









1、HyperLPR3简介
HyperLPR3是一款高性能开源中文车牌识别。源码:https://github.com/szad670401/HyperLPR
2、快速部署与简单使用
参考文章:HyperLPR3车牌识别-五分钟搞定: 中文车牌识别光速部署与使用
3、利用OpenCV对RTSP视频流实时读取
我是参考yolo5的streamload使用python迭代器实现视频流读取,视频流读取部分可以按照自己想法继续优化,例如视频流读取分离。
dataset.py
import math
import time
import threading
import platform
import cv2
import numpy as np
from utils.my_logger import logger
class LoadStreamsByRTSP:
def __init__(self,camera_list):
self.camera_list = camera_list
n = len(camera_list)
# 原尺寸图像 初始化图片 fps 总帧数(无穷大) 线程数 相机ip数组
self.orgImgs,self.imgs, self.fps, self.frames, self.threads,self.camIps,self.ids =[None] * n, [None] * n, [0] * n, [0] * n, [None] * n,[None]*n,[None]*n
self.sources = [] # clean source names for later
self.countFrm = {} #统计帧数,索引,帧数
for i,item in enumerate(camera_list):
# Start thread to read frames from video stream
st = f'{i + 1}/{n}: {item[0]}... '
rtspUrl = item[2]
cap = cv2.VideoCapture(rtspUrl)
if cap.isOpened():
print(f'{rtspUrl} open success !')
self.sources.append(rtspUrl) # rtsp地址
# 如果当前Rtsp流打开失败,记录错误日志,并循环下一个流
else :
logger.error(f'{st}Failed to open {item[0]}')
continue
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取视频宽度
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取视频高度
fps = cap.get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
_, self.imgs[i] = cap.read() # guarantee first frame
self.orgImgs[i] = self.imgs[i].copy()
self.countFrm[i] = 0
self.camIps[i] = item[0] # 记录当前相机IP,用于业务判断
self.ids[i] = item[1] # 记录当前相机编号
self.threads[i] = threading.Thread(target=self.update, args=([i, cap, rtspUrl]), daemon=True)
logger.info(f"{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
print(f"{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
self.threads[i].start()
print(' ') # newline
def update(self, i, cap, stream):
if cap.isOpened():
while True:
success, im = cap.read()
if success:
self.orgImgs[i] = im #原始图像
else:
logger.warning(f'WARNING: Video stream[{stream}] unresponsive, please check your IP camera connection.15s restart stream...')
self.orgImgs[i] = np.zeros_like(self.orgImgs[i])
time.sleep(15)
cap = cv2.VideoCapture(stream)
if cap.isOpened():
logger.info(f'{stream} restart success !')
#time.sleep(1 / self.fps[i]) # wait time if videofile
def __iter__(self):
#self.count = -1
return self
def initImgs(self):
# 需保证imgs里没有None的图片
while self.imgs[0] is None:
time.sleep(1)
for i,im in enumerate(self.imgs):
if self.imgs[i] is None:
self.imgs[i] = np.zeros_like(self.imgs[0])
while self.orgImgs[0] is None:
time.sleep(1)
for i,im in enumerate(self.orgImgs):
if self.orgImgs[i] is None:
self.orgImgs[i] = np.zeros_like(self.orgImgs[0])
def __next__(self):
beginTime = time.time()
orgImgs = self.orgImgs.copy()
return orgImgs, beginTime,self.camIps,self.ids
def __len__(self):
return len(self.sources) 4、根据自定义修改一些默认设置(使用默认onnx推理也可跳过该步骤)
4.1、下载hyperlpr3
从Github下载Prj-Python源码,并将其中的hyperlpr3文件夹放入自己项目中。
4.2、修改模型文件夹默认位置
修改其中config文件夹下的setting.py,将模型文件夹路径设置为当前项目下,这一步也可以不做,默认是在家目录下面。
import os
import sys
_MODEL_VERSION_ = "20230229"
if 'win32' in sys.platform:
#_DEFAULT_FOLDER_ = os.path.join(os.environ['HOMEPATH'], ".hyperlpr3")
_DEFAULT_FOLDER_ = './'
else:
#_DEFAULT_FOLDER_ = os.path.join(os.environ['HOME'], ".hyperlpr3")
_DEFAULT_FOLDER_ = './'
_ONLINE_URL_ = "http://hyperlpr.tunm.top/raw/"
onnx_runtime_config = dict(
det_model_path_320x=os.path.join(_MODEL_VERSION_, "onnx", "y5fu_320x_sim.onnx"),
det_model_path_640x=os.path.join(_MODEL_VERSION_, "onnx", "y5fu_640x_sim.onnx"),
rec_model_path=os.path.join(_MODEL_VERSION_, "onnx", "rpv3_mdict_160_r3.onnx"),
cls_model_path=os.path.join(_MODEL_VERSION_, "onnx", "litemodel_cls_96x_r1.onnx"),
)
onnx_model_maps = ["det_model_path_320x", "det_model_path_640x", "rec_model_path", "cls_model_path"]
_REMOTE_URL_ = "https://github.com/szad670401/HyperLPR/blob/master/resource/models/onnx/"之后将模型文件夹复制到当前项目根目录下
5、对RTSP视频流进行实时车牌识别
plateRecognizer.py
# 导入cv相关库
import cv2
import os
import json
import time
import traceback
# 导入依赖包
import hyperlpr3 as lpr3
from hyperlpr3.common.typedef import *
from utils.my_logger import logger
from utils.dataset import LoadStreamsByRTSP
import utils.plateUtil as plateUtil
#将10位时间戳或者13位转换为时间字符串,默认为2017-10-01 13:37:04格式
def timestamp_to_date(time_stamp, format_string="%Y%m%d%H%M%S"):
time_array = time.localtime(time_stamp)
other_style_time = time.strftime(format_string, time_array)
return other_style_time
if __name__ == '__main__':
try:
camera_list = []
if not os.path.exists('images'):
os.mkdir('images')
camPlateInfoRecord = {} #记录当前相机识别到的车牌号
camPlateInfoRecordTime = {}
#catcher = {} # 识别对象
with open("config.json", encoding='utf-8') as f:
jsonData = json.load(f)
for ipkey in jsonData:
camera_list.append([ipkey,jsonData[ipkey]['id'],jsonData[ipkey]['rtspUrl']])
for item in camera_list:
print(item)
camPlateInfoRecord[item[0]] = [] # 初始化
camPlateInfoRecordTime[item[0]] = None
# catcher[item[0]] = lpr3.LicensePlateCatcher()
if not os.path.exists('./images/'+item[0]):
os.mkdir('./images/'+item[0])
# 实例化识别对象
catcher = lpr3.LicensePlateCatcher() # detect_level=lpr3.DETECT_LEVEL_HIGH
dataset = LoadStreamsByRTSP(camera_list)
dataset.initImgs()
frameSkip = 5 # 跳帧
for orgImgs, beginTime,camIps,ids in dataset:
recordTime = time.time()
for i,orgImg in enumerate(orgImgs) :
results = catcher(orgImg)
print(results)
# print(f'catcher Done. ({time.time() - beginTime:.3f}s)') # 打印时间
if len(results)>0:
plateInfo = sorted(results,key=lambda x : x[1], reverse=True)[0]# 根据置信度进行降序排序,并取置信度最高的一项
plateNo = plateUtil.get_plate_color(plateInfo[2]) + plateInfo[0] # 车牌号
plateConf = plateInfo[1] # 置信度
camPlateInfoRecordTime[camIps[i]] = recordTime
if plateConf > 0.97:
# TODO 可直接判定为最佳车牌
camPlateInfoRecord[camIps[i]].append((plateNo,plateConf,orgImg))
break
elif plateConf > 0.8:
camPlateInfoRecord[camIps[i]].append((plateNo,plateConf,orgImg))
pass
else:
# TODO 未识别到车牌
pass
#cv2.imshow(camIps[i], cv2.resize(orgImg,(1280,720))) # cv2.resize(im0,(800,600))
#cv2.waitKey(1) # 1 millisecond
if camPlateInfoRecordTime[camIps[i]] is not None:
currentTime = time.time()
# 判断时间是否大于2秒
if recordTime - camPlateInfoRecordTime[camIps[i]] > 2 and len(camPlateInfoRecord[camIps[i]]) > 0:
# 选取置信度最大的车牌信息保存
savePlateInfo = sorted(camPlateInfoRecord[camIps[i]], key=lambda e: e[1], reverse=True)[0]
save_path = './images/'+camIps[i]+'/'+timestamp_to_date(int(currentTime),'%Y%m%d%H%M%S')+'_'+savePlateInfo[0]+'_'+ids[i]+'.jpg'
cv2.imencode('.jpg', savePlateInfo[2])[1].tofile(save_path)
logger.info(f"{camIps[i]} 识别到车牌:{savePlateInfo[0]},置信度:{savePlateInfo[1]},保存路径:{save_path}")
camPlateInfoRecordTime[camIps[i]] = None # 清空时间记录
camPlateInfoRecord[camIps[i]] = [] # 清空车牌记录
# 显示FPS
fps_time = time.time()-beginTime
if(fps_time > 0):
video_fps = int(1/fps_time)
print(f'{fps_time:.3f}s'+" fps= %.2f"%(video_fps))
#进行跳帧休眠处理
loopTime = int(round(fps_time * 1000))
if loopTime < 40*frameSkip:
time.sleep(0.04*frameSkip-loopTime/1000)
except BaseException:
logger.error("处理时出错!"+traceback.format_exc())
time.sleep(1)代码解释:
1)、frameSkip = 5 ,我这里使用了跳帧方式去识别所读取到的视频流,主要是避免过多过快的车牌识别检测导致的CPU过高或者其他系统性能问题,一般情况下每5帧识别一次已经足够,可根据自身需求进行调整。
2)、车牌真实性判断逻辑,我这里是当车牌的置信度大于0.8则保存该帧的车牌信息及图像,当该视频流2s内不再出现大于0.8置信度的车牌时,保存图像及车牌信息至文件夹中。该逻辑可根据自身需求进行修改代码,例如通过有效帧次数来保存识别最佳的车牌信息等。
其他文件:
config.json
{
"192.168.**.**": {"id":"XXX001","rtspUrl":"相机的RTSP地址"}
}plateUtil.py
from hyperlpr3.common.typedef import *
def get_plate_color(plate_type):
plateColor = "蓝"
if plate_type == UNKNOWN:
plateColor = '未知'
elif plate_type == BLUE:
plateColor = "蓝"
elif plate_type == YELLOW_SINGLE:
plateColor = "黄"
elif plate_type == WHILE_SINGLE:
plateColor = "白"
elif plate_type == GREEN:
plateColor = "绿"
return plateColor6、使用OpenVINO检测车牌框
pip install openvino6.1 转换为OpenVINO格式的模型文件
onnx2openvino.py
# coding:UTF-8
import os
import openvino as ov
# 定义 ONNX 模型路径
onnx_model_path = "y5fu_320x_sim.onnx"
# 定义输出目录路径
output_dir = "./openvino"
# 检查输出目录是否存在,如果不存在则创建
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"Created output directory at: {output_dir}")
else:
print(f"Output directory already exists at: {output_dir}")
# 设置模型转换参数
try:
# 转换 ONNX 模型为 OpenVINO 格式
ov_model = ov.convert_model(onnx_model_path)
# 保存 OpenVINO 模型
ir_path = './openvino/y5fu_320x_sim.xml'
ov.save_model(ov_model, ir_path)
print(f"Model successfully converted and saved to: {output_dir}")
except Exception as e:
print(f"Error during model conversion: {e}")执行后即可得到OpenVINO推理文件
6.2、添加OpenVINO推理类
找到 hyperlpr3\inference\multitask_detect.py
添加:
class MultiTaskDetectorOpenVINO(HamburgerABC):
def __init__(self, openvino_path, box_threshold: float = 0.5, nms_threshold: float = 0.6, *args, **kwargs):
super().__init__(*args, **kwargs)
import openvino as ov
self.box_threshold = box_threshold
self.nms_threshold = nms_threshold
# 👇Create OpenVINO Core
core = ov.Core()
# 👇读取模型
self.model = core.read_model(model=openvino_path, weights=openvino_path.replace(".xml", ".bin"))
# 👇加载模型,如果用intel的显卡就把CPU改成GPU,但是要确保你的显卡驱动安装好
self.compiled_model = core.compile_model(model=self.model, device_name="CPU")
self.inputs_option = self.model.input(0)
self.outputs_option = self.model.output(0)
#input_option = self.inputs_option[0]
input_size_ = tuple(self.inputs_option.shape[2:])
self.input_size = tuple(self.input_size)
if not self.input_size:
self.input_size = input_size_
assert self.input_size == input_size_, 'The dimensions of the input do not match the model expectations.'
assert self.input_size[0] == self.input_size[1]
self.input_name = self.inputs_option.names
def _run_session(self, data):
result = self.compiled_model(data)[0]
return result
def _postprocess(self, data):
r, left, top = self.tmp_pack
return post_precessing(data, r, left, top)
def _preprocess(self, image):
img, r, left, top = detect_pre_precessing(image, self.input_size)
self.tmp_pack = r, left, top
return img6.3、添加OpenVINO推理方法
找到 hyperlpr3\hyperlpr3.py
from .config.settings import onnx_runtime_config as ort_cfg
from .inference.pipeline import LPRMultiTaskPipeline
from .common.typedef import *
from os.path import join
from .config.settings import _DEFAULT_FOLDER_
from .config.configuration import initialization
initialization()
class LicensePlateCatcher(object):
def __init__(self,
detect_inference: int = INFER_ONNX_RUNTIME,
inference: int = INFER_ONNX_RUNTIME,
folder: str = _DEFAULT_FOLDER_,
detect_level: int = DETECT_LEVEL_LOW,
logger_level: int = 3,
full_result: bool = False):
if inference == INFER_ONNX_RUNTIME:
from hyperlpr3.inference.recognition import PPRCNNRecognitionORT
from hyperlpr3.inference.classification import ClassificationORT
import onnxruntime as ort
ort.set_default_logger_severity(logger_level)
if detect_level == DETECT_LEVEL_LOW:
if detect_inference == INFER_ONNX_RUNTIME:
from hyperlpr3.inference.multitask_detect import MultiTaskDetectorORT
det = MultiTaskDetectorORT(join(folder, ort_cfg['det_model_path_320x']), input_size=(320, 320))
elif detect_inference == INFER_OPENVINO:
from hyperlpr3.inference.multitask_detect import MultiTaskDetectorOpenVINO
det = MultiTaskDetectorOpenVINO('./openvino/y5fu_320x_sim.xml', input_size=(320, 320))
elif detect_inference == INFER_NCNN:
from hyperlpr3.inference.multitask_detect import MultiTaskDetectorNCNN
det = MultiTaskDetectorNCNN('./ncnn/y5fu_320x_sim.ncnn.bin', input_size=(320, 320))
elif detect_level == DETECT_LEVEL_HIGH:
det = MultiTaskDetectorORT(join(folder, ort_cfg['det_model_path_640x']), input_size=(640, 640))
else:
raise NotImplemented
rec = PPRCNNRecognitionORT(join(folder, ort_cfg['rec_model_path']), input_size=(48, 160))
cls = ClassificationORT(join(folder, ort_cfg['cls_model_path']), input_size=(96, 96))
self.pipeline = LPRMultiTaskPipeline(detector=det, recognizer=rec, classifier=cls, full_result=full_result)
else:
raise NotImplemented
def __call__(self, image: np.ndarray, *args, **kwargs):
return self.pipeline(image)
6.4、设置为OpenVINO推理
plateRecognizer.py 中
catcher = lpr3.LicensePlateCatcher(detect_inference=INFER_OPENVINO) # detect_level=lpr3.DETECT_LEVEL_HIGH7、使用NCNN检测车牌框
7.1、转换为NCNN格式的模型文件
注意:网上大部分都是说要下载protobuf和ncnn源码进行编译,再使用onnx2ncnn.exe进行转换,实际验证该方法对onnx转换为ncnn格式时,会报错误Unsupported slice axes !。
建议使用pnnx方式直接转换。
pip install pnnxpnnx y5fu_320x_sim.onnx inputshape=[1,3,320,320]执行后会生成一堆文件,选择ncnn的两个文件即可
在项目根目录新建一个ncnn文件夹,并上述两个模型文件放入。
7.2、添加NCNN推理类
找到 hyperlpr3\inference\multitask_detect.py
添加:
import ncnn
class MultiTaskDetectorNCNN(HamburgerABC):
def __init__(self, ncnn_path, box_threshold: float = 0.5, nms_threshold: float = 0.6, *args, **kwargs):
super().__init__(*args, **kwargs)
self.box_threshold = box_threshold
self.nms_threshold = nms_threshold
# 加载ncnn模型
self.net = ncnn.Net()
self.net.opt.use_vulkan_compute = False
self.net.load_param(ncnn_path.replace(".bin", ".param"))
self.net.load_model(ncnn_path)
self.input_size = (320,320)
def _run_session(self, data):
input_data = ncnn.Mat(data[0])
# 创建提取器
extractor = self.net.create_extractor()
extractor.input("in0", input_data)
# 执行推理
ret1, mat_out1 = extractor.extract("out0")
# 处理输出
result = np.expand_dims(np.array(mat_out1), axis=0)
return result
def _postprocess(self, data):
r, left, top = self.tmp_pack
return post_precessing(data, r, left, top)
def _preprocess(self, image):
img, r, left, top = detect_pre_precessing(image, self.input_size)
self.tmp_pack = r, left, top
return img7.3、添加NCNN推理方法
同6.3
7.4、设置为NCNN推理
plateRecognizer.py 中
catcher = lpr3.LicensePlateCatcher(detect_inference=INFER_NCNN) # detect_level=lpr3.DETECT_LEVEL_HIGH8、ONNX、OpenVINO、NCNN 推理速度记录(包含预处理和后处理)
本人电脑硬件如下:
内存:16G
CPU:AMD Ryzen 5 4600U with Radeon Graphics 2.10 GHz
无独立显卡
输入视频流大小:1920*1080
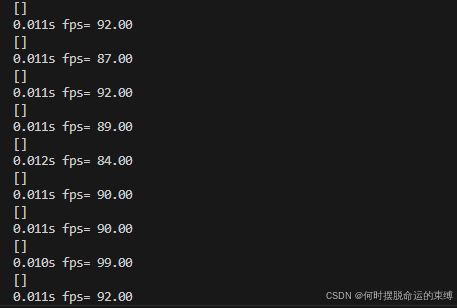
8.1、在ONNX下的单帧车牌框检测速度
8.2、在OpenVINO下的单帧车牌框检测速度

不太稳定。。。。
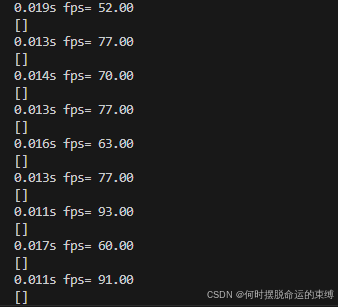
8.3、在NCNN下的单帧车牌框检测速度
9、打包成exe可执行文件进行部署
9.1、安装auto-py-to-exe
pip install auto-py-to-exe
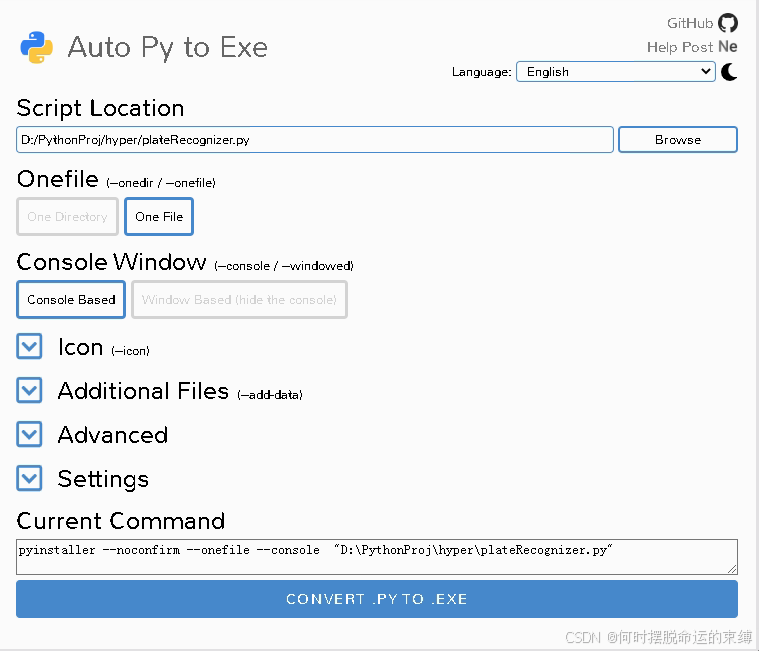
auto-py-to-exe9.2、部署ONNX推理方式
注意:不包含ncnn部分的代码可以直接打包
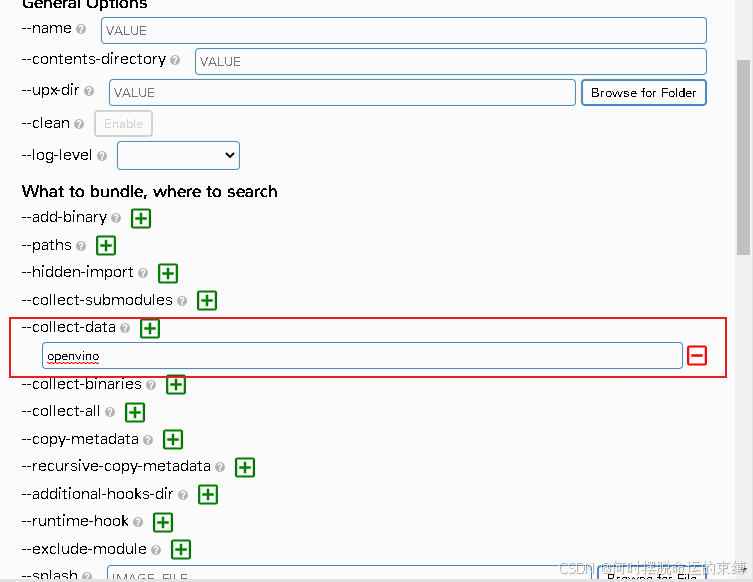
9.3、部署OpenVINO推理方式
其余一致,需在--collect-data添加openvino
9.4、部署NCNN推理方式
与9.2一样直接打包可能执行会出现错误:
Library not found: could no resolve或者显示ncnn的DLL load的问题
需要打开你的python环境所在目录找到 Lib\site-packages\ncnn.libs,将里面的DLL复制到Lib同一层目录下

再次打包即可通过并正常运行
10、结语
本人实际测试中,将上述车牌识别代码在Win732位下也部署了一套,其中OpenVINO因为不支持win7无法部署,实测发现ncnn的推理速度大概是onnx的1.5倍左右,并且ncnn推理占用CPU资源也比较低。

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









