








本文来自VCIP 2020论文《Deep Inter Coding with Interpolated Reference Frame for Hierarchical Coding Structure》

在混合编码框架中,帧间预测用于去除时域冗余。帧间预测的效果取决于参考帧的内容,当参考帧和待编码帧的内容越相似时编码效率越高,因此本文提出利用DNN合成参考帧然后插入参考帧列表用于后续的预测。本文算法在HM16.20上RA配置下,相当于HEVC有4.6%的BD-rate增益。
本文算法流程图如下所示,
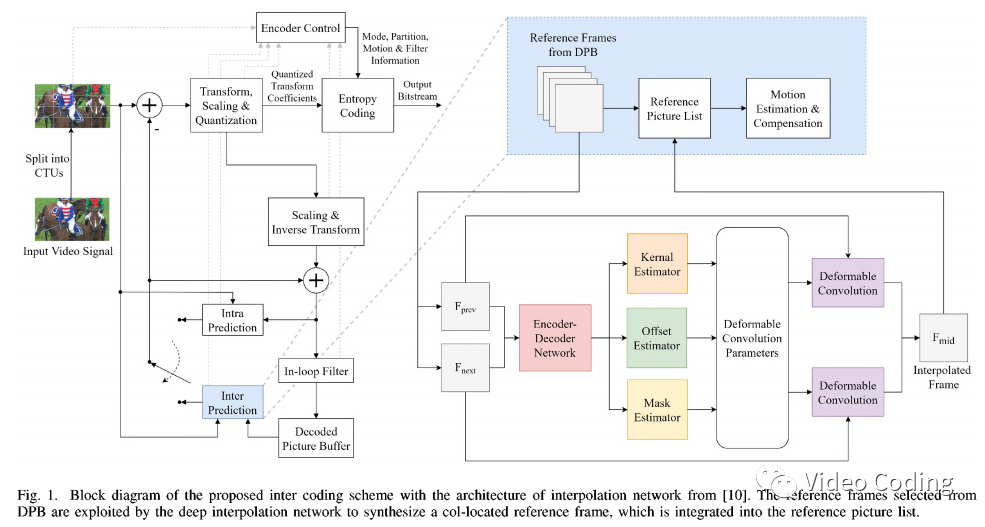
基于DNN的参考帧生成
本节将介绍针对HEVC分层结构的参考帧生成方法。将DPB中的参考帧作为输入放入DNN,然后将DNN输出的帧放入参考列表(RPL)用于后续的预测。
本算法利用HEVC在RA配置下的分层B帧结构,分层B帧结构有5个时域层,如下图所示。
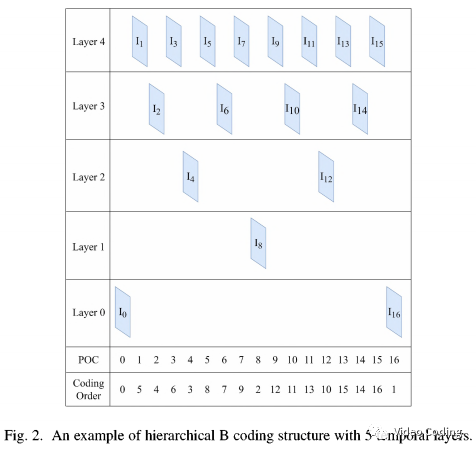
上图中,GOP中的帧被分到不同的时域层,可以看到播放顺序(POC)不同于编码顺序。低时域层的帧优先于高时域层的帧编码,高时域层的帧可以利用低时域层帧的重建帧作为参考。
为了在当前帧位置生成参考帧,DNN要输入DPB中离当前帧最近且距离相等的两个帧。假设F(.)表示利用DNN生成参考帧的过程,I_p表示POC=p的帧,I_p_r表示I_p的重建帧。则时域层级为L(I_p)的帧I_p的参考帧生成过程如下,
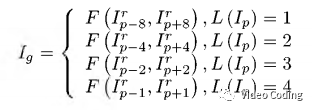
此外,由于不同时域层级的质量不同(使用层级越高QP越大),因此对不同时域层级应该分别训练模型,针对5个时域层级的情况应该训练4个不同的模型,但是这会加重编码器的负担,所以本文使用一个模型处理所有时域层级。
网络结构
本文使用DSepConv网络结构来训练插帧模型。如Fig.1所示,整个网络分为4个模块,2帧图像作为输入,然后通过编码器-解码器结构提取特征传给3个子模块用于估计参数(包括kernel、offset、mask)。
本文算法集成在HM16.20中,在编码过程中有两个RPL:List0和List1。List0中包含前向参考帧,其POC小于当前帧。List1中包含后向参考帧。对于B帧,它需要两个参考帧分别来自List0和List1。
本文算法会将DNN生成的参考帧插入List0和List1的末尾,它们会像普通帧一样用于运动预测。而且生成帧的信息不用在码流中传输,因为编码器和解码器可以按同样的方法生成这些帧。同时,生成帧的POC设为和当前帧一样。
实验结果
训练数据
训练集是Vimeo90K,它包含55095个分辨率为448x256的视频。网络的输入是不同压缩率的重建视频帧。为了使模型更鲁棒,对视频的第一帧和最后一帧在HM16.20下采用AI配置编码,QP从20到44。模型两个输入帧的QP的差值从0到10之间随机选择,这样便可以只训练一个模型来处理不同QP的情况。为了增广数据,在训练集只随机裁剪128x128的图像并进行随机旋转或翻转操作。
训练策略
模型通过Pytorch训练,损失函数中同时考虑了像素级预测失真和图像梯度。损失函数通过Adam优化器进行最小化,batch取16。首先对网络进行120 epochs次训练,学习率初始为1e-4,每40 epochs减小一半。最后使用256x256的patches,学习率为6.25-6对网络进行微调。
结果
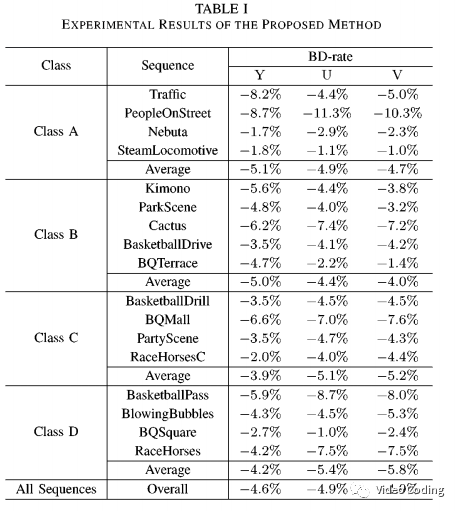
使用class A到class D的序列进行测试,结果如上表所示。亮度分量可以达到4.6%的BD-rate增益。尤其是在高分辨率的视频上算法表现更好,在PeopleOnStreet序列上可以达到8.7%的BD-rate增益。此外,为了测试微调策略的有效性,和class B序列上和不使用微调的模型相比使用微调可以达到0.5%的BD-rate增益。
感兴趣的请关注微信公众号Video Coding
















 2764
2764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









