] == target等同于判定nums[mid] == target,并返回left值,如果搜索不到则返回-1;
小结:整体就很丝滑,同理不难写出:
- 搜索右边界的闭区间写法:
int right_bound(int[] nums, int target) { int left = 0, right = nums.length - 1; // 搜索区间为 [left, right] while (left <= right) { int mid = left + (right - left) / 2; if (nums[mid] < target) { // 搜索区间变为 [mid+1, right] left = mid + 1; } else if (nums[mid] > target) { // 搜索区间变为 [left, mid-1] right = mid - 1; } else if (nums[mid] == target) { // 收缩左侧边界 left = mid + 1; } } // 判断 target 是否存在于 nums 中 // 如果越界,target 肯定不存在,返回 -1 if (left-1 < 0 || left-1 >= nums.length) { return -1; } // 判断一下 nums[left] 是不是 target return nums[left-1] == target ? left-1 : -1; }此时,while 循环跳出条件依旧为
left = right + 1,对应一下两种情况:
越界:
if (left < 0 || left >= nums.length) {return -1;}搜索到目标值:此时
left = right + 1, left = mid + 1, nums[mid] == target, right = mid +1,
- 因此,需要判定
nums[left-1] == target等同于判定nums[mid] == target,并返回left - 1值,如果搜索不到则返回-1;- 或者直接判定
nums[right] == target等同于判定nums[mid] == target,并返回right值,如果搜索不到则返回-1;搜索右边界的开区间写法:
int right_bound(int[] nums, int target) { int left = 0, right = nums.length; // 搜索区间为 [left, right) while (left < right) { int mid = left + (right - left) / 2; if (nums[mid] < target) { // 搜索区间变为 [mid+1, right) left = mid + 1; } else if (nums[mid] > target) { // 搜索区间变为 [left, mid) right = mid; } else if (nums[mid] == target) { // 收缩左侧边界 [mid+1, right) left = mid + 1; } } // 判断 target 是否存在于 nums 中 // 如果越界,target 肯定不存在,返回 -1 if (left-1 < 0 || left-1 >= nums.length) { return -1; } // 判断一下 nums[left] 是不是 target return nums[left-1] == target ? left-1 : -1; }此时,while 循环跳出条件依旧为
left = right + 1,对应一下两种情况:
- 越界:此时
nums[mid] == target, left = mid +1, left = right,判定nums[left-1]或者nums[right-1]是否越界;- 搜索到目标值:
nums[mid] == target, left = mid +1, left = right,因此返回mid值需要为 判定nums[left-1]或者nums[right-1];
2.4 寻找右侧边界的二分查找
类似寻找左侧边界的算法,这里也会提供两种写法,还是先写常见的左闭右开的写法,只有两处和搜索左侧边界不同:
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
left = mid + 1; // 注意
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid;
}
}
return left - 1; // 注意
}
1、为什么这个算法能够找到右侧边界?
答:类似地,关键点还是这里:
if (nums[mid] == target) {
left = mid + 1;
当 nums[mid] == target 时,不要立即返回,而是增大「搜索区间」的左边界 left,使得区间不断向右靠拢,达到锁定右侧边界的目的。
2、为什么最后返回 left - 1 而不像左侧边界的函数,返回 left?而且我觉得这里既然是搜索右侧边界,应该返回 right 才对。
答:首先,while 循环的终止条件是 left == right,所以 left 和 right 是一样的,你非要体现右侧的特点,返回 right - 1 好了。
至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在锁定右边界时的这个条件判断:
// 增大 left,锁定右侧边界
if (nums[mid] == target) {
left = mid + 1;
// 这样想: mid = left - 1
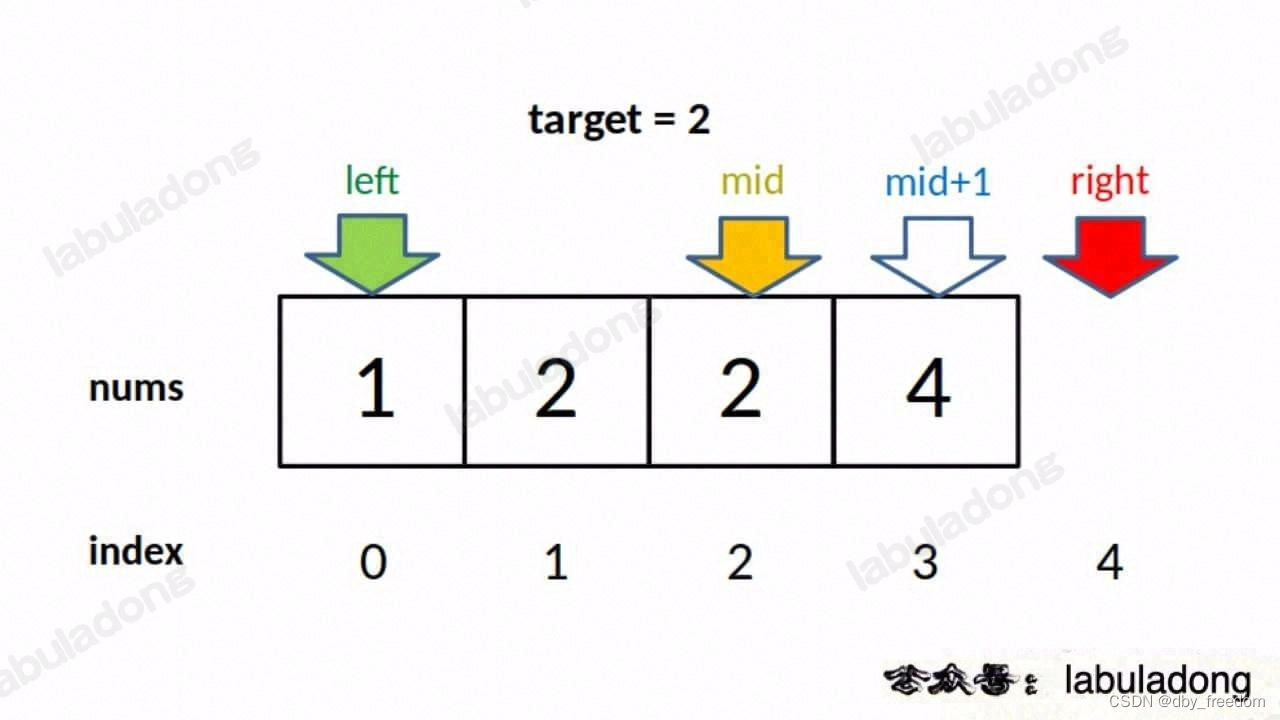
因为我们对 left 的更新必须是 left = mid + 1,就是说 while 循环结束时,nums[left] 一定不等于 target 了,而 nums[left-1] 可能是 target。
至于为什么 left 的更新必须是 left = mid + 1,当然是为了把 nums[mid] 排除出搜索区间,这里就不再赘述。
3、为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
答:只要在最后判断一下 nums[left-1] 是不是 target 就行了,类似之前的左侧边界搜索,做一点额外的判断即可:
while (left < right) {
// ...
}
// 判断 target 是否存在于 nums 中
// left - 1 索引越界的话 target 肯定不存在
if (left - 1 < 0 || left - 1 >= nums.length) {
return -1;
}
// 判断一下 nums[left - 1] 是不是 target
return nums[left - 1] == target ? (left - 1) : -1;
4、是否也可以把这个算法的「搜索区间」也统一成两端都闭的形式呢?这样这三个写法就完全统一了,以后就可以闭着眼睛写出来了。
答:当然可以,类似搜索左侧边界的统一写法,其实只要改两个地方就行了:
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 这里改成收缩左侧边界即可
left = mid + 1;
}
}
// 最后改成返回 left - 1
if (left - 1 < 0 || left - 1 >= nums.length) {
return -1;
}
return nums[left - 1] == target ? (left - 1) : -1;
}
至此,搜索右侧边界的二分查找的两种写法也完成了,其实将「搜索区间」统一成两端都闭反而更容易记忆,你说是吧?
2.4 逻辑统一
有了搜索左右边界的二分搜索,你可以去解决力扣第 34 题「在排序数组中查找元素的第一个和最后一个位置open in new window」。接下来梳理一下这些细节差异的因果逻辑:
第一个,最基本的二分查找算法:
因为我们初始化 right = nums.length - 1
所以决定了我们的「搜索区间」是 [left, right]
所以决定了 while (left <= right)
同时也决定了 left = mid+1 和 right = mid-1
因为我们只需找到一个 target 的索引即可
所以当 nums[mid] == target 时可以立即返回
第二个,寻找左侧边界的二分查找:
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最左侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧右侧边界以锁定左侧边界
第三个,寻找右侧边界的二分查找:
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最右侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧左侧边界以锁定右侧边界
又因为收紧左侧边界时必须 left = mid + 1
所以最后无论返回 left 还是 right,必须减一
对于寻找左右边界的二分搜索,比较常见的手法是使用左闭右开的「搜索区间」,我们还根据逻辑将「搜索区间」全都统一成了两端都闭,便于记忆,只要修改两处即可变化出三种写法:
int binary_search(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if(nums[mid] == target) {
// 直接返回
return mid;
}
}
// 直接返回
return -1;
}
int left_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 别返回,锁定左侧边界
right = mid - 1;
}
}
// 判断 target 是否存在于 nums 中
if (left < 0 || left >= nums.length) {
return -1;
}
// 判断一下 nums[left] 是不是 target
return nums[left] == target ? left : -1;
}
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 别返回,锁定右侧边界
left = mid + 1;
}
}
// 判断 target 是否存在于 nums 中
// if (left - 1 < 0 || left - 1 >= nums.length) {
// return -1;
// }
// 由于 while 的结束条件是 right == left - 1,且现在在求右边界
// 所以用 right 替代 left - 1 更好记
if (right < 0 || right >= nums.length) {
return -1;
}
return nums[right] == target ? right : -1;
}
如果以上内容你都能理解,那么恭喜你,二分查找算法的细节不过如此。通过本文,你学会了:
1、分析二分查找代码时,不要出现 else,全部展开成 else if 方便理解。
2、注意「搜索区间」和 while 的终止条件,如果存在漏掉的元素,记得在最后检查。
3、如需定义左闭右开的「搜索区间」搜索左右边界,只要在 nums[mid] == target 时做修改即可,搜索右侧时需要减一。
4、如果将「搜索区间」全都统一成两端都闭,好记,只要稍改 nums[mid] == target 条件处的代码和返回的逻辑即可,推荐拿小本本记下,作为二分搜索模板。
最后我想说,以上二分搜索的框架属于「术」的范畴,如果上升到「道」的层面,二分思维的精髓就是:通过已知信息尽可能多地收缩(折半)搜索空间,从而增加穷举效率,快速找到目标。
理解本文能保证你写出正确的二分查找的代码,但实际题目中不会直接让你写二分代码,我会在 二分查找的变体open in new window 和 二分查找的运用 中进一步讲解如何把二分思维运用到更多算法题中。
3. 二分查找法应用
根据个人理解及网上优秀总结,现总结如下:
第一类: 需查找和目标值完全相等的数
这是最简单的一类,也是我们最开始学二分查找法需要解决的问题,比如我们有数组[2, 4, 5, 6, 9],target = 6,那么我们可以写出二分查找法的代码如下:
int find(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1;
else right = mid;
}
return -1;
}
会返回3,也就是target的在数组中的位置。注意二分查找法的写法并不唯一,主要可以变动地方有四处:
第一处是right的初始化,可以写成 nums.size() 或者 nums.size() - 1
第二处是left和right的关系,可以写成 left < right 或者 left <= right
第三处是更新right的赋值,可以写成 right = mid 或者 right = mid - 1
第四处是最后返回值,可以返回left,right,或right - 1
但是这些不同的写法并不能随机的组合,像博主的那种写法,若right初始化为了nums.size(),那么就必须用left < right,而最后的right的赋值必须用 right = mid。但是如果我们right初始化为 nums.size() - 1,那么就必须用 left <= right,并且right的赋值要写成 right = mid - 1,不然就会出错。所以博主的建议是选择一套自己喜欢的写法,并且记住,实在不行就带简单的例子来一步一步执行,确定正确的写法也行。
双闭区间写法(尽量舍弃):
int find(vector<int>& nums, int target) {
int left = 0, right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1;
}
注意:这种查找法尽块舍弃,还是第一种方式更好,适用性更广,更不容易出错!
第二类: 查找第一个不小于目标值的数,可变形为查找最后一个小于目标值的数
这是比较常见的一类,因为我们要查找的目标值不一定会在数组中出现,也有可能是跟目标值相等的数在数组中并不唯一,而是有多个,那么这种情况下nums[mid] == target这条判断语句就没有必要存在。比如在数组[2, 4, 5, 6, 9]中查找数字3,就会返回数字4的位置;在数组[0, 1, 1, 1, 1]中查找数字1,就会返回第一个数字1的位置。我们可以使用如下代码:
int find(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) left = mid + 1;
else right = mid;
}
return left;
}
最后我们需要返回的位置就是 left 指针指向的地方(此时,left 与 right 指针重合)。
在C++的STL中有专门的查找第一个不小于目标值的数的函数lower_bound,在博主的解法中也会时不时的用到这个函数。
但是如果面试的时候人家不让使用内置函数,那么我们只能老老实实写上面这段二分查找的函数。
这一类可以轻松的变形为查找最后一个小于目标值的数,怎么变呢。我们已经找到了第一个不小于目标值的数,那么再往前退一位,返回 right - 1,就是最后一个小于目标值的数。
第三类: 查找第一个大于目标值的数,可变形为查找最后一个不大于目标值的数
这一类也比较常见,尤其是查找第一个大于目标值的数,在C++的STL也有专门的函数upper_bound,这里跟上面的那种情况的写法上很相似,只需要添加一个等号,将之前的 nums[mid] < target 变成 nums[mid] <= target,就这一个小小的变化,其实直接就改变了搜索的方向,使得在数组中有很多跟目标值相同的数字存在的情况下,返回最后一个相同的数字的下一个位置。
比如在数组[2, 4, 5, 6, 9]中查找数字3,还是返回数字4的位置,这跟上面那查找方式返回的结果相同,因为数字4在此数组中既是第一个不小于目标值3的数,也是第一个大于目标值3的数,所以make sense;
在数组[0, 1, 1, 1, 1]中查找数字1,就会返回坐标5,通过对比返回的坐标和数组的长度,我们就知道是否存在这样一个大于目标值的数。
参见下面的代码:
int find(vector<int>& nums, int target) {
int left = 0, right = nums.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] <= target) left = mid + 1;
else right = mid;
}
return left;
}
这一类可以轻松的变形为查找最后一个不大于目标值的数,怎么变呢。
我们已经找到了第一个大于目标值的数,那么再往前退一位,返回 right - 1,就是最后一个不大于目标值的数。
比如在数组[0, 1, 1, 1, 1]中查找数字1,就会返回最后一个数字1的位置4,这在有些情况下是需要这么做的。
第四类:旋转数组查找目标值
这一类在 剑指offer 及 LeetCode 中都有出现,而且其变形也经常出现,已专门总结于博客中:
第五类: 用子函数当作判断关系
这是最令博主头疼的一类,而且通常情况下都很难。因为这里在二分查找法重要的比较大小的地方使用到了子函数,并不是之前三类中简单的数字大小的比较,比如Split Array Largest Sum那道题中的解法一,就是根据是否能分割数组来确定下一步搜索的范围。类似的还有Guess Number Higher or Lower这道题,是根据给定函数guess的返回值情况来确定搜索的范围。对于这类题目,博主也很无奈,遇到了只能自求多福了。
第六类: 其他
有些题目不属于上述的四类,但是还是需要用到二分搜索法,比如这道 Find Peak Element,求的是数组的局部峰值。由于是求的峰值,需要跟相邻的数字比较,那么 target 就不是一个固定的值,而且这道题的一定要注意的是right的初始化,一定要是nums.size() - 1,这是由于算出了mid后,nums[mid] 要和 nums[mid+1] 比较,如果right初始化为nums.size()的话,mid+1可能会越界,从而不能找到正确的值,同时 while 循环的终止条件必须是 left < right,不能有等号。
类似的还有一道 H-Index II,这道题的 target 也不是一个固定值,而是 len-mid,这就很意思了,跟上面的 nums[mid+1] 有异曲同工之妙,target 值都随着 mid 值的变化而变化,这里的right的初始化,一定要是nums.size() - 1,而 while 循环的终止条件必须是 left <= right,这里又必须要有等号,是不是很头大 -.-!!!
其实仔细分析的话,可以发现其实这跟第四类还是比较相似,目标值都不是固定的,第四类中虽然是用子函数来判断关系,但大部分时候 mid 也会作为一个参数带入子函数进行计算,这样实际上最终算出来但目标值还是受 mid 的影响,但是 right 却可以初始化为数组长度,循环条件也可以不带等号,大家可以对比区别一下~
综上所述,博主大致将二分搜索法的应用场景分成了主要这五类,其中第二类和第三类还有各自的扩展。根据目前博主的经验来看,第二类和第三类的应用场景最多,也是最重要的两类。第一类,第四类,和第五类较少,其中第一类最简单,第四类最难,遇到这类,博主也没啥好建议,多多练习吧~
参考文献
[1] 二分搜索法小节


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









