







趁着有空去看了一波valse,和很多论文的作者当面讨论了一些问题,在此主要记录对一些paper的见解。
1. FishNet: A Versatile Backbone for Image, Region, and Pixel Level Prediction
根据欧阳万里老师介绍,这篇文章起初的motivation是希望将hourglass结构引入到分类网络中,看有没有效果,实验表明没什么效果,考虑去掉最后的上采样阶段,使用1.5个hourglass式结构,也即本文提出的fishnet。文章中写的motivation是为cls,det,seg设计一个统一的backbone。
Abstract中有句话说的很好there is seldom backbone structure designed under the consideration of unifying the advantages of networks designed for pixellevel or region-level predicting tasks, which may require very deep features with high resolution,可以看出对于region-level, pix-level的task,需要高分辨率且高语义的feature,同样的思想应用在王井东老师的一篇姿态估计的文章HRNet中(下面也会有介绍)。
抛却最后一个上采样过程不看,其实fishnet和fpn总体还是很相似的,不一样的地方主要在横向连接。FPN对两个level的feature进行conv后再concat,然后传给下一个level, fishnet则直接将两个level的feature直接concat,然后对concat后的feature进行图示操作,M表示一个残差网络,r是一个channel维度的pooling,其实就是用k个channel当前位置的响应值和代替当前值。因为是直接concat,所以不存在高level和低level之间information的交错(分辨率的提升注定channel降,因为计算量)。fishnet中还有一个细节就是,不管在fish的哪个部位,传递特征的都是concat层的feature,所以整个网络的gradient传播效果很好。
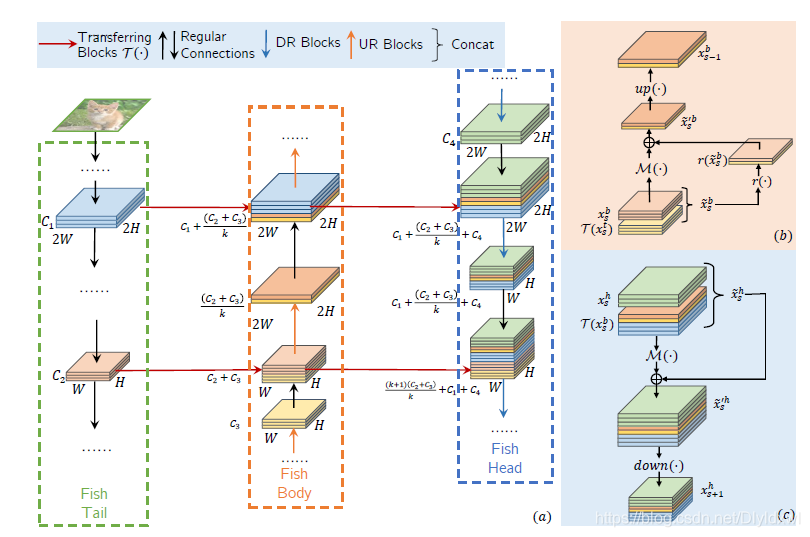
conclusion:1. 欧阳万里老师其实并没有解释为什么hg的最后一个上采样结构对cls不友好,这是可以挖掘的一个点;
2. hg结构已经在多个task上展露风采,有取代resnet的趋势;
3. 高分辨率高语义的feature怎么更有效的获得?
2. Deep High-Resolution Representation Learning for Human Pose Estimation
王井东老师也是在workshop中力推了这篇文章,而且一做Ke Sun在poster环节也展示了这篇论文。
论文的motivation还是很easy的,我们就是想要获得高分辨率高语义的feature。现有的大部分方法,基于hourglass都是从low-resolution的feature中恢复到high-resolution,在恢复过程中难免会有一些问题,这也是必然的,那很显然的就是说能不能一直保留high resolution的feature,贯穿整个cnn model。

盗用王井东老师的一张PPT,网络的结构大致如上图所示,在每个stage结束后,每个分辨率的feature都是由现有的所有的分辨率的feature共同获得的,上采样用最近邻和1*1conv, 下采样用3*3s=2,ke sun说上下采样他们自己试过很多方法,包括pooling,billnear等,发现这样设置是最好用的。当用于pose时,合并最后一个stage的所有feature得到高分辨的feature,用于最后的检测。做detection时,用合并到的最后的high-resolution的feature下采样产生一组不同scale的feature,构成feature pyramid.网络整个flops不会太大,因为高分辨率的feature channel很少,合并不同分辨率的feature用的sum,不是concat, 不改变channel数目。其实个人估计网络的速度也不会太快,因为高分辨率的feature太多了,会导致mac很高,从而降低速度(参考shufflenet v2),而且网络中的连接太多。
conclusion: 1.其实HRNet的motivation真的不要太简单,但是在性能上也不要太work,很棒的工作~ 从结构上看HRNet更像是Unet的极限连接版。这么来说的话,是不是去反思一下以前的经典结构,来个rethink,可以发一篇顶会?哈哈哈;
2. 在应用到detection的时候,其实构造的fp各层的knowledge是不一样的,虽然现在的大尺度的feature也是high-level的,但是这没有触及到detection中的scale问题的本质,这是一个接下来想考虑的方向;
3. 类似于densenet的后续改进,hrnet中的这么多连接真的有必要吗?如何有效的去除冗余性。
3.FCOS: Fully Convolutional One-Stage Object Detection
这篇paper也是多次出现在valse2019的ppt上面,沈春华老师没有花太多时间介绍这份工作,所以在此贴出我自己读paper的一些想法。
作者首先分析了anchor-based检测器的缺点,一是精度极其依赖于anchor的设计(aspect-ratio,scale等参数),二是移植性能差,就是说不同的detection task中,需要的超参设置不一样,三是为了达到高recall,一般都需要设置大量的anchor,而这些anchor很多都是neg的,容易导致不平衡(dection中的不平衡主要有三点:pos:neg和hard:easy不平衡;ssd式的fp中的不同level的feature不平衡;multi-task之间的loss不平衡);四是大数量的anchors容易导致训练缓慢且内存消耗高,因为train需要计算所有的anchor和gt的IoU。所以引起了本文的motivation,能不能摒弃anchors,直接进行fcn式seg的det,这样也能从尽量统一不同task的framework。言外话,其实这篇文章的组大多都是做seg的--。
FCOS的做法很直接,对于feature map上的每个position,映射到image中,(映射方法和SSD一样,+0.5再*s),如果该点位于某个GT内,则认为其实pos样本。这样会导致两个问题:1. 高level feature的stride一般比较大,映射回原图后理论上会导致点之间很稀疏,从而recall很低;2. 一个点位于两个gt里面,又该怎么算。
实验表明,对于第一个问题,FCOS其实并不存在,不管是使用一个level还是FPN,它的recall并不低于retinanet, (话说这是为什么呢?作者并没有解释);第二个问题,作者现在的做法是对于公共区域的点,让它回归两个GT中小的GT。作者在文中花了大量篇幅来说明,引入FPN后,这个问题已经被大大减轻,几乎可以忽略。对于不同level feature,FCOS让它们负责回归一定范围大小的GT,这样就相当于把不同scale的GT指定到不同的feature了,大大减轻了这个问题。此外,在这个问题中,其实我们关注的是两个有重叠的GT,它们的label不一样,如果一样的话,随便回归哪一个其实是不影响的,实验数据显示,加入FPN后,这种不同类别的GT有重叠区域且被assign到同一个level仅占比3.75%。
实验过程中作者还发现了一个问题,远离GT中心的点容易回归出低质量的bbox,所以添加了Center-ness项到loss中,inference时将该值与类别置信度乘起来作为类别置信度用以后续的NMS等操作。具体的细节参考论文。
综上,本文通过回归不同level feature各个点到指定GT的四个点距离和类别置信度和Center-ness来实现最终的detction。loss有三项,分类采用focal loss,center-ness用BCE(二分类交叉熵,并不是说target一定是0,1才能用CE,比如说label smooth。一般来说target是0-1之间就可以),reg 采用IOU loss,类似于Unitbox。整体框架如下图,注意输出的维度。
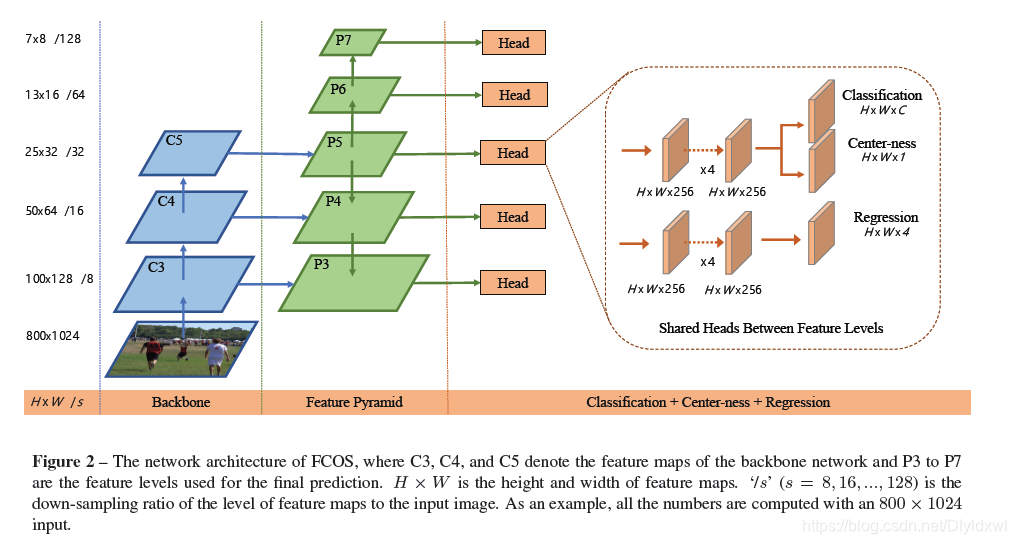
conclusion: 1. 个人觉得FCOS是把anchor-base转换为了position-base,降低了冗余性。其实对于实验中的pos:neg也还是有考究的必要的把?论文里面没说;
2. 针对不同的gt,根据每个level feature检测的大小范围对其进行assign。能不能借鉴FSAF中的思想呢?毕竟设置每个level的检测范围是一个hyber-paremeter;
3. 还是归结到尺度问题上,再用feature position来进行predict的时候个人觉得是更关注feature之间的平衡性的,FPN的特征显然没有触及到scale问题的本质,这是一个很诱人单也很难的方向。总的来说,现在anchor free肯定要相对来说好发文章一点,不管是移植到一些细分方向还是做改进。
4. center-ness确实是一个亮点的设计,美中不足的是作者并没有比较FCOS与retinanet的速度。















 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









