






 本文探讨了矩阵乘法中的数据依赖性问题,如何通过改变内存访问模式和循环顺序来降低InitiationInterval,提高硬件资源利用效率。优化后的代码显著减少了II并降低了硬件资源的闲置率。
本文探讨了矩阵乘法中的数据依赖性问题,如何通过改变内存访问模式和循环顺序来降低InitiationInterval,提高硬件资源利用效率。优化后的代码显著减少了II并降低了硬件资源的闲置率。
目录
1. 概述
Initiation Interval(II)定义为启动连续操作之间的时间间隔,以时钟周期为单位。低的II是高性能和高资源利用率的关键。
较高的II意味着在单位时间内完成的操作数量减少,从而降低了整体的吞吐量,部分硬件资源(如加法器、乘法器等)会闲置,没有被充分利用。
2. 常规矩阵乘法
矩阵乘法定义如下:
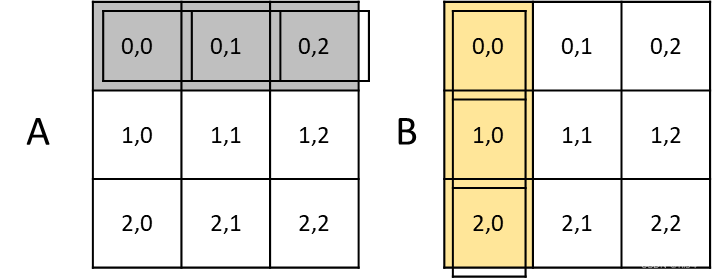
前两层循环,遍历所有元素,第三层循环,用于元素累加乘,代码如下:
for (int i = 0; i < size; i++)
{
for (int j = 0; j < size; j++)
{
for (int k = 0; k < MAX_SIZE; k++)
{
int result = (k == 0) ? 0 : temp_sum[j];
result += A[i][k] * B[k][j];
temp_sum[j] = result;
if (k== size -1) C[i][j] = result;
}
}
}对于矩阵A和矩阵B的乘积,每个输出元素C[i][j]是通过将A矩阵的第i行与B矩阵的第j列对应元素相乘然后加总得到的,这意味着在计算C[i][j]的每个元素时,都需要访问A[i][k]和B[k][j]。
3. 数据依赖性和内存访问模式
由于B矩阵的访问是按列进行的,这不是连续的内存访问,会导致缓存利用率低下。
同时,HLS编译器会构建一个加法器树来逐步累加每次乘法的结果。由于每次循环迭代都依赖于前一次的结果,也会导致较高的Initiation Interval(II)。
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+
| | Latency (cycles) | Iteration| Initiation Interval | Trip | |
| Loop Name | min | max | Latency | achieved | target | Count| Pipelined|
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+
|- lreorder1_lreorder2 | ?| ?| 33| 32| 1| ?| yes|
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+从编译器反馈的结果来看,II=32,每32个时钟周期就可以启动一个新的迭代。
================================================================
== Utilization Estimates
================================================================
* Summary:
+-----------------+---------+------+--------+--------+-----+
| Name | BRAM_18K| DSP | FF | LUT | URAM|
+-----------------+---------+------+--------+--------+-----+
|DSP | -| -| -| -| -|
|Expression | -| -| 0| 1813| -|
|FIFO | -| -| -| -| -|
|Instance | -| 96| 0| 5376| -|
|Memory | -| -| -| -| -|
|Multiplexer | -| -| -| 10137| -|
|Register | -| -| 2302| -| -|
+-----------------+---------+------+--------+--------+-----+
|Total | 0| 96| 2302| 17326| 0|
+-----------------+---------+------+--------+--------+-----+
|Available | 288| 1248| 234240| 117120| 64|
+-----------------+---------+------+--------+--------+-----+
|Utilization (%) | 0| 7| ~0| 14| 0|
+-----------------+---------+------+--------+--------+-----+对于这些硬件资源,它们在大部分时间内处于空闲状态,硬件的潜在计算能力没有得到充分发挥。
4. 优化循环

优化后的代码:
for (int i = 0; i < size; i++) {
for (int k = 0; k < size; k++) {
for (int j = 0; j < size; j++) {
int result = (k == 0) ? 0 : temp_sum[j];
result += A[i][k] * B[k][j];
temp_sum[j] = result;
if (k == size - 1) C[i][j] = result;
}
}
}
通过将k循环移到中间层,改变了内存访问的模式。现在,对B[k][j]的访问变得连续,因为j循环是最内层。
同时,由于result的计算不再依赖于k循环的前一次迭代结果,因此可以减少依赖性。
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+
| | Latency (cycles) | Iteration| Initiation Interval | Trip | |
| Loop Name | min | max | Latency | achieved | target | Count| Pipelined|
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+
|- lreorder1_lreorder2 | 1024| 1024| 2| 1| 1| 1024| yes|
+-----------------------+---------+---------+----------+-----------+-----------+------+----------+同时减少了资源占用:
================================================================
== Utilization Estimates
================================================================
* Summary:
+-----------------+---------+------+--------+--------+-----+
| Name | BRAM_18K| DSP | FF | LUT | URAM|
+-----------------+---------+------+--------+--------+-----+
|DSP | -| -| -| -| -|
|Expression | -| -| 0| 2593| -|
|FIFO | -| -| -| -| -|
|Instance | -| 96| 0| 640| -|
|Memory | -| -| -| -| -|
|Multiplexer | -| -| -| 54| -|
|Register | -| -| 1190| -| -|
+-----------------+---------+------+--------+--------+-----+
|Total | 0| 96| 1190| 3287| 0|
+-----------------+---------+------+--------+--------+-----+
|Available | 288| 1248| 234240| 117120| 64|
+-----------------+---------+------+--------+--------+-----+
|Utilization (%) | 0| 7| ~0| 2| 0|
+-----------------+---------+------+--------+--------+-----+5. 总结
循环重排优化了内存访问模式,减少了数据依赖性,使得硬件能够更有效地并行处理计算,从而提高了执行效率。II从32降低到了1。















 4235
4235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









