








基于学习的编码(六):DRNLF
本文算法来自JVET-L0242,dense residual convolutional network based in-loop filter (DRNLF)用于VTM的环路滤波中,用在DBF之后,SAO和ALF之前,如下图所示。

由RDO决定是否使用DRNLF。
网络结构
DRNLF的结构如下图:

N代表DRU(dense residual unit)数量,M代表卷积核数量。
本文算法是JVET-K0391的改进,K0391中DRU的结构如下图所示:


主要有5个方面改进:
-
删除了外部(global identity skip connection)3x3卷积层,加快了训练。
-
归一化的QP map和重建图像一起输入DRN,仅用一个模型就可以适应不同QP情况。
-
在YUV空间训练。
-
为了减少计算复杂度,DRU数量从8减少到4,卷积核从64减为32。
-
3x3的卷积层替换为3x3的DSC(depth-wise separable convolutional)层。
以上5个改进使模型参数由810k减少为22k。
训练
使用DIV2K生成训练集和验证集,训练集包含800幅图像,验证集包含100幅。网络在YUV空间训练,所以需要将DIV2K的图像由RGB空间转换到YUV空间。使用VTM2.0.1在AI(All Intra)配置下使用不同QP压缩图像。压缩后的图像和对应的QP作为网络输入。压缩前的图像作为ground truth。假设压缩图像集为{X},对应的ground truth集为{Y},则损失函数如下:

实验
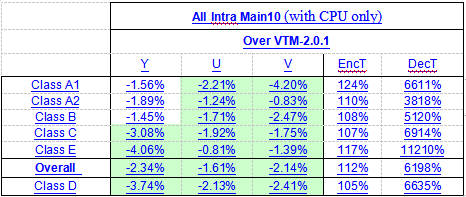
在VTM2.0.1内,AI配置,QP取{22,27,32,37},仅使用CPU环境的实验结果如下:
感兴趣的请关注微信公众号Video Coding
















 958
958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









