







写在前面:12月20号,airpods pro到了。11月27号买的,18号才发货,虽然预计时12月27号到货。说实话很期待,iphone 11很大程度也只是为了体验下这个耳机才买的。刚戴上,感觉这个世界都安静了。。然后,感觉音质就那个亚子吧,我一直觉得自己对音质还是有追求的,直到我确认我是个木耳。。。。总的来说还是挺香的,前提不考虑价格的,,
还有,就是21号开始考研结束了,我是个局外人,说实话没啥感触,但是总是再告诫自己要用写感触,毕竟也算时在旁边参观过了。。我是希望舍友们都上岸,但是,我知道这是不可能的。让他们自求多福吧。。
还有, 还有,就是今天导员发了,下学期初的生产实习手续,我主动用邮件联系了hr,申请了实习,并说了手续的事。哇,邮件发了不到10分钟,hr就电话主动联系了我,,这效率太高了。。结果就是,公司方面,打印我发的联系函,盖章子,再给我发来。真的辛苦hr了。反观舍友的百度,我还羡慕他们有专门的hr,可是他们的hr说只能实习完后才能盖章。。。
正文
你几乎不会直接创建pod,而是创建ReplicationController或Deployment这样的资源,接着由它们来创建并管理实际的pod。
当你创建未托管的pod时,会选择一个集群节点来运行pod,然后在该节点上运行容器。k8s接下来会监控这些容器,并且在它们失败的时候自动重新启动它们。但是如果整个节点失败,那么节点上的pod会丢失,并且不会被新节点替换,除非这些pod由 ReplicationController或类似的资源来管理。
存活探针
k8s可以通过存货探针(liveness prode)检查容器是否正常运行。可以为pod中的每个容器单独指定存活探针。如果探测失败,k8s将定期执行探针并重新启动容器。(所以说存活探针是容器级别的)
k8s有以下三种探测容器机制:
- HTTP GET 探针对容器的IP地址,执行HTTP GET请求。如果探测器收到响应。并且响应状态码不代表错误(状态码是2xx,3xx),则认为探测成功。如果服务器返回错误响应状态码,或者根本没有响应,那么探测具备认为是失败的,容器将会被重启。
- TCP套接字探针尝试与容器指定端口建立TCP连接。如果连接成功建立,则探测成功。否则,容器冲洗启动。
- Exec探针在容器内执行任意命令,并检查命令的退出状态码。如果状态码是0,则探测成功。所有其他状态码都被认为失败。
下面是代码:
apiVersion: v1
kind: pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luska/kubia-unhealthy
name: kubia
livenessProbe: # 创建一个存活探针
httpGet: # 一个httpGet探针
path: / #
port: 8080该pod的描述文件定义了一个httpGet存活探针,该探针告诉k8s定期在端口8080路径上执行HTTP GET请求,以确定该容器是否健康。这些请求在容器运行后立即开始。
kubectl create -f 上面的文件名
kubectl get po kubia-liceness
插入log相关的
kubectl logs mypod --previous 查看重启之前的容器日志
kubectl logs 默认打印当前运行的容器,当想看到前一个容器的日志时,可以加这个参数
kubecl describe po kubia-liveness 查看pod描述
里面有个Exit Code,可能的选项是 137 ,代表该进程由外部信号终止。数字137是两个数字的总和,128+x,其中x是终止进程的信号编号。如137,x为9,这个是SIGKILL的信号编号,意味着这个进程被强行终止。
里面还用关于探针的描述
Liveness: http-get http://:8080/ delay=0s timeout=1s period=10s #success=1 #failure=3delay(延迟),timeout(超时), period(周期)。
delay=0s部分显示在容器启动后立即开始探测。
timeout仅设置为1秒,因此容器必须在1秒内进行响应,不然这次探测记做失败。
每秒探测一次容器(period=10s),并在探测连续三次失败(#failure=3)后重启。
配置存活探针的附加属性
initialDelaySeconds: 15 # 会在第一次探测前等待15秒,一定要设置这个,不然会出错啊
apiVersion: v1
kind: pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luska/kubia-unhealthy
name: kubia
livenessProbe: # 创建一个存活探针
httpGet: # 一个httpGet探针
path: / #
port: 8080
initialDelaySeconds: 15 # 会在第一次探测前等待15秒如果没有设置初始延迟,探针将在启动后立即开始探测容器,这通常会导致探测失败,因为应用程序还没准备好开始接收请求。如果失败次数超过阈值,在应用程序能正确响应前,容器就会重启。
ReplicationController
简称rc,其实现在已经逐渐不再使用它了,因为被ReplicaSet替代了。
如果pod因任何原因消失(例如节点从集群中消失或由于该pod已从节点中逐出),则rc会注意到缺少了pod并创建替代pod。
一般而言,rc旨在创建和管理一个pod的多个副本(replicas)。rc的工作是确保pod的数量始终与其标签选择器匹配。
rc的三部分:
- label selector(标签选择器),用于确定rc作用域中有哪些pod
- replica count(副本个数), 指定应运行的pod数量
- pod template(pod模板),用于创建新的pod副本
更改控制器的标签选择器或pod模板的效果
更改标签选择器和pod模板对现有pod没有影响。更改标签选择器会使现有的pod脱离rc的范围,因此控制器会停止关注它们。模板仅影响由此rc创建的性pod。可以将其视为创建新pod的曲奇切模。
创建一个ReplicationController
apiVersion: v1
kind: ReplicationController # 配置定义了RC
metadata:
name: kubia # RC的名字
spec:
replicas: 3 # pod实例的个数
selector:
app: kubia # pod选择器决定了RC的操作对象(不指定默认用模板的,所以不指定更好)
template:
metadata:
labels:
app: kubia # 给新创建的pod打上标签,必须和上面的selector一致
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080模板中的pod标签显然必须和ReplicationController的标签选择器相匹配,否则控制器将无休止地创建新的容器。根本不指定选择器也是种选择,在这种情况下,它会自动根据pod模板中的标签自动配置。
kubectl create -f 上面的文件.ymal
kubectl get pods 查看pod
kubectl delete pod 上面看到的pod实例名 删除pod,删也白删,rc会自动再创建一个pod
kubectl get rc 查看rc
kubectl describe rc kubia 查看rc的详细信息
kubectl get node 查看节点,我就很奇怪了,为啥是pods,node,node不加s?
将pod移入或移出ReplicationController的作用域
通过更改pod的标签,可以将它从ReplicatinController的作用域中添加或删除。甚至可以从一个rc移动另一个。添加另外一个标签,并没有用,因为rc不关心该pod是否有任何附加标签,它只关心该pod是否具有标签选择器中引用的所有标签。
kubectl label pod kubia-dmdck type=special 给这个pod加上一个标签
kubectl get pods --show-labels 查看所有pod的标签
kubectl label pod kubia-dmdck app=foo --overwrite 修改标签,一定要加--overwrite覆盖掉
kubectl get pods -L app 查看键是app的所有标签
修改pod模板
kubectl edit rc kubia 修改编辑ReplicationController
这将在你的默认文本编辑器中打开ReplicationController的YAML配置。然后直接保存退出,k8s自动生效。
水平缩放pod
ReplicationController扩容,
1
kubectl scale rc kubia --replicas=10 启动为10个,当然也可以减少
2 但听说k8s是推荐下面修改yml文件的声明式的方法,
kubectl edit rc kubia 找到replicas字段修改它的值
在k8s中水平伸缩pod是陈述式的,你不是告诉k8s做什么或如何去做,只是指定了期望的状态。
删除一个ReplicationController
当你通过kubectl delete删除ReplicationController时,pod也会被删除。但是也可以只删除ReplicationController并保持pod运行。当你最初拥有一组由ReplicationController管理的pod,然后决定用ReplicaSet替换ReplicationController时,可以在不影响pod的情况下执行此操作,并在替换管理它们的ReplicationController时保持pod不中断运行。

kubectl delete rc kubia --cascade=false 加这个参数,就只删除rc, 但保留pod。默认删除rc, pod也会被删除
ReplicaSet
ReplicaSet是新一代的ReplicationController,并将完全替换掉ReplicationController。
必将它们之间的区别:
rc的标签选择器只允许包含某个标签的匹配pod,但rs的选择器还允许匹配缺少某个标签的pod,或包含特定标签名的pod, 不管其值如何。总的来说,好像也就标签选择器有些区别吧,我想。
apiVersion: apps/v1beta2 # 不是v1版本API的一部分,但属于appsAPI组的v1beta2版本
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas:3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luska/kubiakubectl create -f 文件名
kubectl get rs 注意时rs,不是rc了
kubectl describe rs
上面的例子很简单,下面展示个稍微复杂的
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas:3
selector:
matchExpressions:
- key: app # 此选择器要求该pod包含名为app的标签
operator: In
values:
- kubia # 标签的值必须为kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luska/kubia每个表达式必须包含一个key,一个operator(运算符),并且可能还有一个values的列表。
有四个有效运算符:
- In: Label的值必须于其中一个指定的values
- NotIn: Label的值与任何指定的values不匹配
- Exists: pod必须包含一个指定名称的标签(值不重要)。使用此运算符时,不指定values字段
- DoesNotExist: pod不得包含有指定的名称的标签。values属性不得指定。
如果你指定了多个表达式,则所有的这些表达式都必须为true才能使选择器与pod匹配。如果同时指定了matchLabels和matchExpressions,则所有标签都必须匹配,并且所有表达式必须计算为true以使该pod与选择器匹配。
kubcetl delete rs kubia 删除rs
删除ReplicaSet会删除所有的pod。
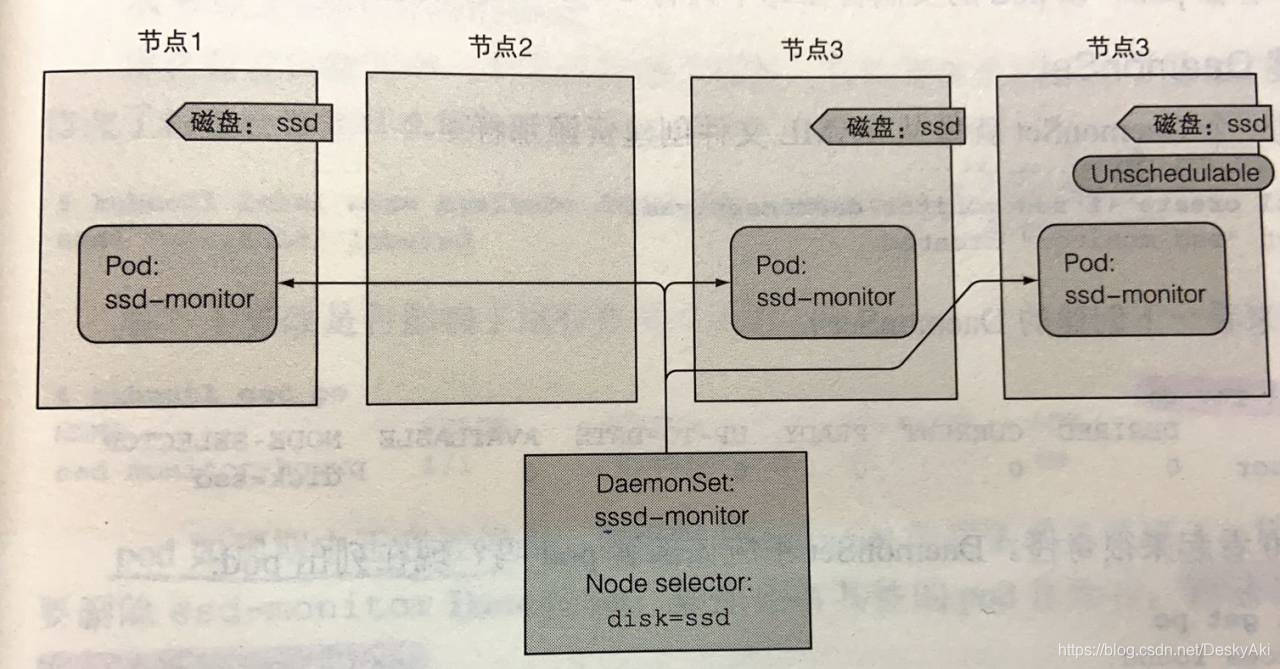
DaemonSet
ReplicaSet和ReplicationController都用于k8s集群运行部署特定数量的pod。但是,当你希望pod在集群中的每个节点上运行时(并且每个节点都需要正好一个运行的pod实例),就是说每个节点都只运行一个pod。
例如,希望在每个节点上运行日志收集器和资源监控器。另一个典型的例子是k8s自己的kube-proxy进程。
DaemonSet并没有期望的副本数的概念。它不需要,因为他的工作是确保一个pod匹配它的选择器并在每个节点上运行。
如果节点下线,DaemonSet不会在其他地方重新创建pod。但是。当将一个新节点添加到集群中时,DaemonSet会立刻部署一个新的pod实例。如果有人无意中删除了一个pod,那么它也会重新创建一个新的pod。
使用DaemonSet只在特定的节点上运行pod
DaemonSet将pod部署到集群中的所有节点上,除非指定这些pod只在部分节点上运行。这是通过pod模板中的nodeSelector属性指定的。
节点可以被设置为不可调度的,防止pod被部署到节点上。DaemonSet甚至会将pod部署到这些节点上,因为无法调度的属性只会被调度器使用,而DaemonSet管理pod则完全绕过调度器。
用一个例子来解释Daemonset
创建一个DaemonSet,它在标记为具有SSD的所有节点上运行这个守护进程。集群管理员已经向所有此类节点添加了disk=ssd的标签,因此使用节点选择器创建DaemonSet,该选择器只选择具有该标签的节点。
apiVersion: apps/v1beta2 # 注意版本
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector: # pod模板包含一个节点选择器,会选择有disk=ssd标签的节点,注意是节点
disk: ssd
containers:
- name: main
image: luksa/ssd-monitorkubectl create -f xx.yaml
kubectl get ds
别忘了给节点加上标签
kubectl get node
kubectl label node minikube disk=ssd 给节点加上标签,对应yaml的nodeSelector
kebectl label node minikube disk=hhd --overwrite 修改节点的标签
修改标签的这个节点的pod会被终止。
Job资源
ReplicationController、ReplicaSet和DaemonSet会持续运行任务,永远达不到完成态。这些pod中的进程在退出时会重启。但是在Job资源中,一旦完成,pod就被认为处于完成状态。
Job,它允许运行一种pod,该pod在内部进程成功结束时,不重新启动容器。一旦任务完成,pod就被认为处于完成状态。
在发生节点故障时,该节点上由Job管理的pod将按照ReplicaSet的pod的方式,重新安排到其他节点。如果进程本身异常退出,可以将Job配置为重洗启动容器。
通俗的讲,就是任务正常执行的话,执行完任务,job就结束进程。如果任务意外中断,就重启任务。
apiVersion: batch/v1 # 注意版本
kind: Job
metadata:
name: batch-job
spec: # 没指定pod选择器,它将根据pod模板中的标签创建
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure # Job不能使用Always为默认的冲洗启动策略
containes:
- name: main
image: luksa/batch-job
在pod定义中,可以指定在容器中运行的进程结束时,k8s会做什么。它是通过pod配置的属性的restartPolicy完成的,默认为Always。Job pod不能使用默认策略,因为它们不是要无限期运行的。因此,需要明确地将重启策略设置为OnFailure或Never。
kubectl create -f xxxxx
kubectl get jobs
kubectl get po 书上的容器,120秒会完成,所以过了一会,接看不到pod了
kubectl get po -a 或者 kubectl get po --show-all 会显示已完成的pod
在Job中运行多个pod实例
job可以配置为创建多个实例,并以并行或串行方式运行它们。
顺序运行Job pod
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 将使此作业顺序运行5个
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure # Job不能使用Always为默认的冲洗启动策略
containes:
- name: main
image: luksa/batch-job
Job将一个接一个地运行五个pod。它最初创建一个pod,当pod的容器运行完成时,它创建第二个pod,以此类推,直到五个pod成功完成。如果其中一个pod发生故障,Job会创建一个新的pod,所以Job总共可以创建五个以上的pod.
并行运行Job pod
同时运行pod.
apiVersion: batch/v1
kind: Job
metadata:
name: multi-completion-batch-job
spec:
completions: 5 # 将使此作业顺序运行5个
parallelism: 2 # 最多两个pod可以并行运行
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure # Job不能使用Always为默认的冲洗启动策略
containes:
- name: main
image: luksa/batch-job
就是可以同时运行两个pod,一个pod运行完,再启动一个pod。
kubectl scale job xxxx --replicas 3 指定pod可以同时运行几个pod
安排Job定期运行或在将来运行一次
就是相当于Linux的定时任务。
apiVersion: batch/v1beta1 # 注意版本又TM不一样了
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: "0,15,30,45 * * * *" # 工作应该每天在每小时0、15、30和45分钟运行
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luska/batch-job
在计划时间内,CronJob资源会创建Job资源,然后Job创建pod。
可能发生Job或pod创建并运行相对较晚的情况。
apiVersion: batch/v1beta1 # 注意版本又TM不一样了
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
schedule: "0,15,30,45 * * * *" # 工作应该每天在每小时0、15、30和45分钟运行
statringDeadlineSeconds: 15 # pod最迟必须在预定时间后15秒开始运行
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luska/batch-job
在本例中,功能时间应该时10:30:00。 如果因为任何原因10:30:15不启动,任务将不会运行,并显示Failed。















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









