







Doc2X:PDF 转 Word 的最佳选择
Doc2X 专注于 PDF转Word、PDF转Latex、PDF转HTML,支持 Mathpix公式识别、多栏解析、GLM翻译 等强大功能,助您快速完成文档处理!
Doc2X: The Best Choice for PDF to Word Conversion
Doc2X specializes in PDF to Word, PDF to LaTeX, and PDF to HTML, with features like Mathpix formula recognition, multi-column parsing, and GLM translation, making document processing faster!
👉 立即试用 Doc2X | Try Doc2X Now
原文链接:https://arxiv.org/pdf/2404.19245
HydraLoRA: An Asymmetric LoRA Architecture for Efficient Fine-Tuning
HydraLoRA: 一种用于高效微调的不对称LoRA架构
Chunlin Tian † {}^{ \dagger } †
田春林 † {}^{ \dagger } †
University of Macau
澳门大学
yc27402@um.edu.mo
Zhan Shi † {}^{ \dagger } †
石展 † {}^{ \dagger } †
University of Texas at Austin
德克萨斯大学奥斯汀分校
zshi17@cs.utexas.edu
Zhijjiang Guo
郭志江
University of Cambridge
剑桥大学
zg283@cam.ac.uk
Li L i ∗ {\mathrm{ {Li}}}^{ * } Li∗
李 L i ∗ {\mathrm{ {Li}}}^{ * } Li∗
University of Macau
澳门大学
llili@um.edu.mo
Chengzhong Xu
徐成忠
University of Macau
澳门大学
czxu@um.edu.mo
Abstract
摘要
Adapting Large Language Models (LLMs) to new tasks through fine-tuning has been made more efficient by the introduction of Parameter-Efficient Fine-Tuning (PEFT) techniques, such as LoRA. However, these methods often underperform compared to full fine-tuning, particularly in scenarios involving complex datasets. This issue becomes even more pronounced in complex domains, highlighting the need for improved PEFT approaches that can achieve better performance. Through a series of experiments, we have uncovered two critical insights that shed light on the training and parameter inefficiency of LoRA. Building on these insights, we have developed HydraLoRA, a LoRA framework with an asymmetric structure that eliminates the need for domain expertise. Our experiments demonstrate that HydraLoRA outperforms other PEFT approaches, even those that rely on domain knowledge during the training and inference phases.
通过微调将大型语言模型(LLMs)适应新任务,由于引入了参数高效微调(PEFT)技术,如LoRA,效率得到了提高。然而,与全量微调相比,这些方法在处理复杂数据集时往往表现不佳。在复杂领域中,这一问题变得更加明显,突显了改进PEFT方法以实现更好性能的必要性。通过一系列实验,我们揭示了LoRA训练和参数效率低下的两个关键见解。基于这些见解,我们开发了HydraLoRA,这是一个具有非对称结构的LoRA框架,消除了对领域专业知识的需求。我们的实验表明,HydraLoRA优于其他PEFT方法,即使在训练和推理阶段依赖领域知识的方法也不例外。
1 Introduction
1 引言
Large Language Models (LLMs; [10, 3, 35, 45, 46, 31, 32]) are notably powerful, yet their training involves substantial expense. Adapting a single LLM for multiple downstream applications via fine-tuning has emerged as a prevalent method to cater to specific domain needs, balancing performance with practicality. This approach, however, faces a significant challenge due to the extensive memory and computational resources required for full fine-tuning (FFT), i.e., fine-tuning all billions of parameters. A solution to this has been the development of more selective adaptation techniques, involving modifying only a portion of the parameters or integrating external modules designed for new tasks. Key methodologies in this sphere include LoRA [17], Adaptors [36, 16, 30], and many other variants [24, 23, 9, 13, 51], all part of what can be generally termed as Parameter-Efficient Fine-tuning (PEFT). PEFT strategies are characterized by freezing the backbone model parameters while only a minimal number of task-specific parameters are introduced and fine-tuned. This method substantially boosts efficiency in the phases of fine-tuning and subsequent deployment, marking a significant advancement in the practical use of LLMs.
大型语言模型(LLMs;[10, 3, 35, 45, 46, 31, 32])具有显著的强大能力,但其训练涉及巨大的成本。通过微调将单个LLM适应于多个下游应用已成为一种普遍的方法,以满足特定领域需求,平衡性能与实用性。然而,这种方法面临一个重大挑战,即全量微调(FFT)所需的广泛内存和计算资源,即微调所有数十亿参数。对此,已经开发出更具选择性的适应技术,涉及仅修改部分参数或集成为新任务设计的外部模块。这一领域的主要方法包括LoRA [17]、Adaptors [36, 16, 30]及其许多其他变体 [24, 23, 9, 13, 51],这些方法通常被称为参数高效微调(PEFT)。PEFT策略的特点是冻结主干模型参数,同时仅引入和微调少量任务特定参数。这种方法在微调和后续部署阶段显著提高了效率,标志着LLMs实际应用的重大进步。
While fine-tuning a small subset of parameters offers a streamlined approach for domain adaptation, it’s well-recognized that model performance is closely tied to the number of parameters involved [21]. This intrinsic characteristic of methods like LoRA often results in them falling short of the FFT baseline, which updates all parameters, thereby creating a trade-off between efficiency and model quality. This issue of compromised quality in a low-parameter setting becomes even more pronounced in target domains characterized by complex sub-domains and diverse tasks. This situation presents a compelling research question:
尽管微调一小部分参数为领域适应提供了一种简化的方法,但众所周知,模型性能与涉及的参数数量密切相关 [21]。像LoRA这样的方法的这种内在特性往往导致它们无法达到FFT基线,后者更新所有参数,从而在效率和模型质量之间产生权衡。在具有复杂子领域和多样化任务的目标领域中,这种在低参数设置下质量受损的问题变得更加明显。这种情况提出了一个引人注目的研究问题:
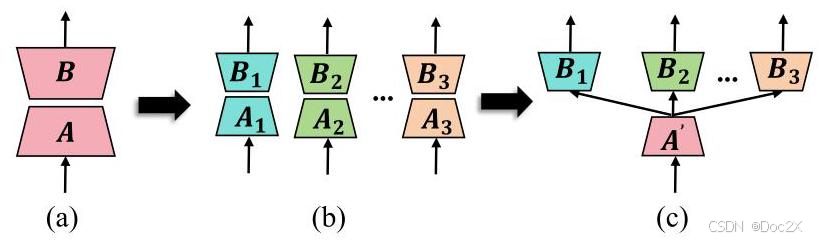
Figure 1: Illustration of LoRA architecture changes in HydraLoRA. Only the tunable parameters are shown in this Figure. (a) LoRA architecture with matrix A to achieve low rank and matrix B to recover. (b) under the same parameter count, a monolithic LoRA is split into multiple smaller A and B matrices to avoid training interference. © based on (b), HydraLoRA has an asymmetric structure that has a shared A matrix and multiple B matrices.
图1:HydraLoRA架构变化的示意图。本图中仅显示了可调参数。(a) LoRA架构,使用矩阵A实现低秩,矩阵B用于恢复。(b) 在相同参数数量下,单个LoRA被拆分为多个较小的A和B矩阵,以避免训练干扰。© 基于(b),HydraLoRA具有不对称结构,共享一个A矩阵和多个B矩阵。
What is the optimal architecture that can deliver superior model performance while still capitalizing on the efficiency benefits of a reduced parameter footprint?
什么样的架构能够在保持参数减少带来的效率优势的同时,提供卓越的模型性能?
In our research, we carry out a series of exploratory experiments, applying LoRA to the LLaMA2 [46] model to adapt it to a new domain encompassing multiple downstream tasks. As shown in Figure 1(a), LoRA adds trainable pairs of rank decomposition matrices A and B in addition to existing weight matrices. Our in-depth analysis of LoRA’s mechanics yields several insightful observations and leads to the formulation of key hypotheses. First, rather than employing a single LoRA for the entire domain, it proves more effective to deploy multiple, smaller LoRA heads, each dedicated to a specific downstream task (see Figure 1(b)). This suggests that domain or task interference might harmfully impact the training process. We further hypothesize that this interference originates from “intrinsic components”—sub-domains or distinct tasks—potentially unknown even to domain experts. Additionally, upon visualizing the parameters of LoRA, we discern a pattern: some parameters predominantly learn the commonalities across all data, while others focus on the unique aspects of each intrinsic component. From these observations, we posit that an optimal LoRA architecture should embody an explicit, asymmetric structure.
在我们的研究中,我们进行了一系列探索性实验,将LoRA应用于LLaMA2 [46]模型,以使其适应包含多个下游任务的新领域。如图1(a)所示,LoRA在现有权重矩阵之外添加了可训练的秩分解矩阵A和B对。我们对LoRA机制的深入分析得出了几个有见地的观察结果,并形成了关键假设。首先,与在整个领域使用单一LoRA相比,部署多个针对特定下游任务的小型LoRA头更为有效(见图1(b))。这表明领域或任务干扰可能对训练过程产生有害影响。我们进一步假设,这种干扰源于“内在成分”——子领域或不同任务——这些成分甚至对领域专家来说也可能是未知的。此外,在可视化LoRA参数时,我们发现了一种模式:一些参数主要学习所有数据中的共性,而另一些则专注于每个内在成分的独特方面。基于这些观察,我们提出,最优的LoRA架构应体现明确的非对称结构。
Building upon the observations, we propose an improved end-to-end LoRA framework, which we refer to as HydraLoRA. From the architecture perspective, unlike LoRA’s symmetric structure, HydraLoRA has an asymmetric structure that has a shared A matrix and multiple B matrices (see Figure 1©). The shared A matrix is used by all samples for parameter efficiency. During the fine-tuning phase, HydraLoRA is designed to autonomously identify “intrinsic components” and segregate training samples into distinct B matrices. During the inference phase, HydraLoRA leverages multiple B matrices using Mixture-of-Experts (MoE; [19, 39]) manner. Unlike prior work, HydraLoRA completely eliminates the need for human expertise and assumptions, showing better performance than using domain knowledge to guide the fine-tuning process.
基于这些观察,我们提出了一种改进的端到端 LoRA 框架,我们称之为 HydraLoRA。从架构角度来看,与 LoRA 的对称结构不同,HydraLoRA 具有一种非对称结构,它有一个共享的 A 矩阵和多个 B 矩阵(见图 1©)。共享的 A 矩阵用于所有样本以提高参数效率。在微调阶段,HydraLoRA 旨在自主识别“内在成分”并将训练样本分离到不同的 B 矩阵中。在推理阶段,HydraLoRA 利用多个 B 矩阵采用混合专家(MoE; [19, 39])的方式。与先前的工作不同,HydraLoRA 完全消除了对人类专业知识和假设的需求,显示出比使用领域知识指导微调过程更好的性能。
2 Background and Motivation
2 背景与动机
2.1 LoRA Basics
2.1 LoRA 基础
LoRA [17] achieves comparable performances to fine-tuning on many benchmarks by freezing the pre-trained model weights
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









