






在人工智能的浪潮中,目标检测作为计算机视觉领域的关键技术,广泛应用于自动驾驶、安防监控、智能机器人等多个场景。而 YOLO(You Only Look Once)算法,凭借其快速、高效的特性,成为实时目标检测任务中的佼佼者。本文将带大家深入了解 YOLO 算法的核心原理、发展历程、应用场景,以及代码实现,揭开它的神秘面纱。
一、YOLO 算法的诞生背景与核心思想
YOLO(You Only Look Once)是一种基于深度学习的目标检测算法,由Joseph Redmon等人于2016年提出。它的核心思想是将目标检测问题转化为一个回归问题,通过一个神经网络直接预测目标的类别和位置。YOLO算法将输入图像分成SxS个网格,每个网格负责预测该网格内是否存在目标以及目标的类别和位置信息。此外,YOLO算法还采用了多尺度特征融合的技术,使得算法能够在不同尺度下对目标进行检测。
相比于传统的目标检测算法,如R-CNN、Fast R-CNN和Faster R-CNN等,YOLO算法具有更快的检测速度和更高的准确率。这得益于其端到端训练方式和单阶段检测的特性,使其可以同时处理分类和定位任务,避免了传统方法中的多阶段处理过程。因此,YOLO算法广泛应用于实时目标检测和自动驾驶等领域。
单阶段无需先生成候选区域,而是直接在网络中对目标进行分类和定位,因此具有更高的检测速度,非常适合实时应用场景。

one-stage的优缺点:
优点:识别速度非常快,适合做实时检测任务
缺点:正确率相比较低
two-stage的优缺点:
优点:正确率比较高,识别效果理想
缺点:识别速度比较慢
两阶段目标检测器是一种先生成候选框,然后对候选框进行分类和回归的检测方法。这种方法主要包括两个阶段:
代表性的两阶段目标检测器包括R-CNN系列,以及其改进版本Fast R-CNN、Faster R-CNN和Mask R-CNN等。
二、YOLO 算法的工作原理
YOLO 算法的工作流程主要分为以下几个步骤:
- 图像预处理:将输入图像调整为固定尺寸,并进行归一化处理,使其像素值分布在 [0, 1] 区间内,便于模型计算。
- 网格划分:将图像划分为 S×S 的网格,每个网格负责预测落在该网格内的目标。如果目标的中心坐标落在某个网格中,那么这个网格就负责检测该目标。
- 预测输出:每个网格会预测 X 个边界框及其对应的置信度分数(表示该框内是否包含目标以及包含目标的准确程度),同时预测每个边界框所属的每个类别概率。
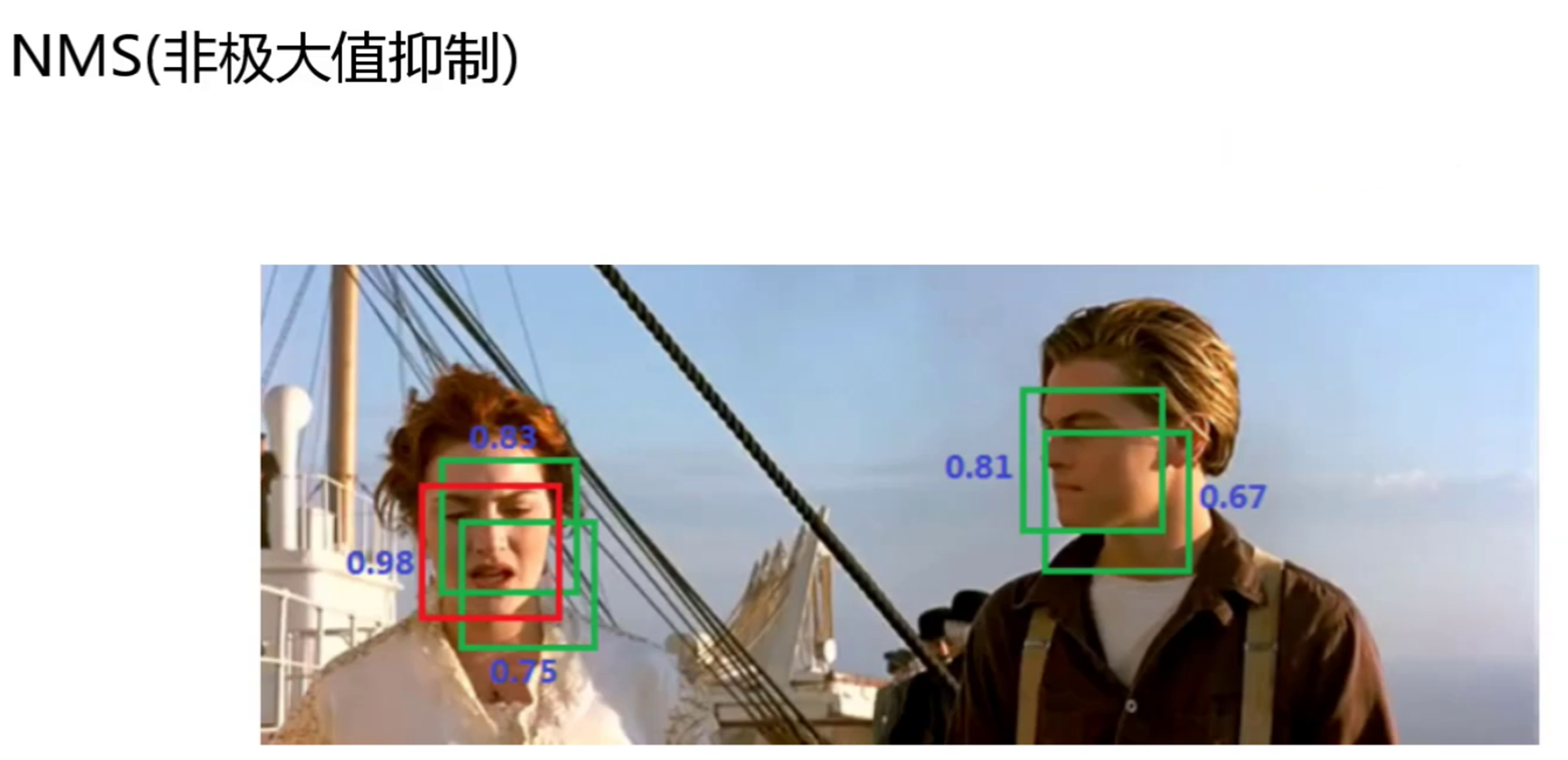
- 后处理:通过非极大值抑制(Non-Maximum Suppression,NMS)算法过滤掉置信度低的边界框,并合并重叠度高的框,得到最终的检测结果。
IOU:是目标检测中衡量预测框与真实框重叠程度的指标,计算公式为两者的交集面积除以并集面积,值范围在0(无重叠)到1(完全重合)之间。

置信度: 是目标检测模型中用于衡量预测框可靠性的概率值,表示模型对框内是否包含检测目标的置信程度
置信度公式:Confidence=P(Object)×IoU
P(Object) 是存在目标的概率,若存在对象, P(Object) =1,否则, P(Object) =0。
NMS:(Non-Maximum Suppression,非极大值抑制) 是目标检测中用于消除冗余预测框的后处理算法,其核心思想是保留置信度最高且与其他框重叠度(IoU)低的预测框,剔除重复或低质量的检测结果。
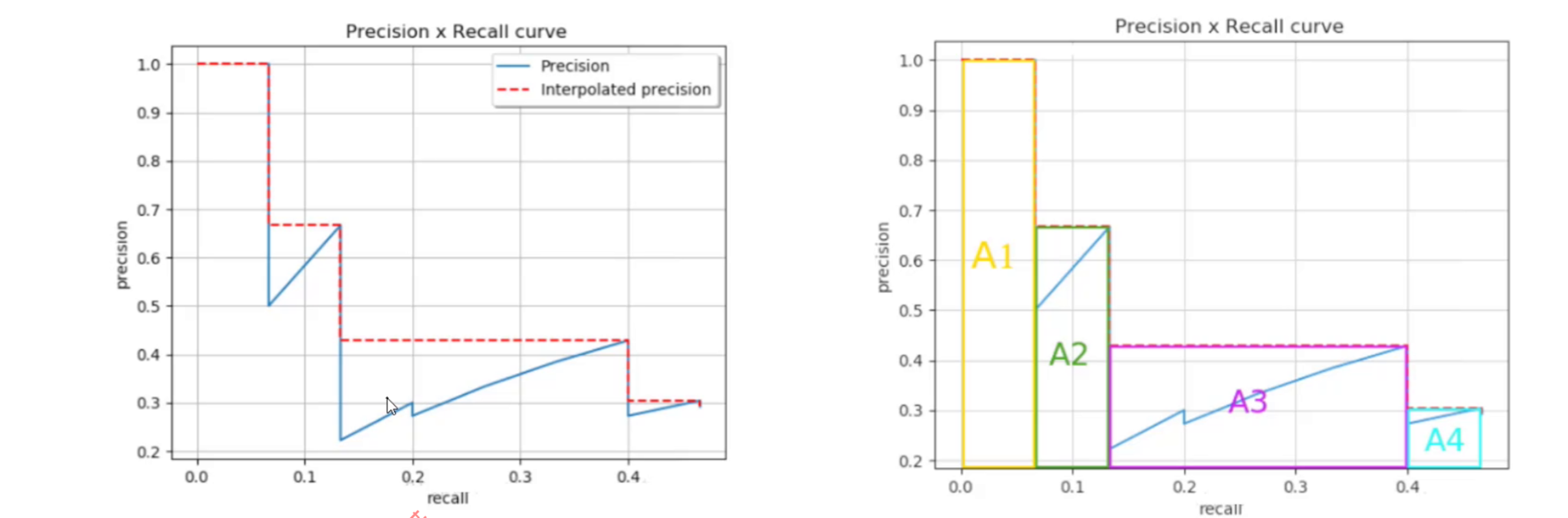
MAP指标:是用来评估目标检测算法性能的常用指标之一。它结合了目标检测算法的精确率和召回率,并考虑了不同类别之间的差异。绘制出召回率和精确率的曲线,将曲线以下的面积作为MAP值。当MAP值越大,则表示指标越好 。
精确率:预测的结果中有多少是正确的
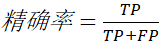
召回率:真实的结果中有多少是预测正确的
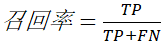

















 2525
2525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









