







目录
1. 简介
本文是对《Hardware Acceleration Tutorials: FIFO Sizing for Performance and Avoiding Deadlocks》实验内容的详细解释。
首先需要了解,鉴于数据流优化具有动态特性,且不同并行任务的执行速度各不相同,设置不当的数据流通道可能会引发性能下降或死锁。
数据流通道有两种:FIFO 和 PIPO。可以由工具推断,或者用户自行创建。
FIFO:
- Streams (including hls::streams and streamed arrays),用户创建。
- Scalar propagation FIFOs,工具推断。
- Streams of blocks,用户创建。
每个通道都有自己的握手信号。因为:
- 它们的读写操作是被调度的。
- 它们的读/写信号分别由流水线控制或有限状态机(FSM)单独驱动。
- 它们的full_n/empty_n信号直接使流水线的单个迭代或FSM的状态暂停。
PIPO:
- PIPO,用户创建。
- Task Level FIFOs (TLF),工具推断。
- Input and output ports to the upper level,用户创建。
其中,Task Level FIFOs (TLF) 是标量(scalar)FIFO,其连接到生产者的“done”握手信号以进行写入,并连接到消费者的“start”握手信号以进行读取。这些类型的FIFO是由工具自动推断的。由于底层同步机制的缘故,它们被视为类PIPO。
这些通道应该被视为“使用ap_ctrl_chain握手的通道”,因为:
- 它们的写入和读取操作不会被调度。它们隐式地与进程的“done”握手或“start”握手相关联。
- 它们的写入和读取信号分别连接到ap_done和ap_ready。
- 它们的full_n和empty_n分别连接到ap_continue和ap_start。
总结一下,在分析存储深度、性能、死锁等方面,真正需要关系的是:
- 通道是否拥有自己的握手机制(FIFOs)。它们的访问在其进程执行期间被分散开来。例如,你可以在管道的第一个II之外读取一个FIFO,或者甚至在数据流网络的最后一个过程中读取。
- 通道是否通过ap_ctrl_chain进行握手(PIPOs)。它们的读取必须在管道的第一个II中,或者在数据流网络的第一个“层级”的过程中进行,类似地,它们的写入必须在最后一个II或在最后一个“层级”中进行。
- 另一个区别基于一次操作中传输的数据量,这对于资源分析比对性能分析更为重要:对于PIPOs来说是数组,对于流来说是块流、标量流,对于标量传播FIFOs和任务级FIFOs来说是标量。
2. 代码解析
2.1 HLS kernel代码
#include "example.h"
void example(hls::stream<int>& A, hls::stream<int>& B){
#pragma HLS dataflow
#pragma HLS INTERFACE ap_fifo port=A
#pragma HLS INTERFACE ap_fifo port=B
hls::stream<int> data_channel1;
hls::stream<int> data_channel2;
proc_1(A, data_channel1, data_channel2);
proc_2(data_channel1, data_channel2, B);
}
void proc_1(hls::stream<int>& A, hls::stream<int>& B, hls::stream<int>& C){
#pragma HLS dataflow
hls::stream<int> data_channel1;
hls::stream<int> data_channel2;
proc_1_1(A, data_channel1, data_channel2);
proc_1_2(B, C, data_channel1, data_channel2);
}
void proc_1_1(hls::stream<int>& A, hls::stream<int>& data_channel1, hls::stream<int>& data_channel2){
int i;
int tmp;
for(i = 0; i < 10; i++){
tmp = A.read();
data_channel1.write(tmp);
}
for(i = 0; i < 10; i++){
data_channel2.write(tmp);
}
}
void proc_1_2(hls::stream<int>& B, hls::stream<int>& C, hls::stream<int>& data_channel1, hls::stream<int>& data_channel2){
int i;
int tmp;
for(i = 0; i < 10; i++){
tmp = data_channel2.read() + data_channel1.read();
B.write(tmp);
}
for(i = 0; i < 10; i++){
C.write(tmp);
}
}
void proc_2(hls::stream<int>& A, hls::stream<int>& B, hls::stream<int>& C){
#pragma HLS dataflow
hls::stream<int> data_channel1;
hls::stream<int> data_channel2;
proc_2_1(A, B, data_channel1, data_channel2);
proc_2_2(C, data_channel1, data_channel2);
}
void proc_2_1(hls::stream<int>& A, hls::stream<int>& B, hls::stream<int>& data_channel1, hls::stream<int>& data_channel2){
int i;
int tmp;
for(i = 0; i < 10; i++){
tmp = A.read() + B.read();
data_channel1.write(tmp);
}
for(i = 0; i < 10; i++){
data_channel2.write(tmp);
}
}
void proc_2_2(hls::stream<int>& C, hls::stream<int>& data_channel1, hls::stream<int>& data_channel2){
int i;
int tmp;
for(i = 0; i < 10; i++){
tmp = data_channel2.read() + data_channel1.read();
C.write(tmp);
}
}与原示例相比,去掉了“&”符号。
#pragma HLS INTERFACE ap_fifo port=&A
#pragma HLS INTERFACE ap_fifo port=&B以上 kernel 的功能框图:
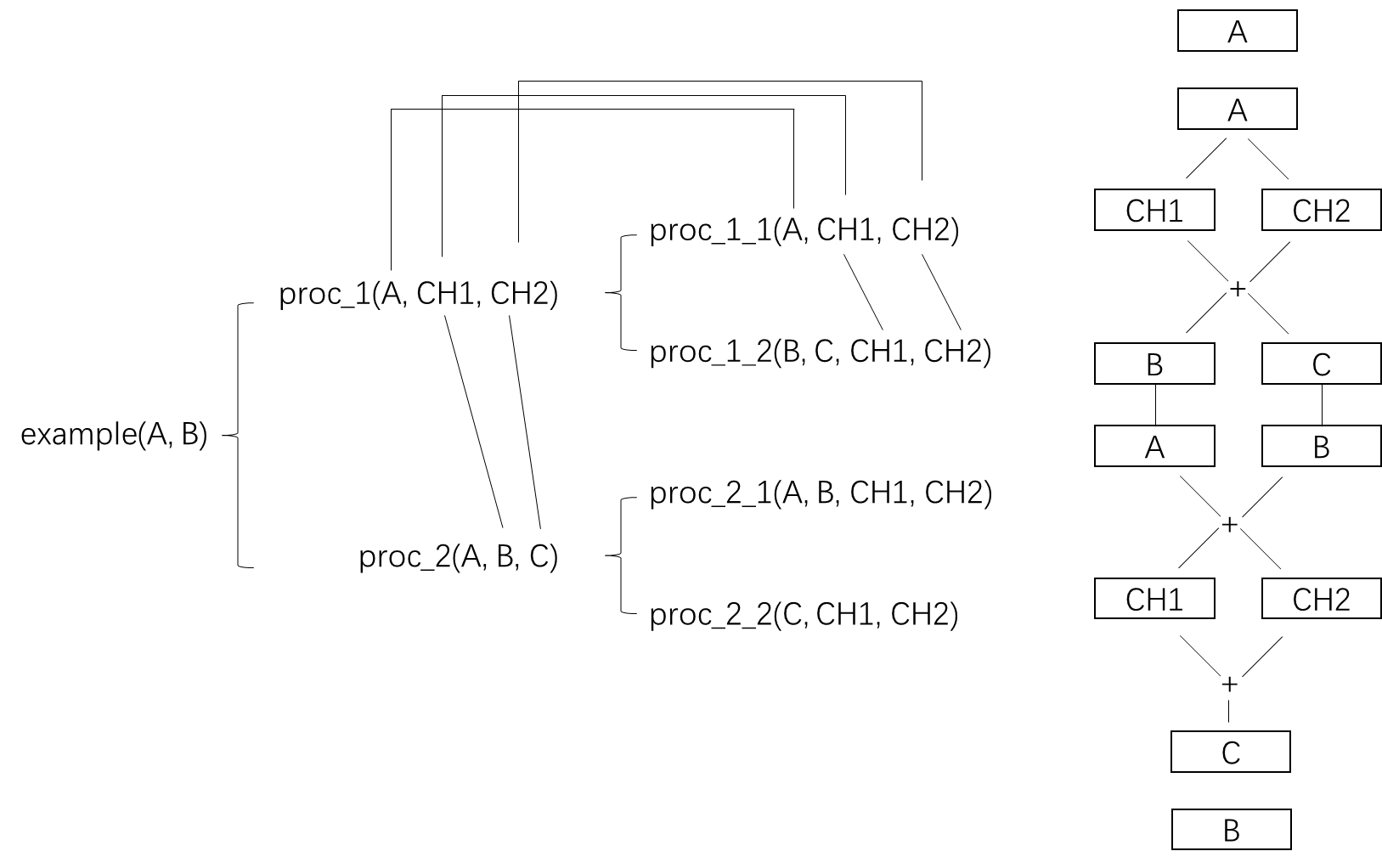
2.2 查看接口报告

对于顶层文件,可以查看 example_csynth.rpt,观察顶层接口:
================================================================
== Interface
================================================================
* Summary:
+-----------+-----+-----+------------+--------------+--------------+
| RTL Ports | Dir | Bits| Protocol | Source Object| C Type |
+-----------+-----+-----+------------+--------------+--------------+
|A_dout | in| 32| ap_fifo| A| pointer|
|A_empty_n | in| 1| ap_fifo| A| pointer|
|A_read | out| 1| ap_fifo| A| pointer|
|B_din | out| 32| ap_fifo| B| pointer|
|B_full_n | in| 1| ap_fifo| B| pointer|
|B_write | out| 1| ap_fifo| B| pointer|
|ap_clk | in| 1| ap_ctrl_hs| example| return value|
|ap_rst | in| 1| ap_ctrl_hs| example| return value|
|ap_start | in| 1| ap_ctrl_hs| example| return value|
|ap_done | out| 1| ap_ctrl_hs| example| return value|
|ap_ready | out| 1| ap_ctrl_hs| example| return value|
|ap_idle | out| 1| ap_ctrl_hs| example| return value|
+-----------+-----+-----+------------+--------------+--------------+
针对 Dataflow 区域的每个函数体,均有对应的 Interface:

================================================================
== Interface
================================================================
* Summary:
+-------------------------------+-----+-----+------------+----------------+--------------+
| RTL Ports | Dir | Bits| Protocol | Source Object | C Type |
+-------------------------------+-----+-----+------------+----------------+--------------+
|ap_clk | in| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_rst | in| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_start | in| 1| ap_ctrl_hs| proc_1_1| return value|
|start_full_n | in| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_done | out| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_continue | in| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_idle | out| 1| ap_ctrl_hs| proc_1_1| return value|
|ap_ready | out| 1| ap_ctrl_hs| proc_1_1| return value|
|start_out | out| 1| ap_ctrl_hs| proc_1_1| return value|
|start_write | out| 1| ap_ctrl_hs| proc_1_1| return value|
|A_dout | in| 32| ap_fifo| A| pointer|
|A_empty_n | in| 1| ap_fifo| A| pointer|
|A_read | out| 1| ap_fifo| A| pointer|
|data_channel12_din | out| 32| ap_fifo| data_channel12| pointer|
|data_channel12_num_data_valid | in| 2| ap_fifo| data_channel12| pointer|
|data_channel12_fifo_cap | in| 2| ap_fifo| data_channel12| pointer|
|data_channel12_full_n | in| 1| ap_fifo| data_channel12| pointer|
|data_channel12_write | out| 1| ap_fifo| data_channel12| pointer|
|data_channel23_din | out| 32| ap_fifo| data_channel23| pointer|
|data_channel23_num_data_valid | in| 2| ap_fifo| data_channel23| pointer|
|data_channel23_fifo_cap | in| 2| ap_fifo| data_channel23| pointer|
|data_channel23_full_n | in| 1| ap_fifo| data_channel23| pointer|
|data_channel23_write | out| 1| ap_fifo| data_channel23| pointer|
+-------------------------------+-----+-----+------------+----------------+--------------+上述报告 Source Object 所在列:
- A - > hls::stream<int>& A, C type 为 pointer
- data_channel12 -> hls::stream<int>& data_channel1, C type 为 pointer
- data_channel23 -> hls::stream<int>& data_channel2, C type 为 pointer
void proc_1_1(hls::stream<int>& A, hls::stream<int>& data_channel1, hls::stream<int>& data_channel2){
int i;
int tmp;
for(i = 0; i < 10; i++){
tmp = A.read();
data_channel1.write(tmp);
}
for(i = 0; i < 10; i++){
data_channel2.write(tmp);
}
}2.3 TestBench
#include <stdio.h>
#include "hls_stream.h"
#define SIZE 10
extern void example(hls::stream<int>& A, hls::stream<int>& B);
int main()
{
int i;
hls::stream<int> A;
hls::stream<int> B;
int time = 0;
for (time = 0 ; time < 4; time ++) {
for(i=0; i < SIZE; i++){
A << (i + time);
}
example(A,B);
}
return 0;
}2.4 Dataflow 报告
运行 C Synthesis 后,可以查看 Dataflow 报告,如下图,没有问题。

在运行 C/RTL Cosimulation 后,同样在 Dataflow 报告中可以看到错误。

3. Takeaways
总结而言,Dataflow查看器实现了以下吞吐量分析任务:
图表展示了 DATAFLOW 区域的整体拓扑结构,并显示了在 DATAFLOW 区域中任务之间用于通信的通道类型(FIFO/PIPO)。通过分析每个通道和进程,可以有效地解决死锁或由于FIFO大小不当导致的吞吐量不足等问题。
协同仿真数据通过在仿真过程中跟踪FIFO的最大使用量,为解决FIFO大小设置问题提供了参考依据,从而帮助用户调整FIFO大小。此外,运行协同仿真时的自动死锁检测功能能够突出显示涉及死锁的进程和通道,使用户能够快速定位并解决这些问题。
除了 FIFO 大小的调整,协同仿真后的数据还能按每个进程和通道报告因等待输入或输出而导致的停滞时间。这些图表帮助用户理解并解决这些问题,同时管理通道大小以满足慢速生产者与快速消费者之间的需求,或者相反。此外,图表还揭示了在DATAFLOW区域中途读取输入如何影响整体性能,这是一个常见的场景,可能会对性能产生重大影响。
4. 总结
在数据流优化中,通道类型、握手机制、FIFO大小和死锁避免都是关键因素。通过Dataflow查看器和协同仿真数据,您可以有效地优化设计,提高性能并避免潜在问题。
















 4419
4419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









