import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import *
from keras.preprocessing.sequence import pad_sequences
from keras.datasets import imdb
torch.__version__
MAX_WORDS = 10000 # 词汇表大小
MAX_LEN = 200 # 最大长度
BATCH_SIZE = 256
EMB_SIZE = 128 # embedding size
HID_SIZE = 128 # lstm hidden size
DROPOUT = 0.2
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 借助Keras加载imdb数据集
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=MAX_WORDS)
x_train = pad_sequences(x_train, maxlen=MAX_LEN, padding="post", truncating="post")
x_test = pad_sequences(x_test, maxlen=MAX_LEN, padding="post", truncating="post")
print(x_train.shape, x_test.shape)
# 转化为TensorDataset
train_data = TensorDataset(torch.LongTensor(x_train), torch.LongTensor(y_train))
test_data = TensorDataset(torch.LongTensor(x_test), torch.LongTensor(y_test))
# 转化为 DataLoader
train_sampler = RandomSampler(train_data)
train_loader = DataLoader(train_data, sampler=train_sampler, batch_size=BATCH_SIZE)
test_sampler = SequentialSampler(test_data)
test_loader = DataLoader(test_data, sampler=test_sampler, batch_size=BATCH_SIZE)
# 定义2层双向LSTM模型
class Model(nn.Module):
def __init__(self, max_words, emb_size, hid_size, dropout):
super(Model, self).__init__()
self.max_words = max_words
self.emb_size = emb_size
self.hid_size = hid_size
self.dropout = dropout
self.Embedding = nn.Embedding(self.max_words, self.emb_size)
self.LSTM = nn.LSTM(self.emb_size, self.hid_size, num_layers=2,
batch_first=True, bidirectional=True) # 2层双向LSTM
self.dp = nn.Dropout(self.dropout)
self.fc1 = nn.Linear(self.hid_size*2, self.hid_size)
self.fc2 = nn.Linear(self.hid_size, 2)
def forward(self, x):
x = self.Embedding(x)
x = self.dp(x)
x, _ = self.LSTM(x)
x = self.dp(x)
x = F.relu(self.fc1(x))
x = F.avg_pool2d(x, (x.shape[1], 1)).squeeze()
out = self.fc2(x)
return out
def train(model, device, train_loader, optimizer, epoch): # 训练模型
model.train()
criterion = nn.CrossEntropyLoss()
for batch_idx, (x, y) in enumerate(train_loader):
x, y = x.to(DEVICE), y.to(DEVICE)
optimizer.zero_grad()
y_ = model(x)
loss = criterion(y_, y) # 得到loss
loss.backward()
optimizer.step()
if(batch_idx + 1) % 10 == 0: # 打印loss
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(x), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader): # 测试模型
model.eval()
criterion = nn.CrossEntropyLoss(reduction='sum') # 累加loss
test_loss = 0.0
acc = 0
for batch_idx, (x, y) in enumerate(test_loader):
x, y = x.to(DEVICE), y.to(DEVICE)
with torch.no_grad():
y_ = model(x)
test_loss += criterion(y_, y)
pred = y_.max(-1, keepdim=True)[1]
acc += pred.eq(y.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(
test_loss, acc, len(test_loader.dataset),
100. * acc / len(test_loader.dataset)))
return acc / len(test_loader.dataset)
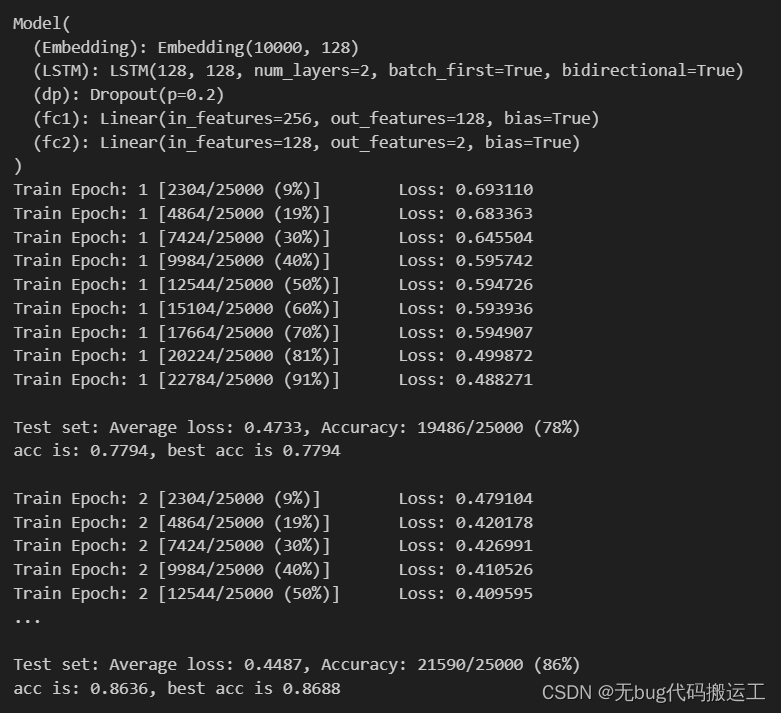
model = Model(MAX_WORDS, EMB_SIZE, HID_SIZE, DROPOUT).to(DEVICE)
print(model)
optimizer = optim.Adam(model.parameters())
best_acc = 0.0
PATH = 'imdb model/model.pth' # 定义模型保存路径
for epoch in range(1, 11): # 10个epoch
train(model, DEVICE, train_loader, optimizer, epoch)
acc = test(model, DEVICE, test_loader)
if best_acc < acc:
best_acc = acc
torch.save(model.state_dict(), PATH)
print("acc is: {:.4f}, best acc is {:.4f}\n".format(acc, best_acc))
# 检验保存的模型
best_model = Model(MAX_WORDS, EMB_SIZE, HID_SIZE, DROPOUT).to(DEVICE)
best_model.load_state_dict(torch.load(PATH))
test(best_model, DEVICE, test_loader)






















 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









