






目录
一、语义分割:逐像素的二分类问题
1、损失函数:采用逐像素的交叉熵损失函数(Cross Entropy Loss)
为了更高效的使样本的预测值逼近真实值,可考虑在损失函数中加入样本均衡、样本数量等因素。交叉熵损失函数公式如下:
①考虑正样本和负样本的比例,针对样本的前景和背景比例不一样,使得样本中每个像素点的重要程度不一样,在原本的交叉熵损失函数加入权重项 posweight,可以加强对重要的像素点的学习,加入权重项的交叉熵公式如下:
②针对要学习的样本困难程度不同,可设置参数r,具体的交叉熵公式如下:
③结合样本数量的权值的交叉熵公式如下:
一般交叉熵的值越小,模型预测效果就越好。
2、评价指标:IOU、MIOU
IOU(intersection over Union,交并比):对某一类别预测结果和真实值的交集与并集的比值。
MIOU(Mean Intersection over Union,平均交并比):对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果,一般当作多任务分割的评价指标。
二、U-net网络
1、作用:主要解决小目标问题的图像分割
2、网络结构:
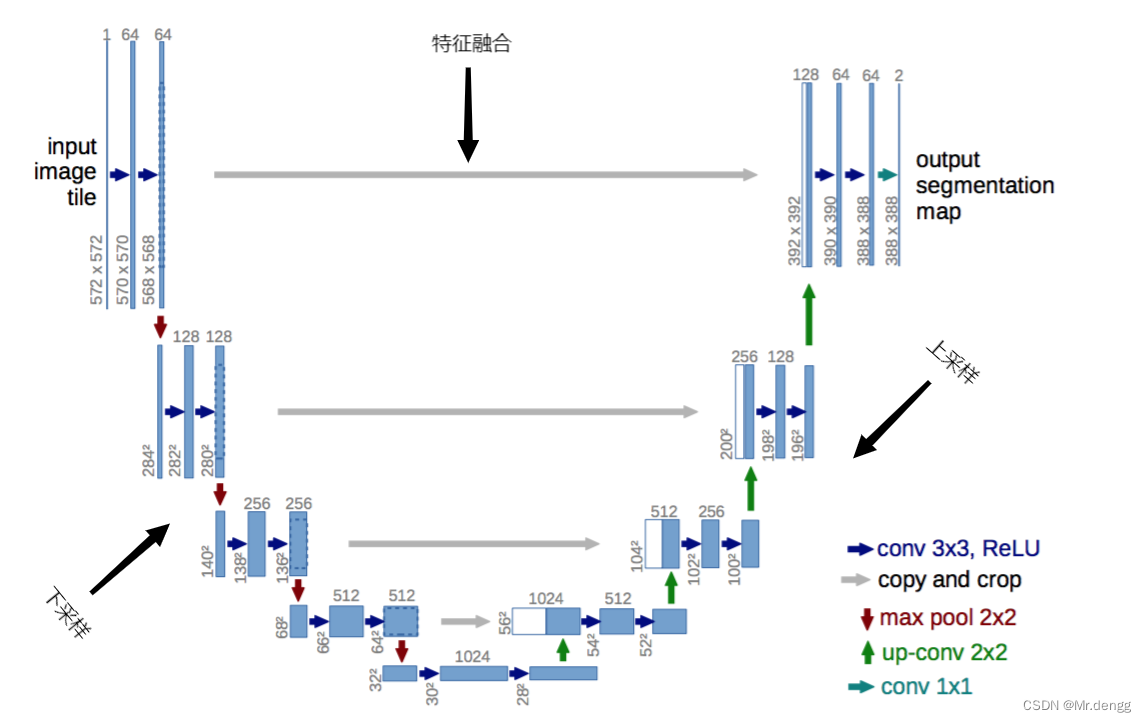
特点:相比于其他语义分割网络,网络结构简单,因此适合做一些小目标的分割。
结构:
①引入了特征拼接操作,使得原始的浅层特征和后面的复杂特征相互融合,减少特征的丢失;
②网络包括上采样和下采样两个部分,也就是编码和解码的过程。
③学习的U-net代码来源:https://github.com/mateuszbuda/brain-segmentation-pytorch
(此为深度学习小白的学习笔记,可能目前学习不够深入,存在一些问题,虚心求教)















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









