







选择 Doc2X,让 PDF 转换更轻松
支持 PDF 转 Word、Latex、Markdown,多栏与公式精准解析,还提供深度翻译功能,适合科研及日常办公!
Choose Doc2X, Simplify PDF Conversion
Supports PDF to Word, LaTeX, and Markdown, with precise multi-column and formula parsing, plus advanced translation for research and daily work!
👉 立即试用 Doc2X | Try Doc2X Now
原文链接:https://arxiv.org/pdf/1405.0312
Microsoft COCO: Common Objects in Context
Microsoft COCO:上下文中的常见对象
Tsung-Yi Lin Michael Maire James Hays Pietro Perona
林俊义 迈克尔·梅尔 詹姆斯·海斯 皮耶罗·佩罗纳
Abstract-We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328 k {328}\mathrm{k} 328k images,the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
摘要——我们提出了一个新的数据集,旨在通过将对象识别问题置于场景理解的更广泛问题中来推进对象识别的最新技术。这是通过收集包含自然上下文中常见对象的复杂日常场景图像来实现的。对象使用实例分割进行标记,以帮助精确的对象定位。我们的数据集包含91种对象类型的照片,这些对象类型可以被4岁的孩子轻松识别。在 328 k {328}\mathrm{k} 328k张图像中总共标记了250万个实例,我们数据集的创建得益于通过新颖的用户界面进行类别检测、实例发现和实例分割的大量众包工作者参与。我们详细统计分析了该数据集与PASCAL、ImageNet和SUN的比较。最后,我们使用可变形部件模型为边界框和分割检测结果提供了基线性能分析。
1 INTRODUCTION
1 引言
One of the primary goals of computer vision is the understanding of visual scenes. Scene understanding involves numerous tasks including recognizing what objects are present, localizing the objects in 2D and 3D, determining the objects’ and scene’s attributes, characterizing relationships between objects and providing a semantic description of the scene. The current object classification and detection datasets [1], [2], [3], [4] help us explore the first challenges related to scene understanding. For instance the ImageNet dataset [1], which contains an unprecedented number of images, has recently enabled breakthroughs in both object classification and detection research [5], [6], [7]. The community has also created datasets containing object attributes [8], scene attributes [9], keypoints [10], and 3D scene information [11]. This leads us to the obvious question: what datasets will best continue our advance towards our ultimate goal of scene understanding?
计算机视觉的主要目标之一是理解视觉场景。场景理解涉及众多任务,包括识别存在哪些对象、在2D和3D中定位对象、确定对象和场景的属性、描述对象之间的关系以及提供场景的语义描述。当前的对象分类和检测数据集[1]、[2]、[3]、[4]帮助我们探索与场景理解相关的第一个挑战。例如,包含前所未有的图像数量的ImageNet数据集[1],最近在对象分类和检测研究中实现了突破[5]、[6]、[7]。社区还创建了包含对象属性[8]、场景属性[9]、关键点[10]和3D场景信息[11]的数据集。这使我们自然而然地提出一个问题:哪些数据集将最好地继续推进我们实现场景理解最终目标的进展?
We introduce a new large-scale dataset that addresses three core research problems in scene understanding: detecting non-iconic views (or non-canonical perspectives [12]) of objects, contextual reasoning between objects and the precise 2D localization of objects. For many categories of objects, there exists an iconic view. For example, when performing a web-based image search for the object category “bike,” the top-ranked retrieved examples appear in profile, unobstructed near the center of a neatly composed photo. We posit that current recognition systems perform fairly well on iconic views, but struggle to recognize objects otherwise - in the background, partially occluded, amid clutter [13] - reflecting the composition of actual everyday scenes. We verify this experimentally; when evaluated on everyday scenes, models trained on our data perform better than those trained with prior datasets. A challenge is finding natural images that contain multiple objects. The identity of many objects can only be resolved using context, due to small size or ambiguous appearance in the image. To push research in contextual reasoning, images depicting scenes [3] rather than objects in isolation are necessary. Finally, we argue that detailed spatial understanding of object layout will be a core component of scene analysis. An object’s spatial location can be defined coarsely using a bounding box [2] or with a precise pixel-level segmentation [14], [15], [16]. As we demonstrate, to measure either kind of localization performance it is essential for the dataset to have every instance of every object
我们引入了一个新的、大规模的数据集,该数据集解决了场景理解中的三个核心研究问题:检测物体的非典型视角(或非规范视角 [12])、物体之间的上下文推理以及物体的精确二维定位。对于许多物体类别,存在一个典型的视角。例如,当执行基于网络的“自行车”类别图像搜索时,排名靠前的检索示例通常以侧面视角出现,位于一张构图整洁的照片的中心附近,且不受遮挡。我们认为,当前的识别系统在典型视角上表现良好,但在其他情况下(如背景中、部分遮挡、杂乱环境中)识别物体时表现不佳,这反映了实际日常场景的构成。我们通过实验验证了这一点;在日常场景中进行评估时,使用我们数据集训练的模型比使用先前数据集训练的模型表现更好。一个挑战是找到包含多个物体的自然图像。由于物体尺寸小或图像中外观模糊,许多物体的身份只能通过上下文来确定。为了推动上下文推理的研究,有必要使用描绘场景 [3] 而不是孤立物体的图像。最后,我们认为,对物体布局的详细空间理解将是场景分析的核心组成部分。物体的空间位置可以用边界框 [2] 粗略定义,或用精确的像素级分割 [14]、[15]、[16] 定义。正如我们所展示的,为了衡量任何一种定位性能,数据集必须包含每个物体的每个实例。
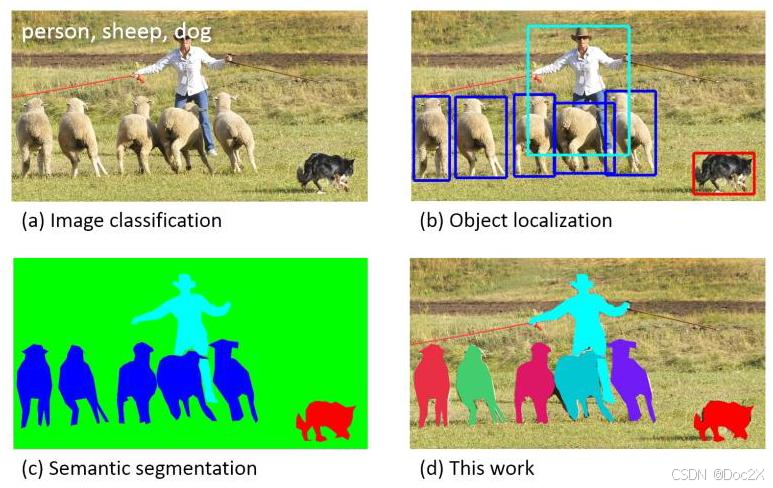
Fig. 1: While previous object recognition datasets have focused on (a) image classification, (b) object bounding box localization or © semantic pixel-level segmentation, we focus on (d) segmenting individual object instances. We introduce a large, richly-annotated dataset comprised of images depicting complex everyday scenes of common objects in their natural context.
图1:虽然先前的物体识别数据集主要关注(a)图像分类、(b)物体边界框定位或(c)语义像素级分割,但我们关注(d)分割单个物体实例。我们引入了一个大型、丰富注释的数据集,该数据集由描绘常见物体在自然上下文中的复杂日常场景的图像组成。
-
T.Y. Lin and S. Belongie are with Cornell NYC Tech and the Cornell Computer Science Department.
-
T.Y. Lin 和 S. Belongie 来自康奈尔大学纽约理工学院和康奈尔大学计算机科学系。
-
M. Maire is with the Toyota Technological Institute at Chicago.
-
M. Maire 任职于芝加哥丰田理工学院。
-
L. Bourdev and P. Dollár are with Facebook AI Research. The majority of this work was performed while P. Dollár was with Microsoft Research. R. Girshick and C. L. Zitnick are with Microsoft Research, Redmond.
-
L. Bourdev 和 P. Dollár 任职于 Facebook AI 研究。这项工作的大部分是在 P. Dollár 任职于微软研究院期间完成的。R. Girshick 和 C. L. Zitnick 任职于微软研究院,雷德蒙德。
J. Hays is with Brown University.
J. Hays 任职于布朗大学。
-
P. Perona is with the California Institute of Technology.
-
P. Perona 任职于加州理工学院。
-
D. Ramanan is with the University of California at Irvine.
-
D. Ramanan 任职于加州大学欧文分校。
category labeled and fully segmented. Our dataset is unique in its annotation of instance-level segmentation masks, Fig. 1.
类别标注并完全分割。我们的数据集在其实例级分割掩码的标注上具有独特性,如图1所示。
To create a large-scale dataset that accomplishes these three goals we employed a novel pipeline for gathering data with extensive use of Amazon Mechanical Turk. First and most importantly, we harvested a large set of images containing contextual relationships and non-iconic object views. We accomplished this using a surprisingly simple yet effective technique that queries for pairs of objects in conjunction with images retrieved via scene-based queries [17], [3]. Next, each image was labeled as containing particular object categories using a hierarchical labeling approach [18]. For each category found, the individual instances were labeled, verified, and finally segmented. Given the inherent ambiguity of labeling, each of these stages has numerous tradeoffs that we explored in detail.
为了创建一个实现这三个目标的大规模数据集,我们采用了一种新颖的流水线来收集数据,广泛使用了亚马逊土耳其机器人。首先也是最重要的是,我们收集了大量包含上下文关系和非典型物体视图的图像。我们通过一种出乎意料的简单但有效的方法实现了这一点,该方法查询物体对,并结合通过基于场景的查询检索到的图像 [17], [3]。接下来,每张图像都使用层次化标注方法 [18] 标注为包含特定物体类别。对于每个发现的类别,标注了各个实例,验证并最终分割。鉴于标注的固有模糊性,每个阶段都有许多权衡,我们对此进行了详细探讨。
The Microsoft Common Objects in COntext (MS COCO) dataset contains 91 common object categories with 82 of them having more than 5,000 labeled instances, Fig. 6. In total the dataset has 2,500,000 labeled instances in 328,000 images. In contrast to the popular ImageNet dataset [1], COCO has fewer categories but more instances per category. This can aid in learning detailed object models capable of precise 2D localization. The dataset is also significantly larger in number of instances per category than the PASCAL VOC [2] and SUN [3] datasets. Additionally, a critical distinction between our dataset and others is the number of labeled instances per image which may aid in learning contextual information, Fig. 5. MS COCO contains considerably more object instances per image (7.7) as compared to ImageNet (3.0) and PASCAL (2.3). In contrast, the SUN dataset, which contains significant contextual information, has over 17 objects and “stuff” per image but considerably fewer object instances overall.
Microsoft 上下文中的常见对象 (MS COCO) 数据集包含 91 个常见对象类别,其中 82 个类别拥有超过 5,000 个标注实例,如图 6 所示。该数据集总共包含 328,000 张图像中的 2,500,000 个标注实例。与流行的 ImageNet 数据集 [1] 相比,COCO 的类别较少,但每个类别中的实例更多。这有助于学习能够进行精确 2D 定位的详细对象模型。该数据集在每个类别中的实例数量上也显著大于 PASCAL VOC [2] 和 SUN [3] 数据集。此外,我们数据集与其他数据集之间的一个关键区别是每张图像中标注实例的数量,这可能有助于学习上下文信息,如图 5 所示。MS COCO 每张图像中的对象实例数量(7.7)明显多于 ImageNet(3.0)和 PASCAL(2.3)。相比之下,包含大量上下文信息的 SUN 数据集每张图像中有超过 17 个对象和“东西”,但总体上对象实例数量较少。
An abridged version of this work appeared in [19].
这项工作的简略版本已在 [19] 中发表。
2 Related Work
2 相关工作
Throughout the history of computer vision research datasets have played a critical role. They not only provide a means to train and evaluate algorithms, they drive research in new and more challenging directions. The creation of ground truth stereo and optical flow datasets [20], [21] helped stimulate a flood of interest in these areas. The early evolution of object recognition datasets [22], [23], [24] facilitated the direct comparison of hundreds of image recognition algorithms while simultaneously pushing the field towards more complex problems. Recently, the ImageNet dataset [1] containing millions of images has enabled breakthroughs in both object classification and detection research using a new class of deep learning algorithms [5], [6], [7].
在整个计算机视觉研究的历史中,数据集一直扮演着关键角色。它们不仅提供了训练和评估算法的手段,还推动了研究向新的、更具挑战性的方向发展。地面实况立体和光流数据集的创建 [20], [21] 激发了人们对这些领域的浓厚兴趣。早期对象识别数据集的发展 [22], [23], [24] 促进了数百种图像识别算法的直接比较,同时推动了该领域向更复杂问题的研究。最近,包含数百万张图像的 ImageNet 数据集 [1] 通过使用一类新的深度学习算法 [5], [6], [7],在对象分类和检测研究方面取得了突破。
Datasets related to object recognition can be roughly split into three groups: those that primarily address object classification, object detection and semantic scene labeling. We address each in turn.
与物体识别相关的数据集大致可以分为三类:主要解决物体分类、物体检测和语义场景标注的数据集。我们将逐一讨论这些数据集。
Image Classification The task of object classification requires binary labels indicating whether objects are present in an image; see Fig. 1(a). Early datasets of this type comprised images containing a single object with blank backgrounds, such as the MNIST handwritten digits [25] or COIL household objects [26]. Caltech 101 [22] and Caltech 256 [23] marked the transition to more realistic object images retrieved from the internet while also increasing the number of object categories to 101 and 256, respectively. Popular datasets in the machine learning community due to the larger number of training examples, CIFAR-10 and CIFAR-100 [27] offered 10 and 100 categories from a dataset of tiny 32 × 32 images [28]. While these datasets contained up to 60,000 images and hundreds of categories, they still only captured a small fraction of our visual world.
图像分类 物体分类任务需要二进制标签来指示图像中是否存在物体;参见图1(a)。早期这类数据集包括包含单个物体且背景空白的图像,例如MNIST手写数字[25]或COIL家用物体[26]。Caltech 101[22]和Caltech 256[23]标志着从互联网获取更真实物体图像的转变,同时分别将物体类别数量增加到101和256。由于训练样本数量较多,CIFAR-10和CIFAR-100[27]在机器学习社区中广受欢迎,它们提供了从32×32小图像数据集中提取的10和100个类别[28]。尽管这些数据集包含多达60,000张图像和数百个类别,但它们仍然只捕捉了我们视觉世界的一小部分。
Recently, ImageNet [1] made a striking departure from the incremental increase in dataset sizes. They proposed the creation of a dataset containing 22 k {22}\mathrm{k} 22k categories with 500-1000 images each. Unlike previous datasets containing entry-level categories [29], such as “dog” or “chair,” like [28], ImageNet used the WordNet Hierarchy [30] to obtain both entry-level and fine-grained [31] categories. Currently, the ImageNet dataset contains over 14 million labeled images and has enabled significant advances in image classification [5], [6], [7].
最近,ImageNet[1]在数据集规模上的增加上做出了显著的突破。他们提出了创建一个包含 22 k {22}\mathrm{k} 22k个类别、每个类别有500-1000张图像的数据集。与之前包含入门级类别[29](如“狗”或“椅子”)的数据集[28]不同,ImageNet使用了WordNet层次结构[30]来获取入门级和细粒度[31]类别。目前,ImageNet数据集包含超过1400万张标注图像,并推动了图像分类领域的显著进展[5]、[6]、[7]。
Object detection Detecting an object entails both stating that an object belonging to a specified class is present, and localizing it in the image. The location of an object is typically represented by a bounding box, Fig. 1(b). Early algorithms focused on face detection [32] using various ad hoc datasets. Later, more realistic and challenging face detection datasets were created [33]. Another popular challenge is the detection of pedestrians for which several datasets have been created [24], [4]. The Caltech Pedestrian Dataset [4] contains 350,000 labeled instances with bounding boxes.
目标检测 检测一个对象既包括声明存在属于指定类别的对象,也包括在图像中对其进行定位。对象的位置通常由边界框表示,如图1(b)所示。早期的算法主要关注使用各种临时数据集进行人脸检测[32]。后来,创建了更现实和更具挑战性的人脸检测数据集[33]。另一个流行的挑战是行人检测,为此已经创建了多个数据集[24], [4]。Caltech行人数据集[4]包含350,000个带有边界框的标注实例。
For the detection of basic object categories, a multiyear effort from 2005 to 2012 was devoted to the creation and maintenance of a series of benchmark datasets that were widely adopted. The PASCAL VOC [2] datasets contained 20 object categories spread over 11,000 images. Over 27,000 object instance bounding boxes were labeled, of which almost 7,000 had detailed segmentations. Recently, a detection challenge has been created from 200 object categories using a subset of 400,000 images from ImageNet [34]. An impressive 350,000 objects have been labeled using bounding boxes.
对于基本对象类别的检测,从2005年到2012年,人们致力于创建和维护一系列广泛采用的基准数据集。PASCAL VOC[2]数据集包含分布在11,000张图像中的20个对象类别。标注了超过27,000个对象实例边界框,其中近7,000个具有详细的分割。最近,使用ImageNet[34]中400,000张图像的子集创建了一个包含200个对象类别的检测挑战。已经使用边界框标注了令人印象深刻的350,000个对象。
Since the detection of many objects such as sunglasses, cellphones or chairs is highly dependent on contextual information, it is important that detection datasets contain objects in their natural environments. In our dataset we strive to collect images rich in contextual information. The use of bounding boxes also limits the accuracy for which detection algorithms may be evaluated. We propose the use of fully segmented instances to enable more accurate detector evaluation.
由于检测许多对象(如太阳镜、手机或椅子)高度依赖于上下文信息,因此检测数据集应包含对象在其自然环境中的图像。在我们的数据集中,我们努力收集富含上下文信息的图像。使用边界框也限制了检测算法评估的准确性。我们建议使用完全分割的实例来实现更准确的检测器评估。

Fig. 2: Example of (a) iconic object images, (b) iconic scene images, and © non-iconic images.
图2:(a) 标志性对象图像、(b) 标志性场景图像和© 非标志性图像的示例。
Semantic scene labeling The task of labeling semantic objects in a scene requires that each pixel of an image be labeled as belonging to a category, such as sky, chair, floor, street, etc. In contrast to the detection task, individual instances of objects do not need to be segmented, Fig. 1©. This enables the labeling of objects for which individual instances are hard to define, such as grass, streets, or walls. Datasets exist for both indoor [11] and outdoor [35], [14] scenes. Some datasets also include depth information [11]. Similar to semantic scene labeling, our goal is to measure the pixel-wise accuracy of object labels. However, we also aim to distinguish between individual instances of an object, which requires a solid understanding of each object’s extent.
语义场景标注 对场景中的语义对象进行标注的任务要求图像的每个像素都被标注为属于某个类别,例如天空、椅子、地板、街道等。与检测任务不同,不需要分割单个对象实例,如图1©所示。这使得可以标注那些难以定义单个实例的对象,例如草地、街道或墙壁。存在用于室内[11]和室外[35]、[14]场景的数据集。一些数据集还包括深度信息[11]。与语义场景标注类似,我们的目标是测量对象标签的像素级准确性。然而,我们还旨在区分对象的单个实例,这需要对每个对象的范围有扎实的理解。
A novel dataset that combines many of the properties of both object detection and semantic scene labeling datasets is the SUN dataset [3] for scene understanding. SUN contains 908 scene categories from the WordNet dictionary [30] with segmented objects. The 3,819 object categories span those common to object detection datasets (person, chair, car) and to semantic scene labeling (wall, sky, floor). Since the dataset was collected by finding images depicting various scene types, the number of instances per object category exhibits the long tail phenomenon. That is, a few categories have a large number of instances (wall: 20,213, window: 16,080, chair: 7,971) while most have a relatively modest number of instances (boat: 349, airplane: 179, floor lamp: 276). In our dataset, we ensure that each object category has a significant number of instances, Fig. 5.
结合了对象检测和语义场景标注数据集许多特性的一个新颖数据集是用于场景理解的SUN数据集[3]。SUN包含来自WordNet词典[30]的908个场景类别,并带有分割的对象。3,819个对象类别涵盖了对象检测数据集(人、椅子、汽车)和语义场景标注(墙壁、天空、地板)中常见的对象。由于该数据集是通过查找描绘各种场景类型的图像收集的,因此每个对象类别的实例数量表现出长尾现象。也就是说,少数类别有大量实例(墙壁:20,213,窗户:16,080,椅子:7,971),而大多数类别只有相对较少的实例(船:349,飞机:179,落地灯:276)。在我们的数据集中,我们确保每个对象类别都有大量实例,如图5所示。
Other vision datasets Datasets have spurred the advancement of numerous fields in computer vision. Some notable datasets include the Middlebury datasets for stereo vision [20], multi-view stereo [36] and optical flow [21]. The Berkeley Segmentation Data Set (BSDS500) [37] has been used extensively to evaluate both segmentation and edge detection algorithms. Datasets have also been created to recognize both scene [9] and object attributes [8], [38]. Indeed, numerous areas of vision have benefited from challenging datasets that helped catalyze progress.
其他视觉数据集 数据集推动了计算机视觉众多领域的发展。一些著名的数据集包括用于立体视觉的 Middlebury 数据集 [20]、多视角立体 [36] 和光流 [21]。伯克利分割数据集 (BSDS500) [37] 被广泛用于评估分割和边缘检测算法。还创建了用于识别场景 [9] 和对象属性 [8]、[38] 的数据集。事实上,视觉的许多领域都受益于具有挑战性的数据集,这些数据集有助于催化进展。
3 IMAGE COLLECTION
3 图像采集
We next describe how the object categories and candidate images are selected.
接下来,我们将描述如何选择对象类别和候选图像。
3.1 Common Object Categories
3.1 常见对象类别
The selection of object categories is a non-trivial exercise. The categories must form a representative set of all categories, be relevant to practical applications and occur with high enough frequency to enable the collection of a large dataset. Other important decisions are whether to include both “thing” and “stuff” categories [39] and whether fine-grained [31], [1] and object-part categories should be included. “Thing” categories include objects for which individual instances may be easily labeled (person, chair, car) where “stuff” categories include materials and objects with no clear boundaries (sky, street, grass). Since we are primarily interested in precise localization of object instances, we decided to only include “thing” categories and not “stuff.” However, since “stuff” categories can provide significant contextual information, we believe the future labeling of “stuff” categories would be beneficial.
对象类别的选择是一项非同小可的任务。这些类别必须形成所有类别的代表性集合,与实际应用相关,并且出现频率足够高,以便能够收集大型数据集。其他重要的决策包括是否同时包含“事物”和“物质”类别 [39],以及是否应包含细粒度 [31]、[1] 和对象部分类别。“事物”类别包括可以轻松标记个体实例的对象(人、椅子、汽车),而“物质”类别包括没有明确边界的材料和对象(天空、街道、草地)。由于我们主要关注对象实例的精确定位,我们决定仅包含“事物”类别,而不包含“物质”。然而,由于“物质”类别可以提供重要的上下文信息,我们相信未来对“物质”类别的标注将是有益的。
The specificity of object categories can vary significantly. For instance, a dog could be a member of the “mammal”, “dog”, or “German shepherd” categories. To enable the practical collection of a significant number of instances per category, we chose to limit our dataset to entry-level categories, i.e. category labels that are commonly used by humans when describing objects (dog, chair, person). It is also possible that some object categories may be parts of other object categories. For instance, a face may be part of a person. We anticipate the inclusion of object-part categories (face, hands, wheels) would be beneficial for many real-world applications.
对象类别的特异性可能会有很大差异。例如,狗可以是“哺乳动物”、“狗”或“德国牧羊犬”类别的一员。为了实现每个类别收集大量实例的实际操作,我们选择将数据集限制在入门级类别,即人类在描述对象时通常使用的类别标签(狗、椅子、人)。某些对象类别也可能是其他对象类别的一部分。例如,面部可能是人的一部分。我们预计包含对象部分类别(面部、手、轮子)将对许多实际应用有益。
We used several sources to collect entry-level object categories of “things.” We first compiled a list of categories by combining categories from PASCAL VOC [2] and a subset of the 1200 most frequently used words that denote visually identifiable objects [40]. To further augment our set of candidate categories, several children ranging in ages from 4 to 8 were asked to name every Annotation Pipeline object they see in indoor and outdoor environments. The final 272 candidates may be found in the appendix. Finally, the co-authors voted on a 1 to 5 scale for each category taking into account how commonly they occur, their usefulness for practical applications, and their diversity relative to other categories. The final selection of categories attempts to pick categories with high votes, while keeping the number of categories per super-category (animals, vehicles, furniture, etc.) balanced. Categories for which obtaining a large number of instances (greater than 5,000) was difficult were also removed. To ensure backwards compatibility all categories from PASCAL VOC [2] are also included. Our final list of 91 proposed categories is in Fig. 5(a).
我们使用了多个来源来收集“事物”的入门级对象类别。我们首先通过结合PASCAL VOC [2]的类别和表示视觉可识别对象的1200个最常用词汇的子集来编译类别列表。为了进一步扩充候选类别集,我们请4至8岁的几个孩子命名他们在室内外环境中看到的每个注释流水线对象。最终的272个候选类别可在附录中找到。最后,合著者们根据类别的常见性、对实际应用的有用性以及相对于其他类别的多样性,对每个类别进行了1到5分的投票。最终的类别选择试图挑选高票数的类别,同时保持每个超级类别(动物、车辆、家具等)的类别数量平衡。对于难以获得大量实例(超过5000个)的类别也被移除。为了确保向后兼容性,所有来自PASCAL VOC [2]的类别也被包含在内。我们最终提出的91个类别列表如图5(a)所示。

Fig. 3: Our annotation pipeline is split into 3 primary tasks: (a) labeling the categories present in the image (§4.1), (b) locating and marking all instances of the labeled categories (§4.2), and © segmenting each object instance (§4.3).
图 3:我们的标注流程分为三个主要任务:(a) 标注图像中存在的类别(§4.1),(b) 定位并标记所有标注类别的实例(§4.2),以及 © 分割每个对象实例(§4.3)。
3.2 Non-iconic Image Collection
3.2 非图标图像收集
Given the list of object categories, our next goal was to collect a set of candidate images. We may roughly group images into three types, Fig. 2: iconic-object images [41], iconic-scene images [3] and non-iconic images. Typical iconic-object images have a single large object in a canonical perspective centered in the image, Fig. 2(a). Iconic-scene images are shot from canonical viewpoints and commonly lack people, Fig. 2(b). Iconic images have the benefit that they may be easily found by directly searching for specific categories using Google or Bing image search. While iconic images generally provide high quality object instances, they can lack important contextual information and non-canonical viewpoints.
给定对象类别的列表,我们的下一个目标是收集一组候选图像。我们可以将图像大致分为三种类型,如图 2 所示:图标对象图像 [41]、图标场景图像 [3] 和非图标图像。典型的图标对象图像在图像中心以标准视角显示一个单一的大型对象,如图 2(a) 所示。图标场景图像通常从标准视角拍摄,并且通常缺乏人物,如图 2(b) 所示。图标图像的优点是它们可以通过直接使用 Google 或 Bing 图像搜索特定类别来轻松找到。虽然图标图像通常提供高质量的对象实例,但它们可能缺乏重要的上下文信息和非标准视角。
Our goal was to collect a dataset such that a majority of images are non-iconic, Fig. 2©. It has been shown that datasets containing more non-iconic images are better at generalizing [42]. We collected non-iconic images using two strategies. First as popularized by PASCAL VOC [2], we collected images from Flickr which tends to have fewer iconic images. Flickr contains photos uploaded by amateur photographers with searchable metadata and keywords. Second, we did not search for object categories in isolation. A search for “dog” will tend to return iconic images of large, centered dogs. However, if we searched for pairwise combinations of object categories, such as “dog + car” we found many more non-iconic images. Surprisingly, these images typically do not just contain the two categories specified in the search, but numerous other categories as well. To further supplement our dataset we also searched for scene/object category pairs, see the appendix. We downloaded at most 5 photos taken by a single photographer within a short time window. In the rare cases in which enough images could not be found, we searched for single categories and performed an explicit filtering stage to remove iconic images. The result is a collection of 328,000 images with rich contextual relationships between objects as shown in Figs. 2© and 6.
我们的目标是收集一个数据集,使得大多数图像都是非图标化的,如图2©所示。已有研究表明,包含更多非图标化图像的数据集在泛化方面表现更好[42]。我们通过两种策略收集非图标化图像。首先,如PASCAL VOC[2]所推广的,我们从Flickr收集图像,Flickr通常包含较少的图标化图像。Flickr包含业余摄影师上传的带有可搜索元数据和关键词的照片。其次,我们没有孤立地搜索对象类别。搜索“狗”往往会返回大型、居中的狗的图标化图像。然而,如果我们搜索对象类别的成对组合,例如“狗 + 车”,我们发现了更多的非图标化图像。令人惊讶的是,这些图像通常不仅包含搜索中指定的两个类别,还包含许多其他类别。为了进一步补充我们的数据集,我们还搜索了场景/对象类别对,详见附录。我们最多下载了在短时间内由同一摄影师拍摄的5张照片。在极少数情况下,如果无法找到足够的图像,我们会搜索单个类别,并进行显式过滤阶段以移除图标化图像。结果是一个包含328,000张图像的集合,其中对象之间具有丰富的上下文关系,如图2©和图6所示。
4 IMAGE ANNOTATION
4 图像标注
We next describe how we annotated our image collection. Due to our desire to label over 2.5 million object instances, the design of a cost efficient yet high quality annotation pipeline was critical. The annotation pipeline is outlined in Fig. 3. For all crowdsourcing tasks we used workers on Amazon’s Mechanical Turk (AMT). Our user interfaces are described in detail in the appendix. Note that, since the original version of this work [19], we have taken a number of steps to further improve the quality of the annotations. In particular, we have increased the number of annotators for the category labeling and instance spotting stages to eight. We also added a stage to verify the instance segmentations.
接下来,我们将描述如何标注我们的图像集合。由于我们希望标注超过250万个对象实例,设计一个成本高效且高质量的标注流程至关重要。标注流程如图3所示。对于所有众包任务,我们使用了Amazon Mechanical Turk(AMT)上的工人。我们的用户界面在附录中有详细描述。请注意,自这项工作的原始版本[19]以来,我们已经采取了许多步骤来进一步提高标注质量。特别是,我们将类别标注和实例定位阶段的标注者数量增加到了八个。我们还增加了一个阶段来验证实例分割。
4.1 Category Labeling
4.1 类别标注
The first task in annotating our dataset is determining which object categories are present in each image, Fig. 3(a). Since we have 91 categories and a large number of images, asking workers to answer 91 binary classification questions per image would be prohibitively expensive. Instead, we used a hierarchical approach [18].
标注数据集的第一项任务是确定每张图像中存在哪些对象类别,如图3(a)所示。由于我们有91个类别和大量图像,要求工人每张图像回答91个二分类问题将过于昂贵。相反,我们采用了分层方法[18]。
—— 更多内容请到Doc2X翻译查看——
—— For more content, please visit Doc2X for translations ——

















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









