






一、保持pod健康
只要将pod调度到某个工作节点上,这个节点上的kubelet就会运行pod的容器。
如果一个容器内的主进程挂了,也就是容器从内部挂了,kubelet自然能检测到容器的失败并重启容器,但试想一个java程序崩溃了,但JVM的程序还在运行,这个容器看起来依然在运行,但实际已经没有提供任何可用的服务了,这时候kubelet是不会重启容器的,所以要有一种从外部检测容器失败的机制,来保持pod的健康运行,即存活探针。
1、存活探针
k8s可以通过存活探针从外部检查容器是否还在运行,有三种探测机制:
(1)HTTP GET探针对容器的IP地址执行GET请求,收到正确响应就认为探测成功
(2)TCP套接字探针尝试与容器指定端口建立TCP连接
(3)Exec探针在容器内执行任意命令,并检查命令的退出状态码是否为0
2、创建存活探针
apiVersion:
kind: Pod
metadata:
spec:
containers:
- image:
name:
livenessProbe:
httpGet:
path: /
port: 8080使用kubectl describe po 可以看到pod有一个存活探针描述liveness
3、存活探针的附加属性
delay=0s //容器启动后隔多长时间开始探测,应该设置长一点,因为容器刚启动,还没有开始提供服务,此时探测肯定失败
timeout=1s //每次探测容器需要在多长时间内作出响应
period=10s //每次探测的时间间隔
#failure=3 //连续失败几次后重启容器4、何为有效的存活探针
(1)一定要检查应用程序的内部。假如容器内运行的是一个前端web应用,HTTP GET不应该返回失败,但是后端已经与数据库断联,并未检测到容器的运行失败。
所以可以写一个health接口,存活探针去请求这个接口,接口内容保证应用程序没挂
(2)保持探针轻量。存活探针的执行频率相对较高,应该轻量化存活探针,否则会占用容器的资源,使容器主程序的性能变差
(3)不需要在存活探针中实现重试循环。存活探针自带循环机制,失败多次则重启容器,无需自定义、
5、小结
探针的执行和pod的运行、重启都是由kubelet完成的,但如果k8s工作节点崩溃了,kubelet也无法进行探测、重启的操作,所以保证在此情况下pod能被调度到其他节点,就需要replicationcontroller或类似机制来管理pod
二、 了解ReplicationController
kubelet会在容器崩溃或存活探针失败时重启容器,而ReplicationController会在pod消失(delete或工作节点挂了)时重启pod,RC旨在创建和管理一个pod的多个副本
1、协调流程
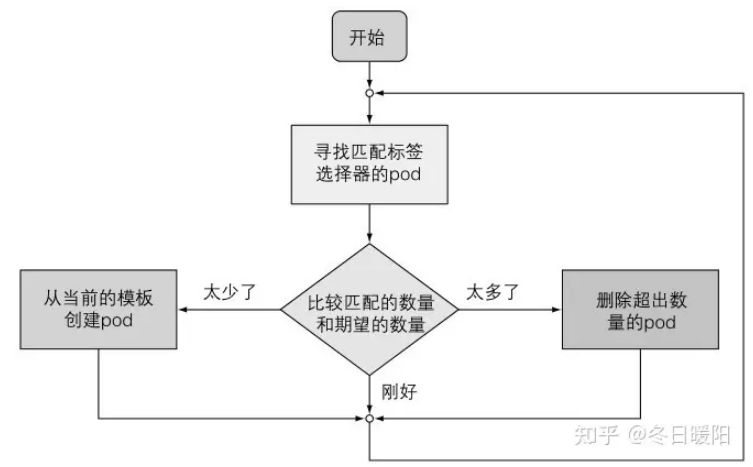
rc是通过标签选择器判断同一类型的pod的数量的
一个rc有三个主要部分:
(1)label selector标签选择器:用于确定此rc作用域中有哪些pod
(2)replica count副本个数:指定应运行的pod数量
(3)pod template pod模板:用于创建新的pod副本
使用rc的好处:
(1)确保一个pod(或多副本的pod)持续运行,方法是pod丢失时启动一个新pod
(2)集群节点发生故障时,它会为故障节点上运行的所有pod创建替代副本
(3)它能轻松实现pod的水平伸缩,也就是增减pod 的副本数
2、创建一个rc

重点关注标签选择器和标签
无论一个pod因为什么原因消失,只要打了此标签的pod数量没有达到预期数量,rc就会启动一个此标签的pod
3、修改pod的标签
如果给pod增加了一个其他标签,那么它原来的标签没变,pod依然由rc管理
如果将上述pod的app=kubia的标签删了,rc则认为少了一个pod,会启动一个新的打这个标签的pod,原来的pod不归任何rc管理,可以随意删除
如果有其他rc管理了标签为app=kubia1的pod,将现有app=kubia标签的pod的标签改为kubia1,则归该rc管理
4、修改pod模板
假设现在已经启动了3个pod,但想修改pod的模板启动新的pod,那就修改完后,删除一个旧pod,rc会根据新模板创建新pod
修改模板的方式为:
kubectl edit rc xxx5、水平缩放pod
修改rc的副本数即可,replicas
两种方式:
第一种直接一行命令:
kubectl scale rc xxx --replicas=10
第二种用上面的edit命令修改rc的模板,将replicas设置为10
6、删除rc
kubectl delete rc xxx会删除一个rc,此操作会把相关的pod一并删除,但是由于pod不是rc的一部分,只是由rc管理,所以可以选择只删除rc同时保留pod
场景:已经有pod在运行,想替换控制器,由rc替换为ReplicaSet,那就删了rc,保留pod,创建ReplicaSet,让ReplicaSet管理这些pod
做法:kubectl delete rc xxx --cascade-false
三、使用ReplicaSet而不是ReplicationController
1、区别对比
rs和rc的功能基本相同,但rs的pod选择器的表达能力更加强大,区别在于:
rc只选择带有特定标签的pod,例如它只能管理app=kubia的pod
rs可以选择多个标签的pod,例如他可以管理具有app=kubia或app=kubia1或其他不同key的标签的pod
2、定义方式:
(1)与rc类似的定义:

(2)更富表达力的定义方式:
selector:
matchExpression:
- key: app
operation: In
values:
- kubiaoperation 的可写项有:In、NotIn、Exists(针对标签,使用时,不应指定values)、DoesNotExists(针对标签,使用时,不应指定values),如果同时指定多个表达式,这些表达式都为true才能匹配上pod
四、另一种副本控制器DaemonSet
作用:在集群的每个节点上部署一个pod
应用:每个节点上运行日志收集器、资源监控器、k8s自己的kube-proxy进程,每个节点有且仅有一个
使用:与rs相同,用标签选择器来管理pod,但打标签的对象的节点node,而不是pod。给节点打上相应标签,定义DaemonSet,它就会在每个打上标签的节点上运行定义的pod,当有新的节点加入集群时,会在该节点上创建一个pod
五、另一种副本控制器Job
前面介绍的都是持续运行的pod,无论时pod容器崩溃了被重启,还是pod消失了被重创,pod都会持续存在,现在想要一个执行完任务后就停止的进程,就需要用Job这种资源来管理
这个完成任务就停止的pod,在任务执行中失败了依然会重启,pod消失了依然会重创,节点故障了依然会被调度到其他节点
1、定义Job
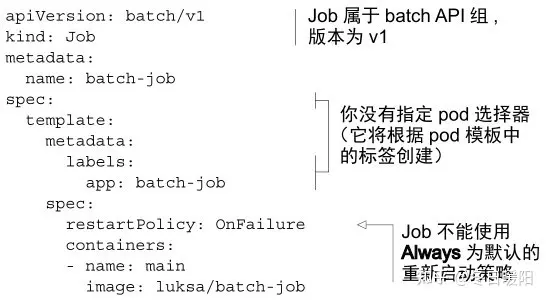
一定要注意重启策略的设置,Job类的pod不能设置restartPolicy为Always,只能是OnFailure或Never
pod完成任务后不会被删除,而是标记状态为Completed,需要手动去删除它,或直接删除job
2、一个job运行多个pod实例
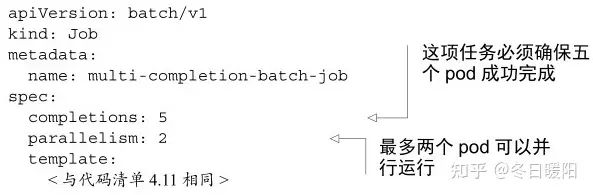
注意completions和parallelism参数,parallelism不设置就是串行运行,job运行中可以通过kubectl scale job xxx --replicas 3修改并行pod数
3、限制job pod的完成时间
如果pod卡住就是完不成任务,job也不能一直等待,应该设置一个最大超时时间,可以在pod配置中设置activeDeadlineSeconds属性,超时了job就会被标记为失败
可以指定Job 中的spec.backoffLimit字段,配置job在标记失败之前可以重试的次数,默认6次
六、定时运行job:CronJob

job的spec.schedule计划规定了job的执行时间
还可以指定一个参数spec.startingDeadlineSeconds: 15,即由于种种原因,cronjob并不一定在指定时间执行,那最大延迟多久后,判定job失败呢?就是设定这个参数















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









