






论文内容翻译
1. 问题背景
本文研究了一个分布式控制系统,其中包含以下组成部分:
- 一个未知动态的领导者:
- 多个异构的跟随者,动态如下:
- 其中 i=1,…,N表示不同的智能体。
2. 主要挑战
- 领导者的动态矩阵
对所有跟随者都是未知的。
- 通信网络可能遭受 拒绝服务(DoS)攻击。
- 每个智能体的动态不同(异构性)。
- 可能发生物理执行器故障。
3. 基于学习的解决方案
作者提出了一个三步解决方案:
A. 分布式鲁棒学习算法
为学习未知的领导者矩阵 ,算法步骤为:
-
在时间间隔上收集数据样本:
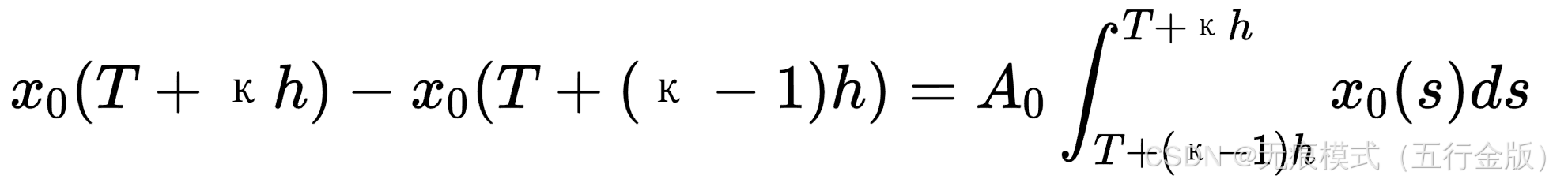
-
将其转化为线性方程:
d(T,hκ)=e(T,hκ)⋅vec(A0)其中:
- d(T,hκ) 表示状态差分;
- e(T,hκ)包含积分的状态信息;
- vec(
B. 分布式鲁棒估计器
在学习到 后,设计了一个估计器:
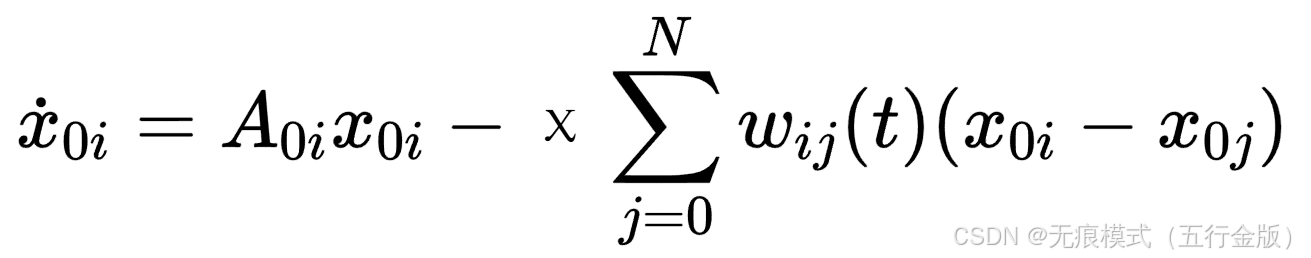
其中:
表示通信正常,
表示通信受到 DoS 影响;
- χ 是估计器增益;
是智能体 i 对领导者状态的估计。
C. 自适应容错控制器
最终控制律为:
并附有以下自适应律:
4. 拒绝服务攻击处理
系统通过以下方式应对 DoS 攻击:
- 估计器中的切换机制
;
- 在间歇通信下仍然有效的鲁棒学习;
- 对满足频率和时长约束的 DoS 攻击提供稳定性保证:
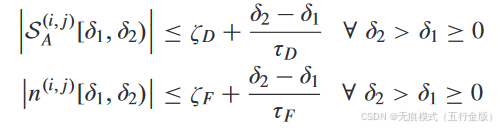
5. 异构性处理
系统通过以下方式解决异构性问题:
- 针对每个智能体设计单独的自适应控制器;
- 为每个智能体动态调整的估计器;
- 允许不同智能体模型协同工作的控制框架。
以上内容参考自论文《Learning-Based Distributed Resilient Fault-Tolerant Control Method for Heterogeneous MASs Under Unknown Leader Dynamic》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









