









FPGA HLS Matrix_MUL 矩阵乘法的计算与优化:https://blog.csdn.net/qq_45364953/article/details/127641923
只用最简单的方法学习FPGA - 知乎 (zhihu.com)
hls之AXI-lite接口综合_龙叙的博客-CSDN博客_axi lite接口
AXI 接口
FPGA的板子上,例如zynq或者pynq上有一块ARM硬核,这个板子就称为SOC(system on chip,片上系统);
我们想让ARM控制我们的模块,控制数据的传输和控制信号等等。就需要将数据的接口和模块IP的接口设置乘AXI接口。
AXI接口,分为主机接口master和从机接口slave,决定谁被谁控制
数据AXI接口设置
将数组A设置为s_axilite ,也就是CPU作为主机,将数据通过AXI接口发送给从机A
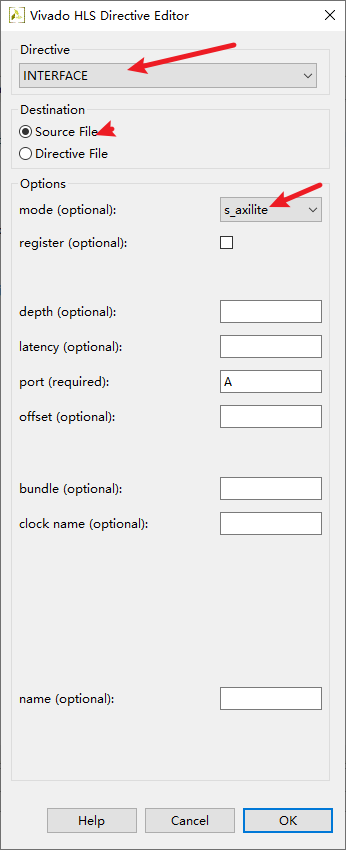
相同的操作把B和C数组也设为s_axilite
#include "matrix_mul.h"
void matrix_mul(ap_int<8> A[4][4], ap_int<8> B[4][4], ap_int<16> C[4][4])
{
// AXI接口设置
#pragma HLS INTERFACE s_axilite port=B
#pragma HLS INTERFACE s_axilite port=C
#pragma HLS INTERFACE s_axilite port=A
// 数组reshape
#pragma HLS ARRAY_RESHAPE variable=B complete dim=1
#pragma HLS ARRAY_RESHAPE variable=A complete dim=2
for(int i = 0; i < 4; ++ i){
for(int j = 0; j < 4; ++ j){
#pragma HLS LATENCY min=5 max=5
#pragma HLS PIPELINE II=1
C[i][j] = 0;
for(int k = 0; k < 4; ++ k){
C[i][j] += A[i][k]*B[k][j];
}
}
}
}
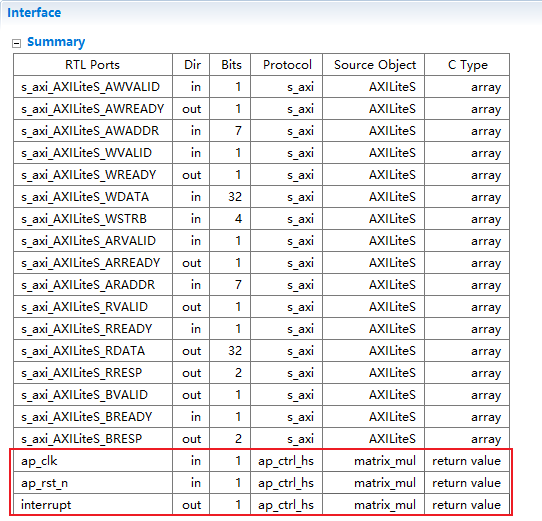
C综合后的接口:

但是模块工作的开始信号依旧被ap_start和ap_done信号控制。我们希望CPU控制,所以需要对模块的启动方式设置
控制AXI接口设置
对函数的接口进行约束设置:

#include "matrix_mul.h"
void matrix_mul(ap_int<8> A[4][4], ap_int<8> B[4][4], ap_int<16> C[4][4])
{
// 函数控制接口
#pragma HLS INTERFACE s_axilite port=return
// AXI接口设置
#pragma HLS INTERFACE s_axilite port=B
#pragma HLS INTERFACE s_axilite port=C
#pragma HLS INTERFACE s_axilite port=A
// 数组reshape
#pragma HLS ARRAY_RESHAPE variable=B complete dim=1
#pragma HLS ARRAY_RESHAPE variable=A complete dim=2
for(int i = 0; i < 4; ++ i){
for(int j = 0; j < 4; ++ j){
#pragma HLS LATENCY min=5 max=5
#pragma HLS PIPELINE II=1
C[i][j] = 0;
for(int k = 0; k < 4; ++ k){
C[i][j] += A[i][k]*B[k][j];
}
}
}
}
C综合结果:
生成IP核
点击Export RTL;
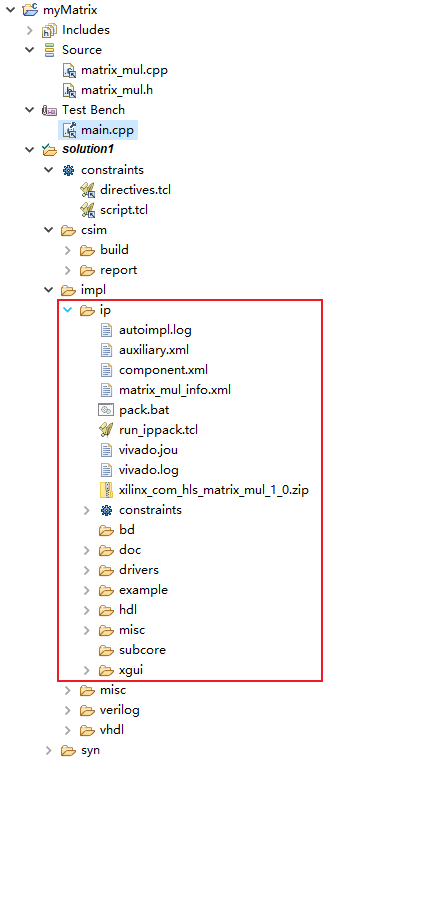
IP封装完成后,会在impl文件夹中输出ip文件夹,其中包含了RTL代码(hdl),模块驱动(drivers),文档(doc)等信息,其中包含一个压缩包文件,是用于建立vivado工程所用的IP压缩包。
vivado验证IP模块
创建一个新项目:
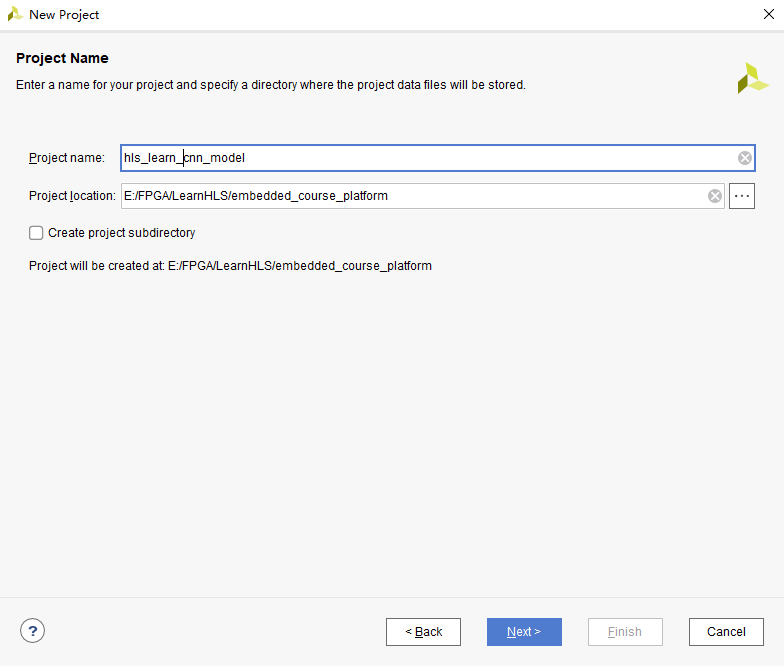
选择pynq的板子:
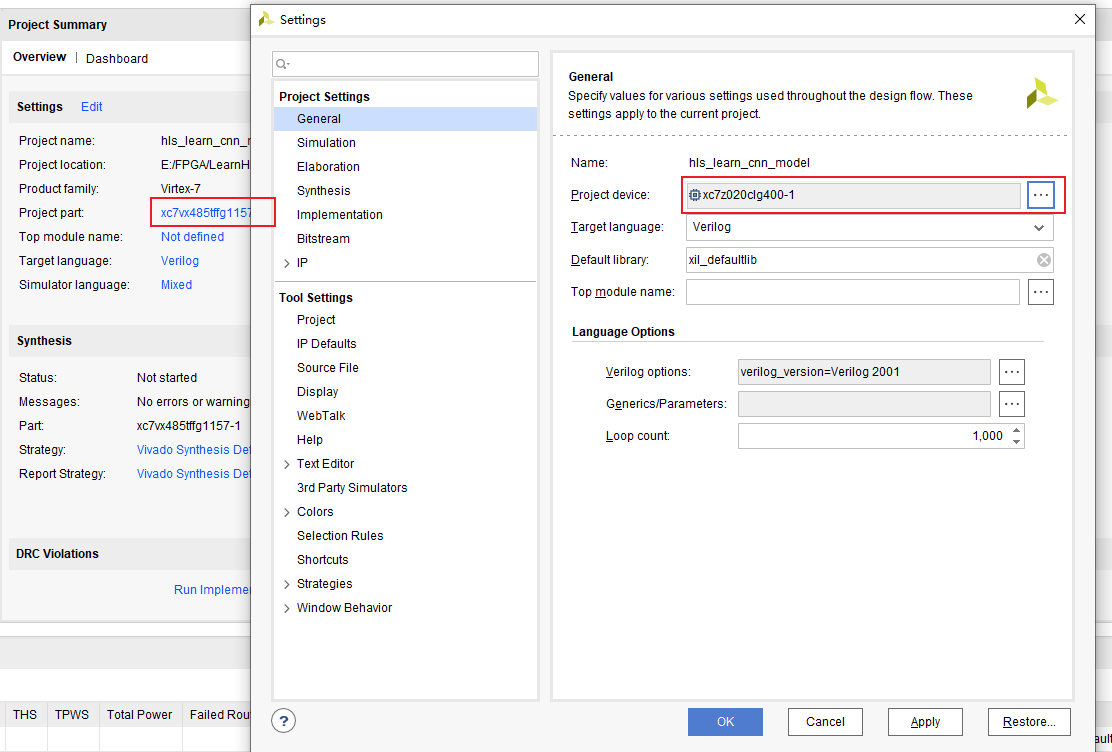
创建块设计
点击IP INTEGRATOR – Create Block Design
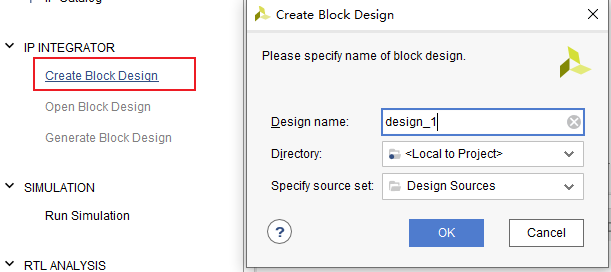
添加IP核
setting->IP->Repository->ip核的目录
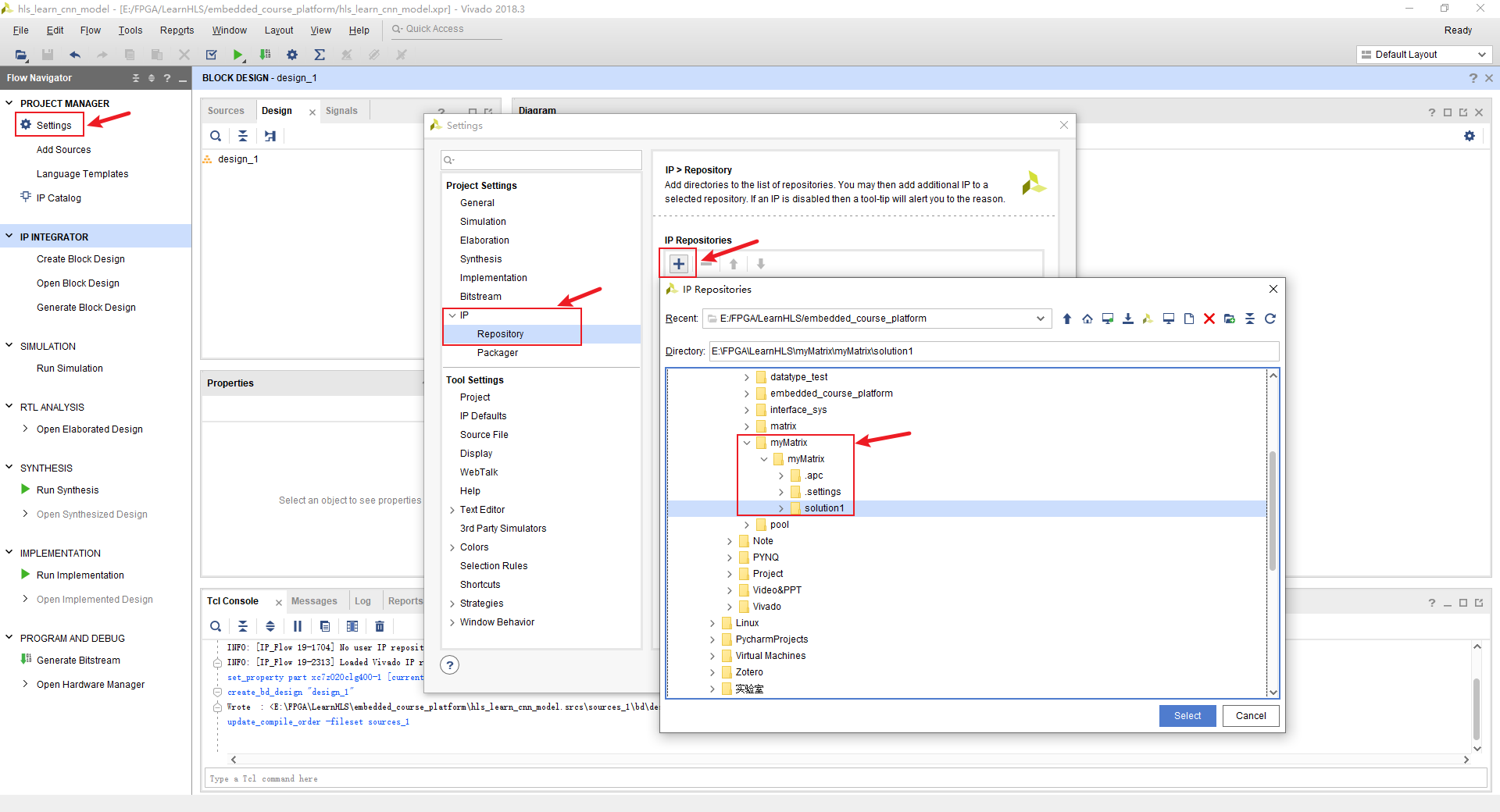
自动寻找到了matrix_mul模块:
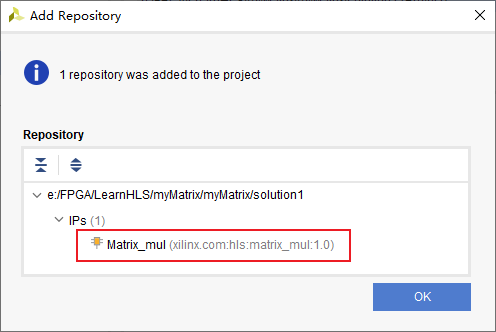
添加IP内核zynq以识别硬核ARM CPU

将库里的HLS设计的IP添加
- 添加IP
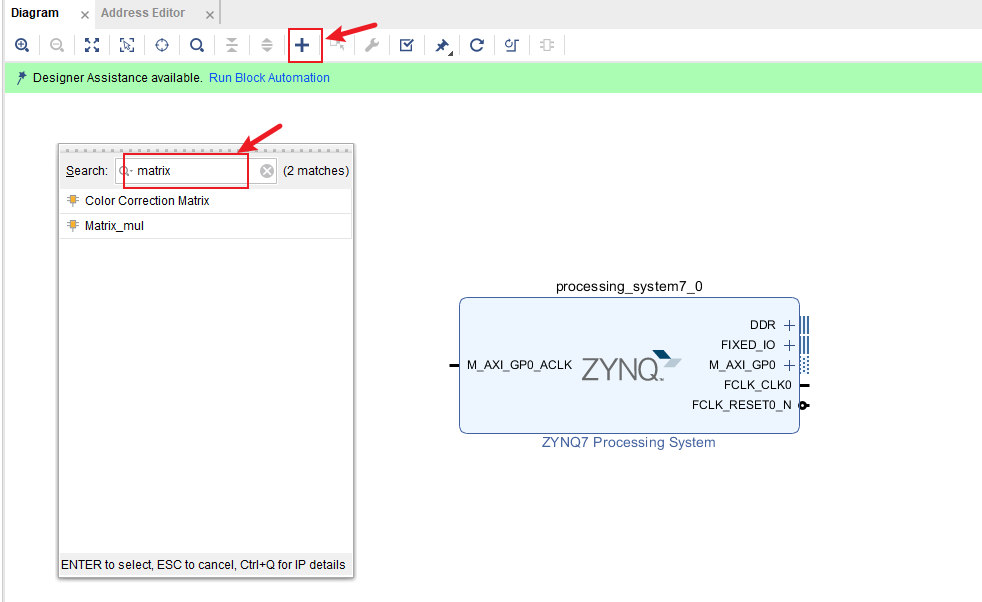
- 运行两种类型的自动化
点击run Block Automation和Run Connection Automation


- 点击regenerate layout,重新生成布局,更好看一点
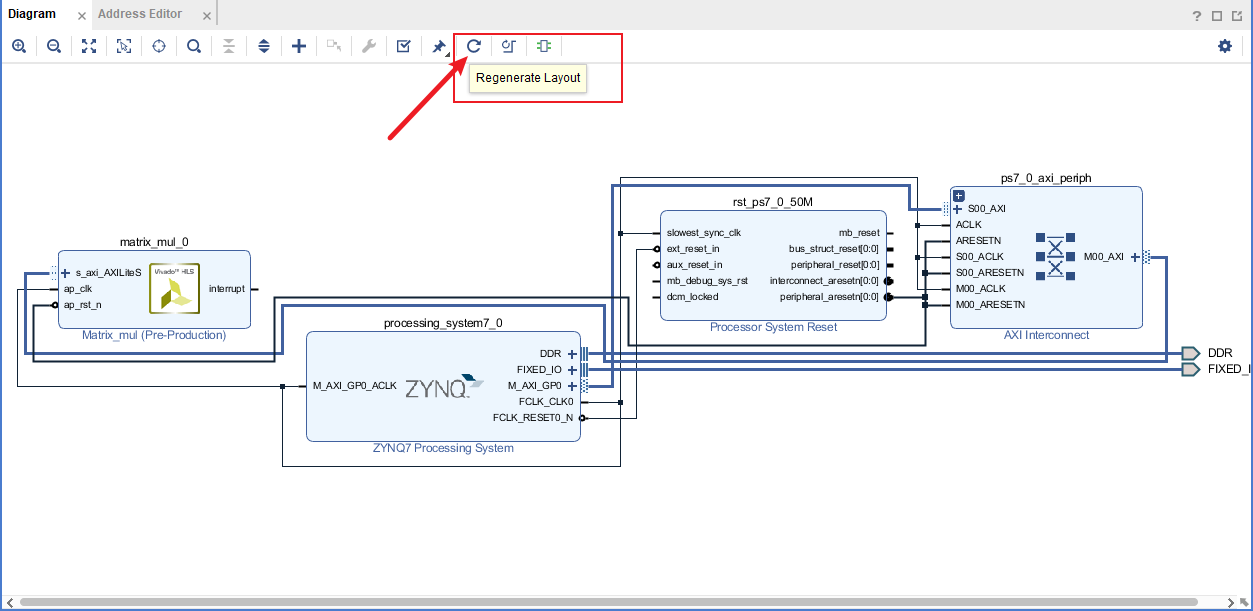
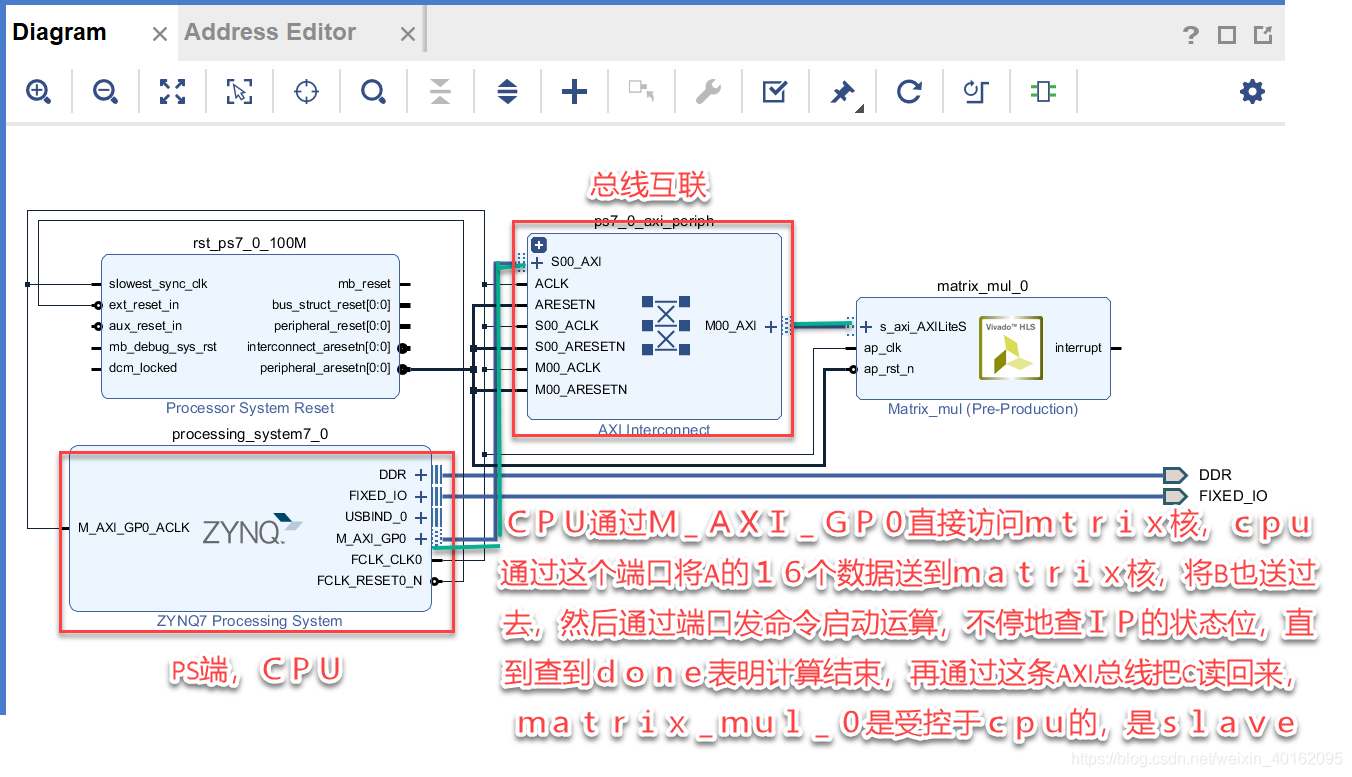
- 点击validation验证设计
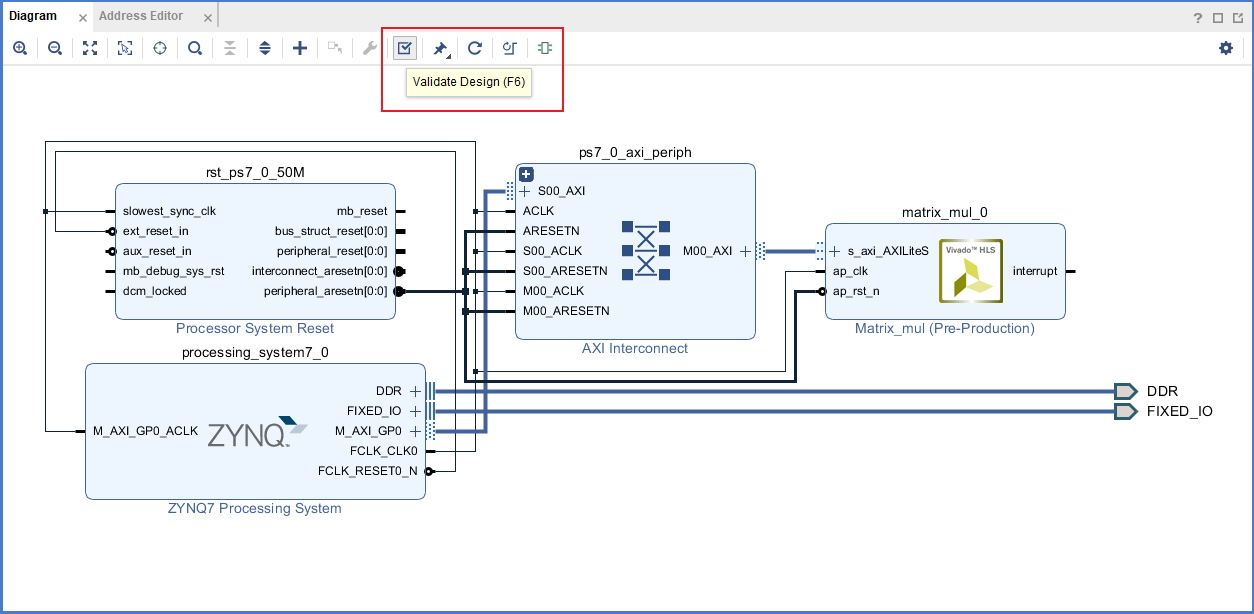
按CTRL+S保存工程
创建包装RTL:Create HDL Wrapper
这一步每次修改设计后都要进行
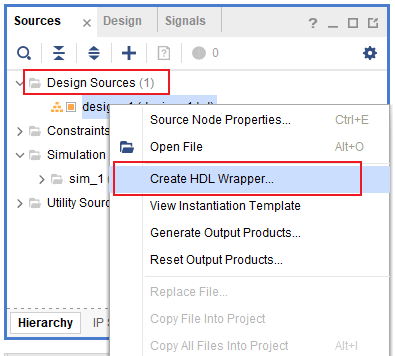
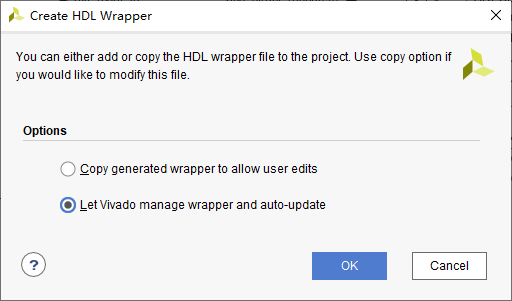
包了一层:
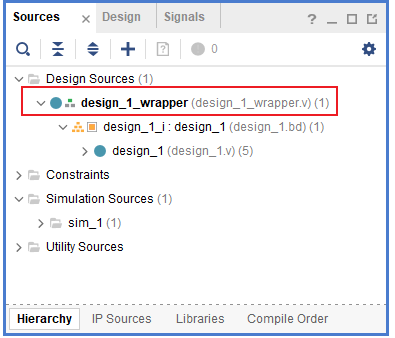
- 生成output Products
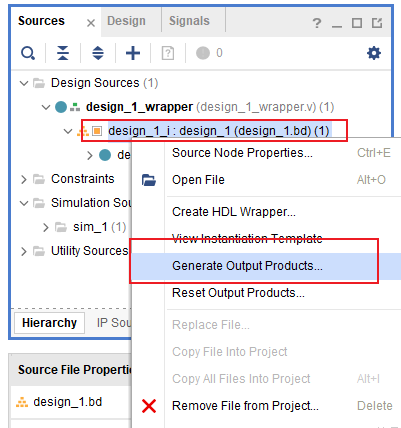

电路综合与可交付成果
执行电路综合生成bit流
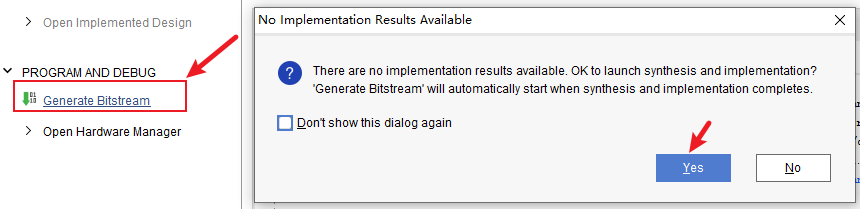
.bit和.hwh文件是综合的结果

PYNQ编写主机程序
从PYNQ-Z1开始入门FPGA学习(下) - 知乎 (zhihu.com)
编写控制FPGA电路的主机程序
创建Jupyter Notebook并编写主机程序
新建一个文件夹1_matrix_mul 将hwh文件和bit文件复制进去,将文件名设为一致

新建python文件

加载bit文件
导入库:
from pynq import Overlay
import numpy as np
烧写FPGA
ol=Overlay("matrix_mul.bit")
ol.download()
print(ol.ip_dict.keys()) # 打印FPGA系统的slave IP
初始化数组
hls工程中的驱动文件xmatrix_mul.h这个文件找变量的地址信息
// AXILiteS
// 0x00 : Control signals
// bit 0 - ap_start (Read/Write/COH)
// bit 1 - ap_done (Read/COR)
// bit 2 - ap_idle (Read)
// bit 3 - ap_ready (Read)
// bit 7 - auto_restart (Read/Write)
// others - reserved
// 0x04 : Global Interrupt Enable Register
// bit 0 - Global Interrupt Enable (Read/Write)
// others - reserved
// 0x08 : IP Interrupt Enable Register (Read/Write)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x0c : IP Interrupt Status Register (Read/TOW)
// bit 0 - Channel 0 (ap_done)
// bit 1 - Channel 1 (ap_ready)
// others - reserved
// 0x10 ~
// 0x1f : Memory 'A_V' (4 * 32b)
// Word n : bit [31:0] - A_V[n]
// 数组A每个元素占8位也就是1个字节,一共16个数,所以一共16个字节,地址从0x10到0x1f
// 数组A按照维度2reshape,所以memory中数组A是4*32bit的,也就是每一行放4个数据
// 0x20 ~
// 0x2f : Memory 'B_V' (4 * 32b)
// Word n : bit [31:0] - B_V[n]
// 0x40 ~
// 0x5f : Memory 'C_V' (16 * 16b)
// Word n : bit [15: 0] - C_V[2n]
// bit [31:16] - C_V[2n+1]
// 数组C每个元素占16位,一共16个数,所以占32个字节;数组C是16*16的,也就是每行一个数放了16行
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)
10000000100000001000000011111111
3 2 1 0
# 获取矩阵乘法的IP
matrix_mul = ol.matrix_mul_0
# 初始化数组
A = np.zeros([4,4], dtype=np.int8)
B = np.zeros([4,4], dtype=np.int8)
C = np.zeros([4,4], dtype=np.int16)
for i in range(4):
for j in range(4):
A[i][j] = i*4 + j
B[i][j] = A[i][j]
# 写入数组A,B的值
for i in range(4):
tmp = 0
for j in range(4):
tmp = tmp|(A[i][j] << (j*8)) # 数组A是维度2的reshape
matrix_mul.write(0x10+i*4, int(tmp))
for i in range(4):
tmp = 0
for j in range(4):
tmp = tmp|(B[j][i] << (j*8))# 数组B是维度1的reshape
matrix_mul.write(0x20+i*4, int(tmp))
启动IP核,打印结果
# 启动IP核:bit 0 - ap_start (Read/Write/COH)
matrix_mul.write(0, 1)
# 不断判断是否执行完成:bit 1 - ap_done (Read/COR)
while True:
# 获取0x00地址的第二个bit位数据:
tmp = matrix_mul.read(0x00)&0x02
if tmp>>1 &1:
break
print("matrix_mul ip done")
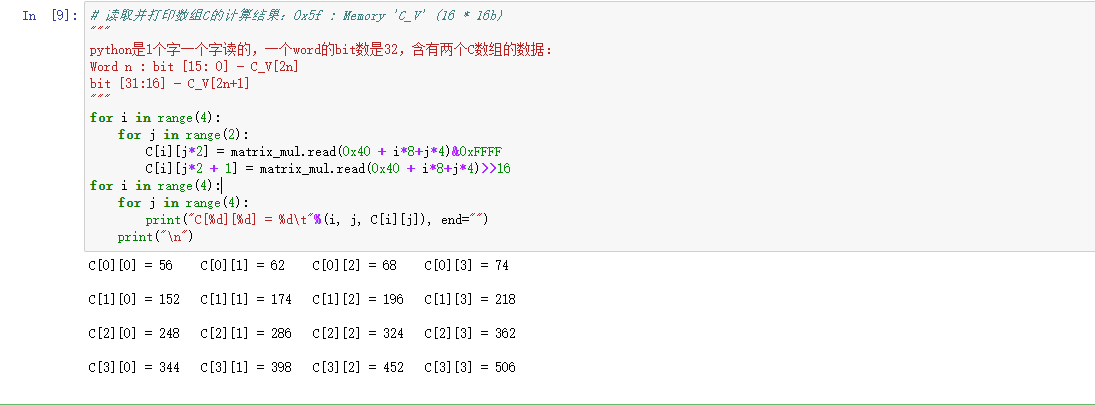
# 读取并打印数组C的计算结果:0x5f : Memory 'C_V' (16 * 16b)
"""
python是1个字一个字读的,一个word的bit数是32,含有两个C数组的数据:
Word n : bit [15: 0] - C_V[2n]
bit [31:16] - C_V[2n+1]
"""
for i in range(4):
for j in range(2):
C[i][j*2] = matrix_mul.read(0x40 + i*8+j*4)&0xFFFF
C[i][j*2 + 1] = matrix_mul.read(0x40 + i*8+j*4)>>16
for i in range(4):
for j in range(4):
print("C[%d][%d] = %d\t"%(i, j, C[i][j]), end="")
print("\n")















 4235
4235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









