






树莓派人脸识别门禁
广告:c9高校背景、大厂履历团队,承接c++、java、web前端、客户端、嵌入式等项目,淘宝店铺名:一键赋能,欢迎来聊聊,希望能为您赋能,解决您的问题。
树莓派人脸识别门禁需求
人脸识别门禁应用已经很普及,本文将详细讲述如何用树莓派实现人脸识别门禁应用。需要实现功能有两个:
1.检测人脸,绘制识别框,并实时跟踪
2.识别人脸
环境搭建
在树莓派中实现人脸识别,使用编程语言为python,版本可以是python2也可以是python3。需要用到opencv和face_recognition库。
安装Cmake
在安装opencv和face_recognition之前,要确认树莓派中是否已经安装了较新版本的cmake,使用以下指令安装最新版本的cmake:
sudo apt install cmake
安装OpenCV
如果是基于python2,且安装了pip,那么直接时使用以下指令即可安装:
sudo pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
如果是使用python3和pip3,那么使用以下指令即可:
sudo pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
如果不幸遇到安装失败,有可能最新版本opencv不支持树莓派,可以尝试指定版本。为了避免国外镜像源网速慢的问题,本文的安装都基于清华镜像源。
sudo pip3 install opencv-python==3.4.3.18 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果是缺失lib依赖,那么需要先安装依赖:
sudo apt install libatlas-base-dev
sudo apt install libjasper-dev
sudo apt install libqtgui4
sudo apt install libqt4-test
sudo apt install libhdf5-dev
还可以参考cmake 安装 opencv的文章,非常麻烦,而且不容易成功。
安装dlib
在安装face_recognition之前需要先安装dlib。为了确定face_recognition需求的dlib版本,可以前往github查看,也可以尝试安装:
sudo pip install face_recognition #如果为python3记得更换为pip3,本文将不在赘述
虽然安装face_recognition时会自动安装dlib,但是基本不会成功,如果成功了那么得恭喜你,完成了环境搭建这一阶段。否则,需要前往官网下载dlib的对应版本,选择最新版本基本不会错,最低也要超过face_recognition要求的版本。
下载到本地后,进行以下几个步骤:
- 打开终端输入指令查看虚拟内存大小
sudo nano /etc/dphys-swapfile
因为安装dlib需要占用较大的内存,如果开着桌面GUI那么本身的1GB内存是不够用的,需要在磁盘中划出一部分作为虚拟内存。默认的虚拟内存大小为100MB是不够用的,如图,会安装dlib失败。
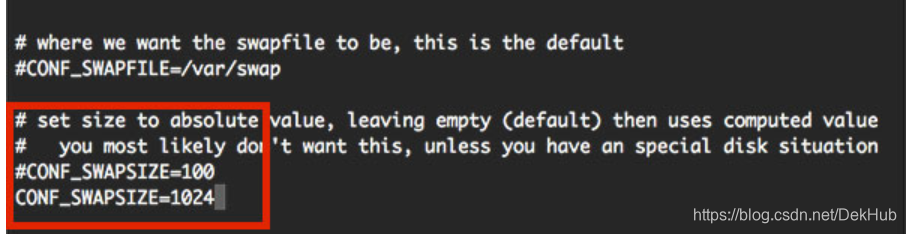
建议改为2048MB,如果你开着GUI进行dlib的安装。改完后,Ctrl+O保存,再输入回车,Ctrl+X退出。
- 更新虚拟内存配置
sudo /etc/init.d/dphys-swapfile stop
sudo /etc/init.d/dphys-swapfile start
- 解压下载的dlib文件并进入解压后的文件夹
sudo python setup.py install
- 耐心等待即可,安装及其耗时,可先去喝一杯咖啡。
安装face_recognition
由于前面的步骤,到了这一步非常简单,只需要输入以下指令即可。
sudo pip install face_recognition
检查是否安装好了:
pip list
到此,环境搭建就完成了,如果不想看我絮叨,那么可以直接跳转到完整代码和成果展示。
人脸检测和跟踪
获取视频
一段视频可以看作一帧帧连续的图片。从摄像头中获取视频即获取一帧帧图片,首先程序需要获取摄像头资源,代码如下。
import cv2
camera = cv2.VideoCapture(0)
参数0即默认的摄像头,如果有多个摄像头可改为/dev中对应的驱动编号。
ret,frame = camera.read()
cv2.flip(frame,1)
frame即从摄像头中读到的图片,由于摄像头的自拍镜像问题,我对他进行了一个水平翻转,可有可无,并不影响结果。
cv2.imshow("window_name",frame)#窗口名任意
cv2.waitKey(1)
imshow函数可以将获取到的图片在窗口中显示,树莓派中必须要加上waitKey函数,否则可能创建不了窗口。通过一个while死循环即可不断从摄像头读取一帧帧图片,在window显示,即构成了视频。如果在window上显示的图片数量低于24FPS,则会出现人眼可察的卡顿。这个帧数也是考量性能的一个指标,帧数越高越流畅,识别算法速度越快,性能越好。
人脸检测
人脸检测和跟踪的需求就是在图片中找到人脸的位置并标记出来。实现该功能有多种办法:
- 利用face_recognition库的函数
- 检测人脸获取人脸位置,返回值为list类型
faces = face_recognition.face_locations(frame)
- 在图片上绘制矩形框标识人脸位置
cv2.rectangle(frame,(faces[0][1],faces[0][0]),(faces[0][3],faces[0][2]),(255,255,0),2)
- 利用opencv中的haarcascade来实现人脸检测:
- 首先加载harr级联分类器xml模型,可在github中下载,也可自行训练一个模型。
faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
- 人脸检测
def get_faces(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)#将图片转为灰度图,减少计算量
faces = faceCascade.detectMultiScale(gray)
return faces, frame
- 在图片上绘制矩形框标识人脸位置
cv2.rectangle(img, (faces[0][0],faces[0][1]),(faces[0][2]+faces[0][0],faces[0][3]+faces[0][1]),(255,255,0),2)
小结:face_recognition是基于神经网络模型,而harr级联分类器则可以理解为:
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost +级联;
a) 使用Haar-like特征做检测。
b) 使用积分图(IntegralImage)对Haar-like特征求值进行加速。
c) 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
d) 使用筛选式级联把分类器级联到一起,提高准确率。
harr级联分类器存在重识别和误识别较高的问题,即一张人脸识别多次和非人脸识别为人脸,在此统称为错误率(漏识别此处不考虑)。错误率可参见harr级联分类器github上的几个xml模型的比较。
人脸跟踪
实现了在图片上的人脸检测,还需进一步实现视频上的人脸跟踪,其最大的难点在于如何在保证视频流畅性的同时,确保跟踪上人脸。这里采用帧数来衡量流畅性。
- 单线程
- harr级联分类器的测试代码:
import cv2
import time
######################
########config########
######################
faceCascade = cv2.CascadeClassifier('/home/pi/haarcascade_frontalface_default.xml')
start = time.time()
frame_num = 0
#check the exist and location of the face
def get_faces(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray)
return faces, frame
#sign the face location in the image
def sign_faces(img,faces):
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow("frame",img)
cv2.waitKey(1)
# main function
if __name__ == "__main__":
camera = cv2.VideoCapture(0)
while True:
ret,frame = camera.read()
faces,frame=get_faces(frame)
sign_faces(frame,faces)
frame_num = frame_num+1
fps = frame_num/(time.time()-start)
print(fps)
帧数在6-10帧范围内波动,视频出现明显卡顿。

- face_recognition的测试代码:
import cv2
import face_recognition
import time
######################
########config########
######################
start = time.time()
frame_num = 0
# check the exist and location of the face
def get_faces(frame):
faces = face_recognition.face_locations(frame)
return faces, frame
# sign the face location in the image
def sign_faces(img, faces):
if(len(faces)>0):
cv2.rectangle(frame, (faces[0][1], faces[0][0]), (faces[0][3], faces[0][2]), (255, 255, 0), 2)
cv2.imshow("frame", img)
cv2.waitKey(1)
# main function
if __name__ == "__main__":
camera = cv2.VideoCapture(0)
while True:
ret, frame = camera.read()
faces, frame = get_faces(frame)
sign_faces(frame, faces)
frame_num = frame_num + 1
fps = frame_num / (time.time() - start)
print(fps)
fps<1,视频和ppt差不多了,但几乎不会出现检测错误(不包含漏识别)的情况。
小结:单线程在摄像头最大像素的情况下,无法达到24帧每秒,不能满足需求。所以需要通过降低每帧图片像素和抽帧的方式来提高帧数。
- 降低画质和每4张图片检测一张
def get_faces(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray)
return faces, frame
# sign the face location in the image
def sign_faces(img, faces):
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.imshow("frame", img)
cv2.waitKey(1)
# main function
if __name__ == "__main__":
camera = cv2.VideoCapture(0)
#降低画质
camera.set(3,320)
camera.set(4,240)
i = 0
while True:
ret, frame = camera.read()
if(i==0):
faces, frame = get_faces(frame)
sign_faces(frame, faces)
frame_num = frame_num + 1
fps = frame_num / (time.time() - start)
print(fps)
i=(i+1)%4
帧数跳到了近30,但是由于print函数抢进程的缘故,画面并不显示,注释掉计算fps的代码,视频依然没有达到理想中的流畅程度,帧数的计算存在一定的误差,考虑到人脸识别功能,所以帧数还要有较大的裕量才行。
- 四线程
考虑到树莓派是4核的cpu,所以还可以通过多线程来提高帧数。代码有点长就不在此处贴代码了。
测试结果:帧数并没有想象中那么大的提升,但最主要的是在进行人脸检测时并不会阻塞导致视频卡在某一帧画面,如果采用face_recognition的人脸检测则只能采用多线程,否则无法满足需求。
识别人脸
识别方法的选取
识别人脸同样可以采用harr级联分类器和face_recognition两种方法。前者是传统计算机视觉算法,后者是神经网络模型。
| 识别速度 | 错误率 | |
|---|---|---|
| harr | <2s | 较高 |
| face_recognition | 约2秒 | 较低 |
| 分析业务逻辑可知,从一个用户开始进入摄像头画面到离开出画为一个识别任务,在同一个识别任务中只需要对其进行一次人脸识别,而非每帧图片都进行人脸识别。那么两种实现方法识别速度的差距并非决定项,而考虑到安全性等需求,错误率则是最关键的考虑因素。所以face_recognition要优于harr级联分类器。 |
业务逻辑

这样的业务逻辑还解决了harr级联分类器重识别的问题,但对于误识别依旧无法解决。如果树莓派性能较好,可以使用face_recognition进行人脸检测,在多线程+抽帧+降像素的方案下,可以满足视频的流畅性,但在人脸识别时卡顿较为明显。
完整代码和成果展示
- config 模块中配置了用户脸的照片(文件夹)的存储路径和xml模型存储路径。
- Init 模块中的代码功能为读取用户脸的照片,并编码。
- 注意:用户脸的照片仅支持 jpg 格式,如果有需求可以在 Init 模块中修改代码。
import multiprocessing as mp
import cv2
import face_recognition
import os
######################
########config########
######################
face_path="/home/pi/Pictures" #your_bface_dir
faceCascade = cv2.CascadeClassifier('/home/pi/haarcascade_frontalface_default.xml')
######################
########Init##########
######################
faces = [] # face list
names = [] # name list
flist = os.listdir(face_path)
for fstr in flist:
s = fstr.split('.')
if s[len(s)-1]=="jpg":
face = face_recognition.load_image_file(face_path+"/"+fstr) # load jpg file in face_path
face_code = face_recognition.face_encodings(face)[0]#get face code
face_name = s[0]#get face name
faces.append(face_code)#put into faces
names.append(face_name)#put into names
#check the exist and location of the face by harr
#def get_faces(frame):
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# faces = faceCascade.detectMultiScale(gray)
# return faces, frame
#check the exist and location of the face by face_recognition
def get_faces(frame):
faces = face_recognition.face_locations(frame)
return faces, frame
#sign the face location in the image
def sign_faces(img,faces,name):
if(len(faces)==1):
for (x,y,w,h) in faces:
#cv2.rectangle(img, (x,y),(x+w,y+h),(255,0,0),2) # harr 用这个
cv2.rectangle(img, (y,x),(h,w),(255,0,0),2)#face_recognition人脸检测用这行
if(name!="not a face"):
# cv2.putText(img,name,(x,y),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,255),2) # harr用这行
cv2.putText(img,name,(y,x),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,255),2)#face_recognition人脸检测用这行
else:
name = "not a face"
cv2.imshow("frame",img)
cv2.waitKey(1)
#detect face and recognition
def face_recog(frame):
name = "not a face"
#encoding
frame_codes = face_recognition.face_encodings(frame)#encoding frame
# if frmae not face ,skip
if(len(frame_codes)>0):
uface_code = frame_codes[0]#get uface code
name = "unkonw"
result = face_recognition.compare_faces(faces,uface_code,tolerance=0.45)
for index,i in enumerate(result):
if i:
name = names[index]
break
#show face_location and recognition_result
return name
# main function
if __name__ == "__main__":
global name
name = "not a face"
pool = mp.Pool(processes=4)
i = 0
r = [None] * 4
facesList = [None] * 4
frame = [None] * 4
imageList = [None] * 16
cap = cv2.VideoCapture(0)
#decrease its scale
cap.set(3,320)
cap.set(4,240)
#assignment the process first
ret,frame[0] = cap.read()
r[0] = pool.apply_async(get_faces,[frame[0]])
ret,frame[1] = cap.read()
r[1] = pool.apply_async(get_faces,[frame[1]])
ret,frame[2] = cap.read()
r[2] = pool.apply_async(get_faces,[frame[2]])
ret,frame[3] = cap.read()
r[3] = pool.apply_async(get_faces,[frame[3]])
facesList[0],imageList[0] = r[0].get()
facesList[1],imageList[4] = r[1].get()
facesList[2],imageList[8] = r[2].get()
facesList[3],imageList[12] = r[3].get()
for j in range(4):
imageList[4*j+1] = imageList[j]
imageList[4*j+2] = imageList[j]
imageList[4*j+3] = imageList[j]
while(1):
#whether to quit
if cv2.waitKey(1) & 0xFF == ord('q'):
#cv2.imwrite("camera.jpg",frame) #write image to file
break
if(i==0):
ret,frame[0] = cap.read()
r[0] = pool.apply_async(get_faces,[frame[0]])
sign_faces(imageList[i+1],facesList[0],name)
elif(i==1):
ret,frame[0] = cap.read()
imageList[i] = frame[0]
sign_faces(imageList[i+1],facesList[0],name)
elif(i==2):
ret,frame[0] = cap.read()
imageList[i] = frame[0]
sign_faces(imageList[i+1],facesList[0],name)
elif(i==3):
ret,frame[1] = cap.read()
imageList[i] = frame[1]
facesList[1],imageList[i+1] = r[1].get()
sign_faces(imageList[i+1],facesList[1],name)
elif(i==4):
ret,frame[1] = cap.read()
r[1] = pool.apply_async(get_faces,[frame[1]],)
sign_faces(imageList[i+1],facesList[1],name)
elif(i==5):
ret,frame[1] = cap.read()
imageList[i] = frame[1]
sign_faces(imageList[i+1],facesList[1],name)
elif(i==6):
ret,frame[1] = cap.read()
imageList[i] = frame[1]
sign_faces(imageList[i+1],facesList[1],name)
elif(i==7):
ret,frame[2] = cap.read()
imageList[i] = frame[2]
facesList[2],imageList[i+1] = r[2].get()
sign_faces(imageList[i+1],facesList[2],name)
elif(i==8):
ret,frame[2] = cap.read()
r[2] = pool.apply_async(get_faces,[frame[2]])
sign_faces(imageList[i+1],facesList[2],name)
elif(i==9):
ret,frame[2] = cap.read()
imageList[i] = frame[2]
sign_faces(imageList[i+1],facesList[2],name)
elif(i==10):
ret,frame[2] = cap.read()
imageList[i] = frame[2]
sign_faces(imageList[i+1],facesList[2],name)
elif(i==11):
ret,frame[3] = cap.read()
imageList[i] = frame[3]
facesList[3],imageList[i+1] = r[3].get()
sign_faces(imageList[i+1],facesList[3],name)
elif(i==12):
ret,frame[3] = cap.read()
r[3] = pool.apply_async(get_faces,[frame[3]])
sign_faces(imageList[i+1],facesList[3],name)
elif(i==13):
ret,frame[3] = cap.read()
imageList[i] = frame[3]
sign_faces(imageList[i+1],facesList[3],name)
elif(i==14):
ret,frame[3] = cap.read()
imageList[i] = frame[3]
sign_faces(imageList[i+1],facesList[3],name)
elif(i==15):
ret,frame[0] = cap.read()
imageList[i] = frame[0]
facesList[0],imageList[0] = r[0].get()
if(name=="not a face"):
if(len(facesList[0])==1):
name = face_recog(imageList[0])
else:
if(len(facesList[0])!=1):
name = "not a face"
sign_faces(imageList[0],facesList[0],name)
i = -1
i += 1
cap.release()
cv2.destroyAllWindows()
结果展示:
zxPi (raspberrypi) - VNC Viewer 2021-06-14 00-09-33

















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









