







文件上传流程:
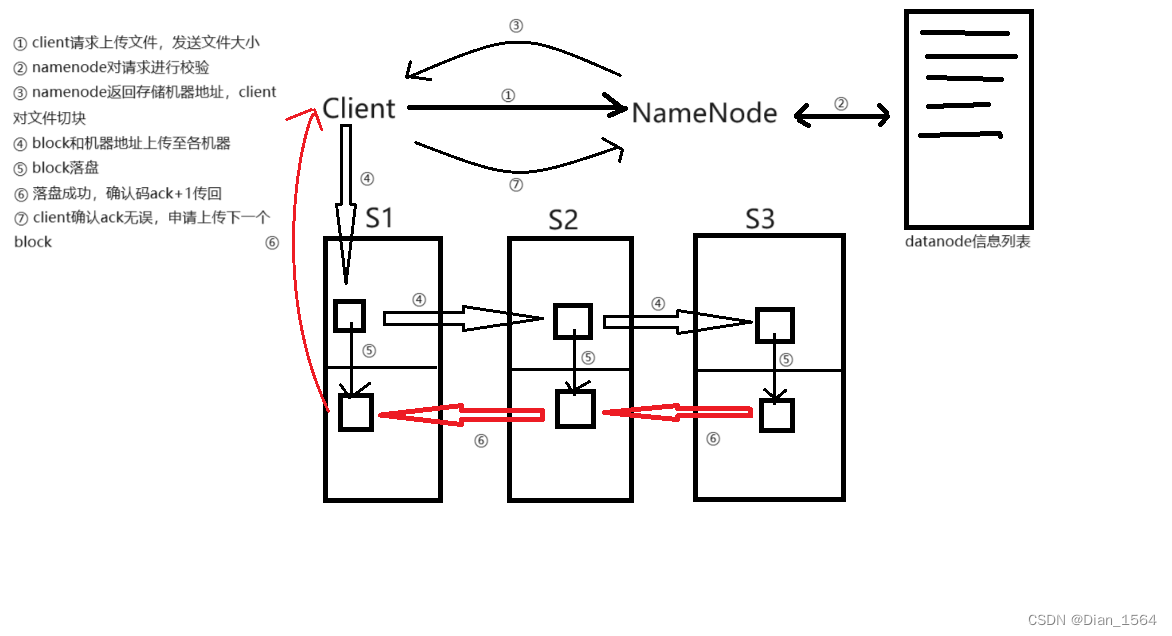
1. 客户端向namenode申请上传文件
2. namenode对申请进行校验,校验是否有上传权限,更重要的是校验集群中所有datanode的剩余磁盘空间是否能存下该文件的三倍大小(文件默认一备三,可以通过更改dfs.replication参数调整备份数量)。
校验方法:剩余磁盘空间大小/128M(单个block大小)【向下取整】 与 文件大小/128M(单个block大小)【向上取整】*3 进行比较
校验不通过则拒绝上传申请
校验通过,namenode将返回该文件的第一个block在集群中需要存储的三台机器的地址
3. 客户端收到校验通过的反馈,对文件进行切块处理成多个block,并对每个block编号,上传文件需要严格按照编号顺序逐一上传(上传文件不能并发)。
// 切块方法
public void cut() throws IOException {
String filePath = "";
// 随机读写流
RandomAccessFile raf = new RandomAccessFile(filePath,"r");
/*
* 切块方法
* 重点:两个block之间的数据划分,block大小可以在128M上下浮动
* seek函数跳过 128M+当前行剩余长度+行末尾\r\n的长度
* */
raf.seek(128*1024*1024+raf.readLine().length()+2);
}客户端根据地址信息与距离其最近的机器建立长链接,通过输出流将block以及所有机器的地址输出到第一台机器上(此时还没有落盘),第一台机器再与离自己最近的机器建立连接并传输block和所有机器地址。
直到三台机器都获得block,从后往前开始落盘,每次成功落盘会将确认码ack+1发回上一台机器,所有落盘任务结束后,ack将被发回客户端校验是否为3,确认无误后向namenode申请上传第二个block并重复第三步(除了切块操作)
注:客户端与机器之间建立连接的过程中,若出现建立失败状况,客户端则向namenode报告错误,namenode确认该datanode死亡后,重新发送一次三台机器地址。
4. 所有block上传完毕,客户端和namenode报告上传完毕,任务结束。
*徒手画图有点丑见谅
文件下载流程:
1. 客户端向namenode申请下载文件
2. namenode对申请校验,校验是否有下载权限,校验集群中是否存在该文件并获取文件路径
3. 根据文件路径,通过逻辑映射关系:目录层次结构——根目录 -> 一级子目录 -> 二级子目录 -> ... -> 文件 -> blockID,每个层次都有一个id
以及物理结构:datanode通过心跳实时上传的真实数据——blockID与其映射的完整路径(包含三台主机)
namenode挑选三个block中最优的一个(闲置度高且距离近),将它所在的机器地址和完整路径返回客户端
4. 客户端收到反馈,以流的方式建立连接拉取数据,第一个block传输完毕再向namenode申请下载第二个,如此循环。
5. 客户端所有block接收完毕合并为一个文件。
















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









