




 SSD是一种单阶段的目标检测网络,采用VGG作为主干网络,通过在不同尺度的特征图上设计先验框来检测不同大小的目标。在VOC2007test上达到74.3%的mAP,速度可达59FPS。SSD在6个不同尺度的特征图上设计先验框,用于分类和回归的损失函数包括分类损失和定位损失。
SSD是一种单阶段的目标检测网络,采用VGG作为主干网络,通过在不同尺度的特征图上设计先验框来检测不同大小的目标。在VOC2007test上达到74.3%的mAP,速度可达59FPS。SSD在6个不同尺度的特征图上设计先验框,用于分类和回归的损失函数包括分类损失和定位损失。
SSD:Single Shot MultiBox Detector
网络介绍
1.网络简介
本文是一个single stage的网络,整体比较简单,SSD主要根据每个feature map位置不同的纵横比和比例,将边界框的输出空间离散为一组默认框。对于300x300的图片输入,SSD在VOC2007 test上能够达到74.3%的mAP,同时在NVIDIA显卡Tittan X上速度为59FPS;同时,在输入图片是512x512的情况,SSD能达到76.9% mAP,甚至超过了Faster R-CNN。
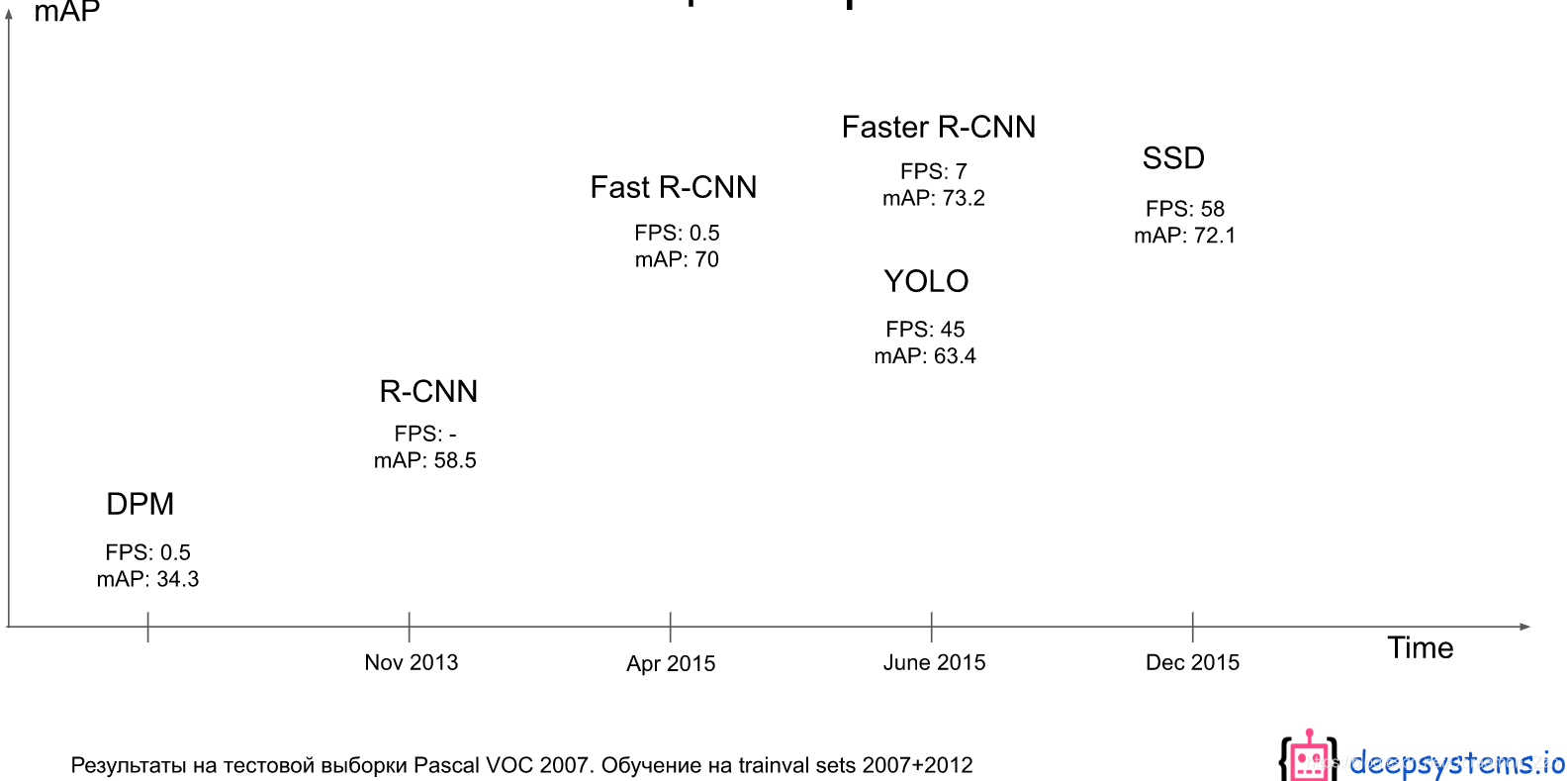
这里是和一些网络的比较。
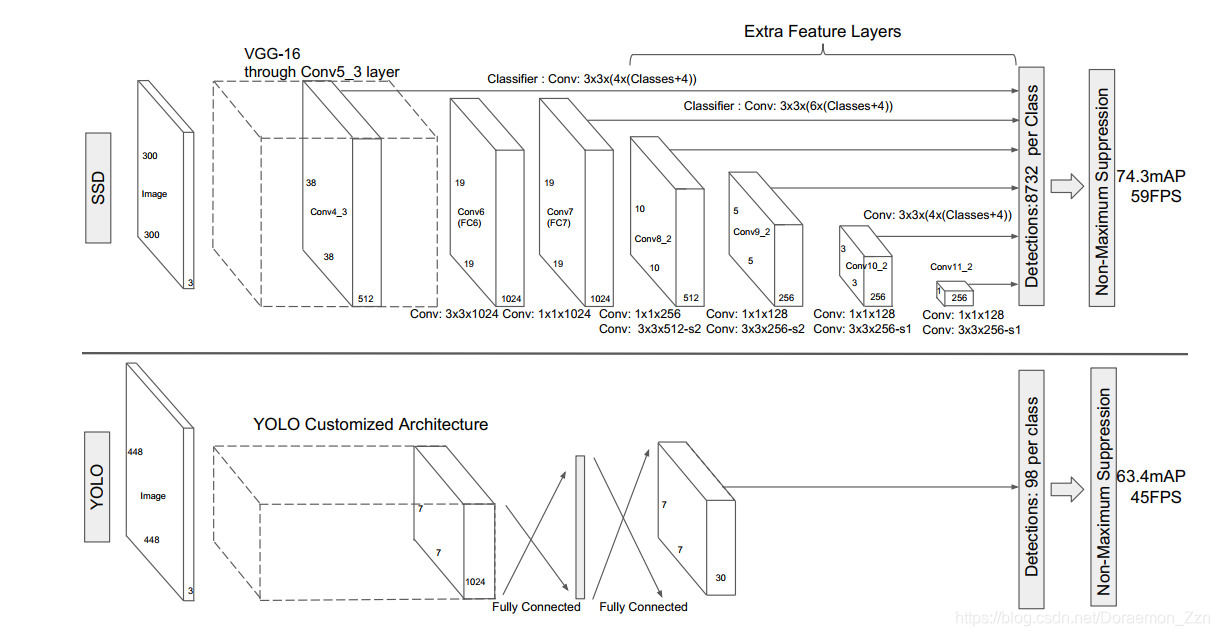
2.1SSD-Model
主干网络
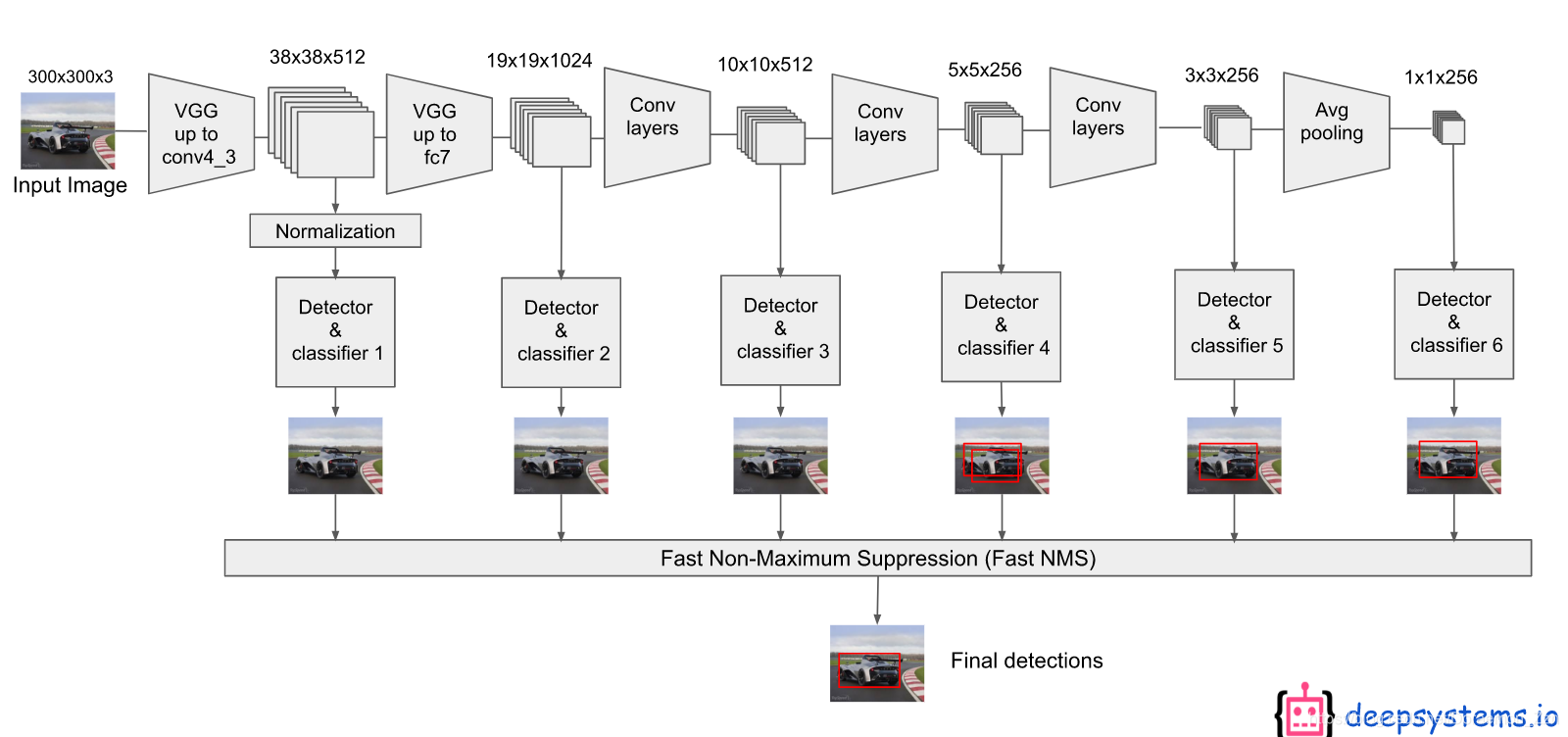
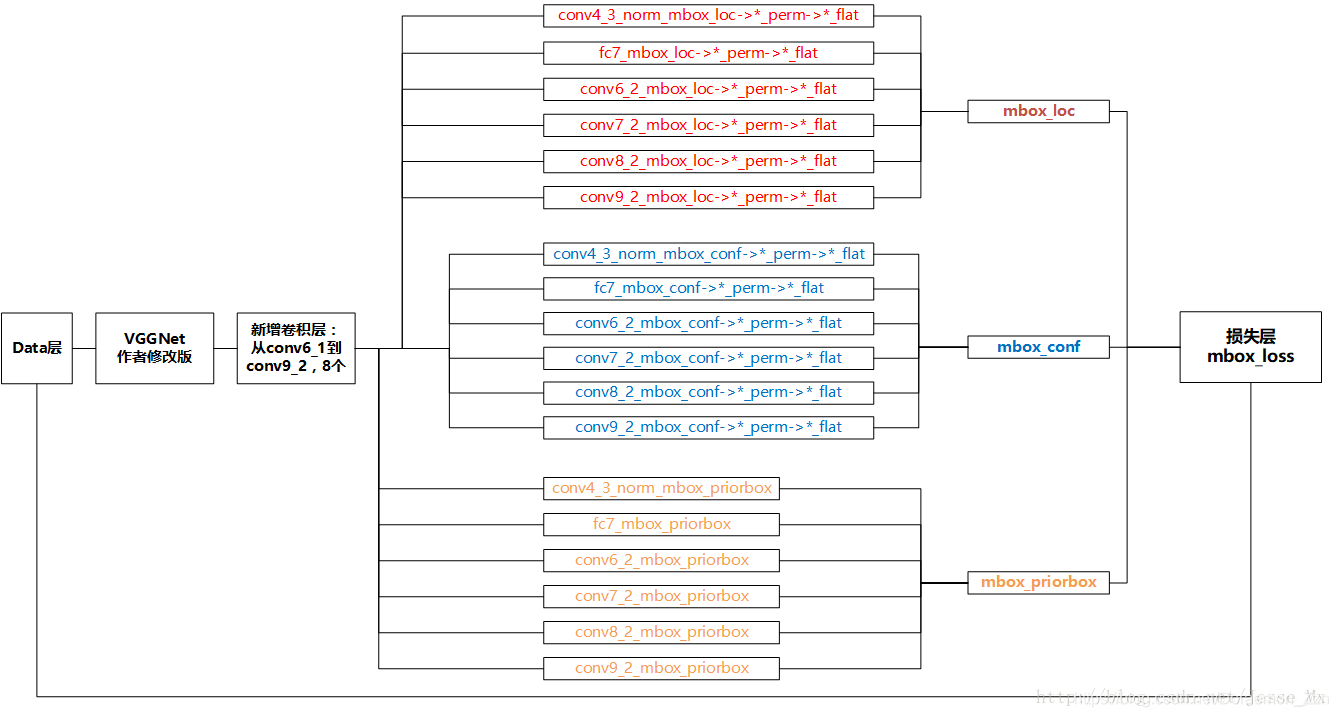
原文网络结构如下:
前面是一个BackBone,使用的是VGG网络,用于特征提取,与VGG的区别是把FC6和FC7换成了卷积层,SSD在后面又加了8个卷积层。最终预测的是这些prior boxs,也就是先验框(就和Faster R-CNN中的Anchor类似),与Faster R-CNN不同的是,SSD是对这些不同scale和不同aspect ratios的 bounding box进行预测,中间无RPN过程,是直接对这些框进行处理,所以是one-stage网络。
2.2SSD-训练
先验框和gt的匹配方法
原文说的是根据jaccard overlap(其实就是IOU)。正样本:>0.5。
损失函数
分类和回归的损失函数如式子123所示:
N是匹配成功的正样本数量,如果N=0,则令 loss=0
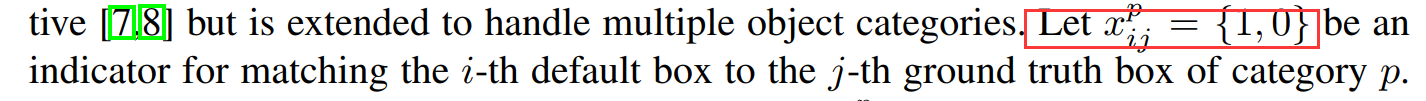
正样本是为1
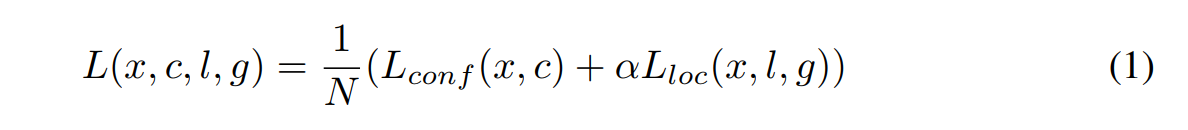

对筛选后的先验框进行处理分类和回归,对于confidence使用的是softmax函数,对于localization使用的是Smooth L1函数。
注: 定位损失中是只有正样本的损失的,而分类损失中是包含了正样本和负样本的。因为对于定位问题来说,只要回归出精确的变换关系,在预测的时候是不需要区分正负样本的(或者说是依靠分类来区分的),只需要将这个变换关系应用到所有的default box,最后使用NMS过滤掉得分少的样本框即可。但是分类就不一样了,分类是需要区分出正负样本的。
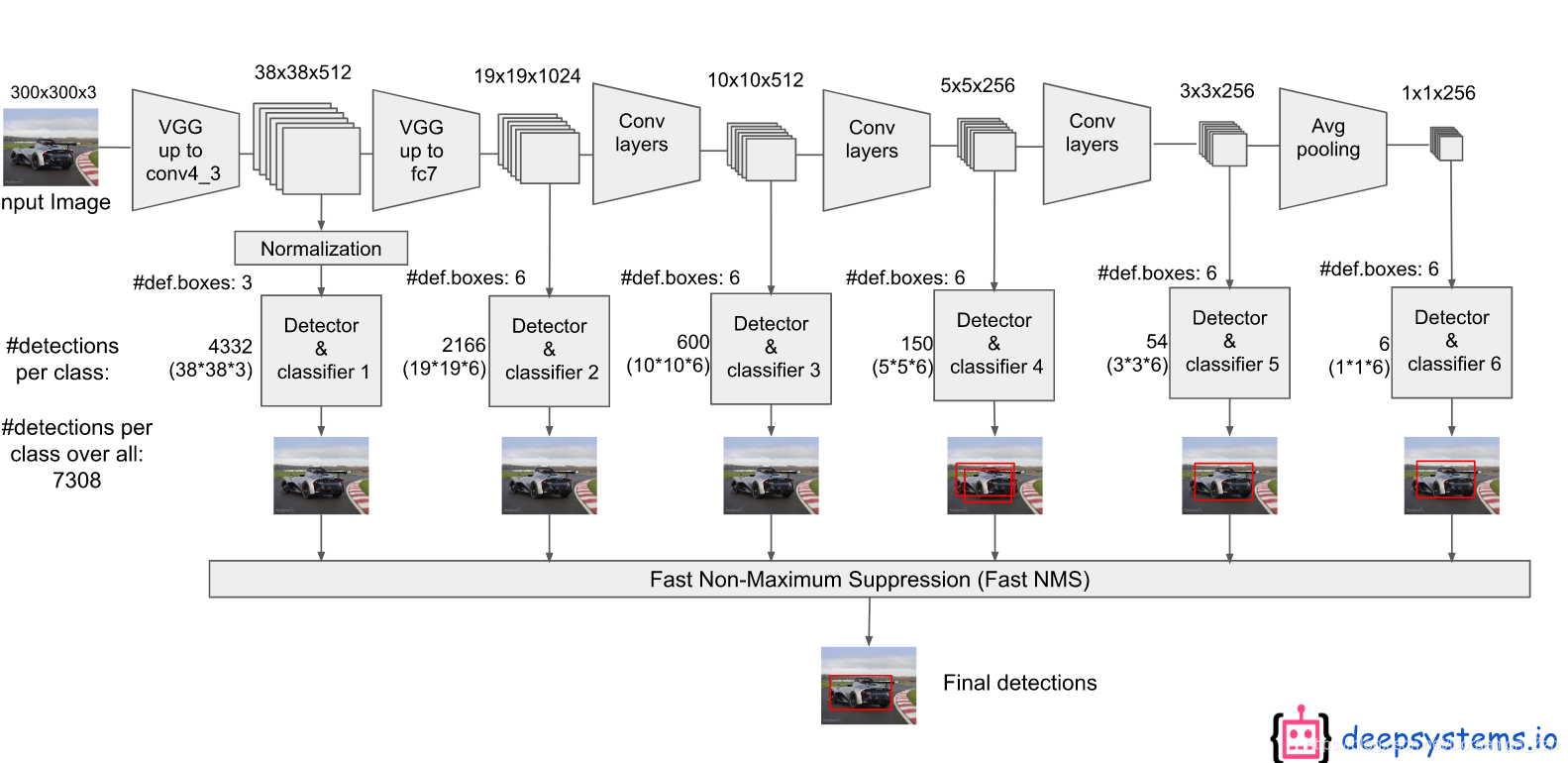
根据网络结构来看SSD不是在一个feature map上进行框的设计,而是在6个不同尺度都设计了先验框。主要在浅层的feature map上设立较小的先验框来检测小物体,在深层的feature map上设立较大的先验框来负责大物体的检测。
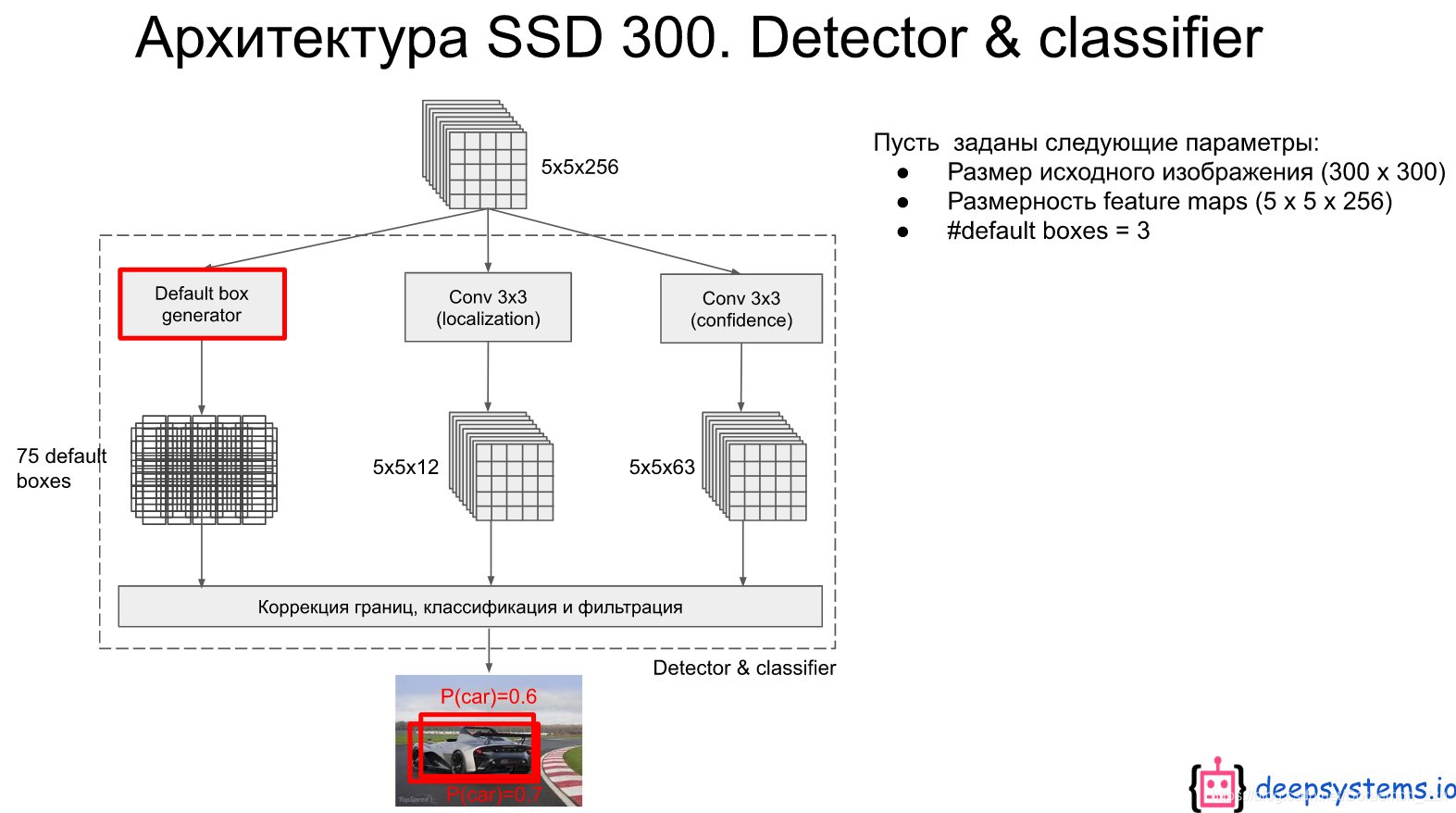
先验框
对于6个不同尺度的feature map,生成的先验框数为4,6,6,6,4,4。
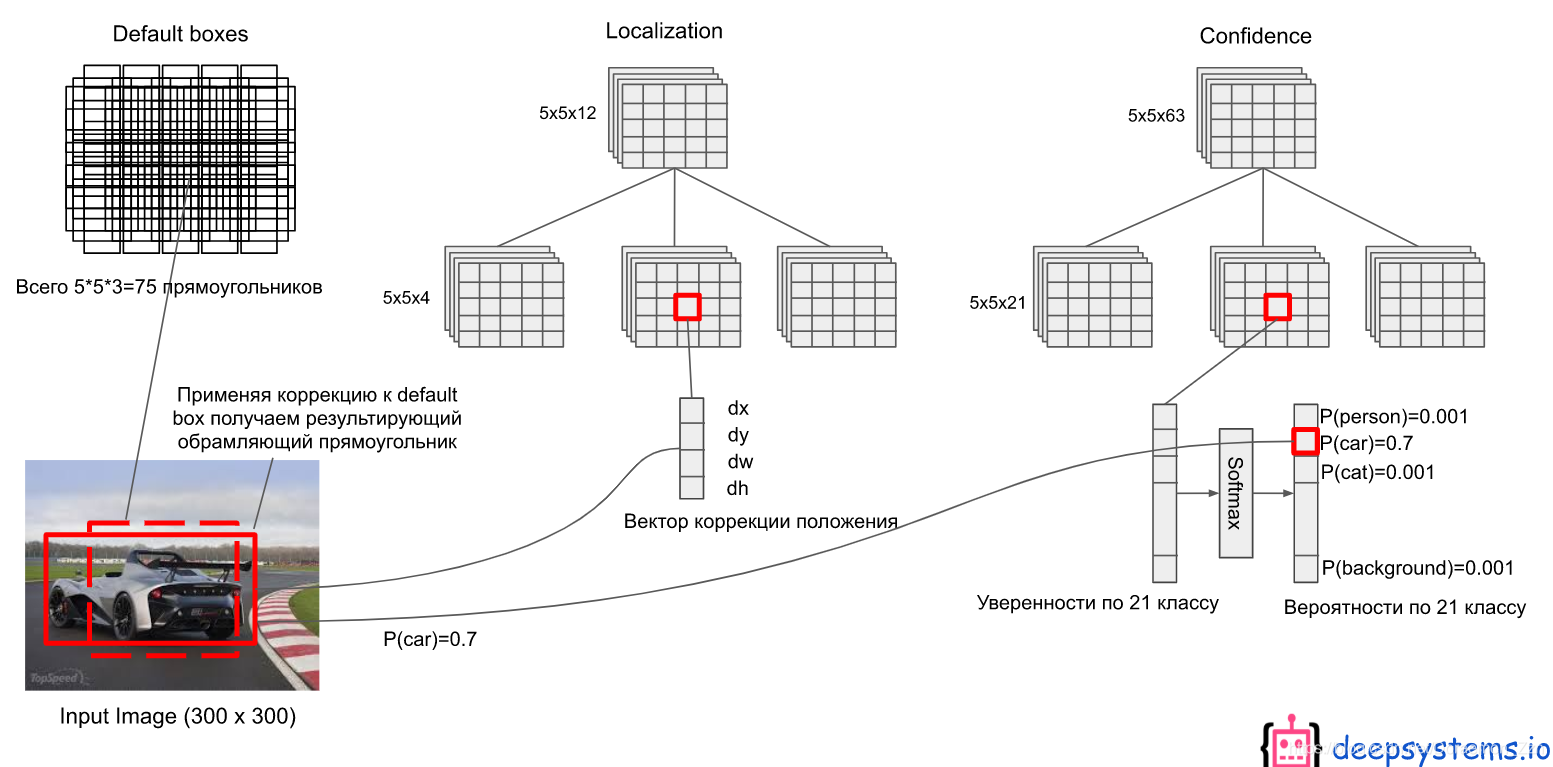
对于6个不同尺度的输出:举个栗子,第4层的feature map是5x5x256来说,先生成一些先验框,这里5x5的feature map上每个点生成3个不同大小的先验框共计75个(原文中这里是6个框,共计150个)。用于定位的卷积层输出是 5×5×12 的(4×3=12,每个通道代表一个位置因素(x,y,w,h)),用于分类的卷积层输出是 5×5×63的(21×3=63,每个通道代表一个类别)
总共是8732个框。
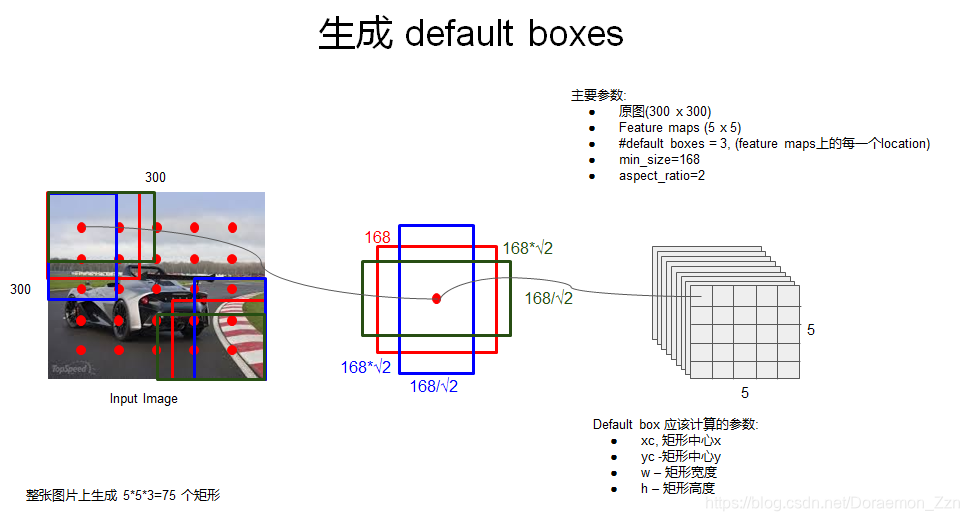
对每一个feature map中先验框的具体大小,主要用的是下面的公式。。公式中k对应1,2,3,4,5,6。分别对应SSD的第4、7、8、9、10、11卷积层。

在 4×4 的feature map中只有狗(红色框)是正样本,这是因为 不同的feature map 负责预测的 scale和aspect ratio是不同的,所以在 8×8 的feature map中由于猫的scale不匹配,会被认为是负样本。同理,在 8×8 的feature map中只有猫(蓝色框)是正样本。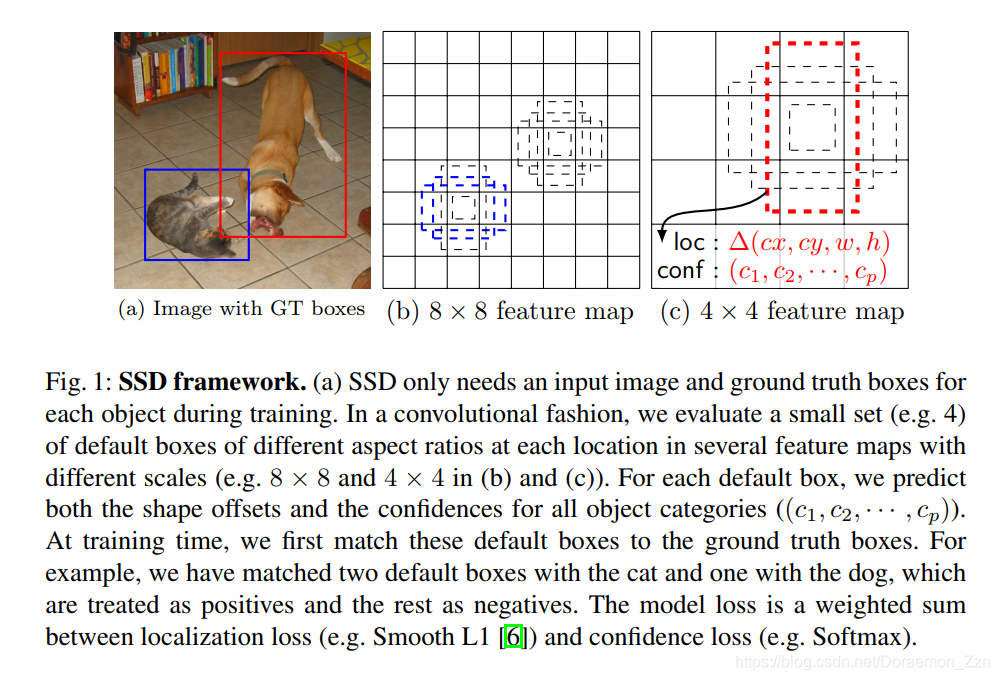
难样本挖掘
完成正负样本匹配后,因为一般一幅图中物体数量不会太多,所以负样本很多。如果将所有负样本都考虑,正样本的贡献就很小了。Faster R-CNN是限制正负样本的数量来控制正负样本的(proposal选256个,正负样本1:1)。
本文做法是对负样本根据 confidence loss(也就是分类损失)排序,选取损失最高的一部分保留(也就是最不像目标的那些),使得负样本和正样本的比例保持在 3:1。
数据增强
每张训练图像随机进行如下操作:
- 使用原图
- 在原图上采样一个patch,这些patch与目标的杰卡德系数(IOU)为 0.1, 0.3, 0.5, 0.7, 或者 0.9
- 随机采样一个patch
采样的patch与原图的比例在[0.1-0.9]之间,aspect ratio在 1/2 到 2之间。经过以上采样之后,采样的patch会被resize到固定大小并以0.5的概率进行水平翻转。
训练流程总结-图
预测
举个栗子,对某个BBox进行cls和loc
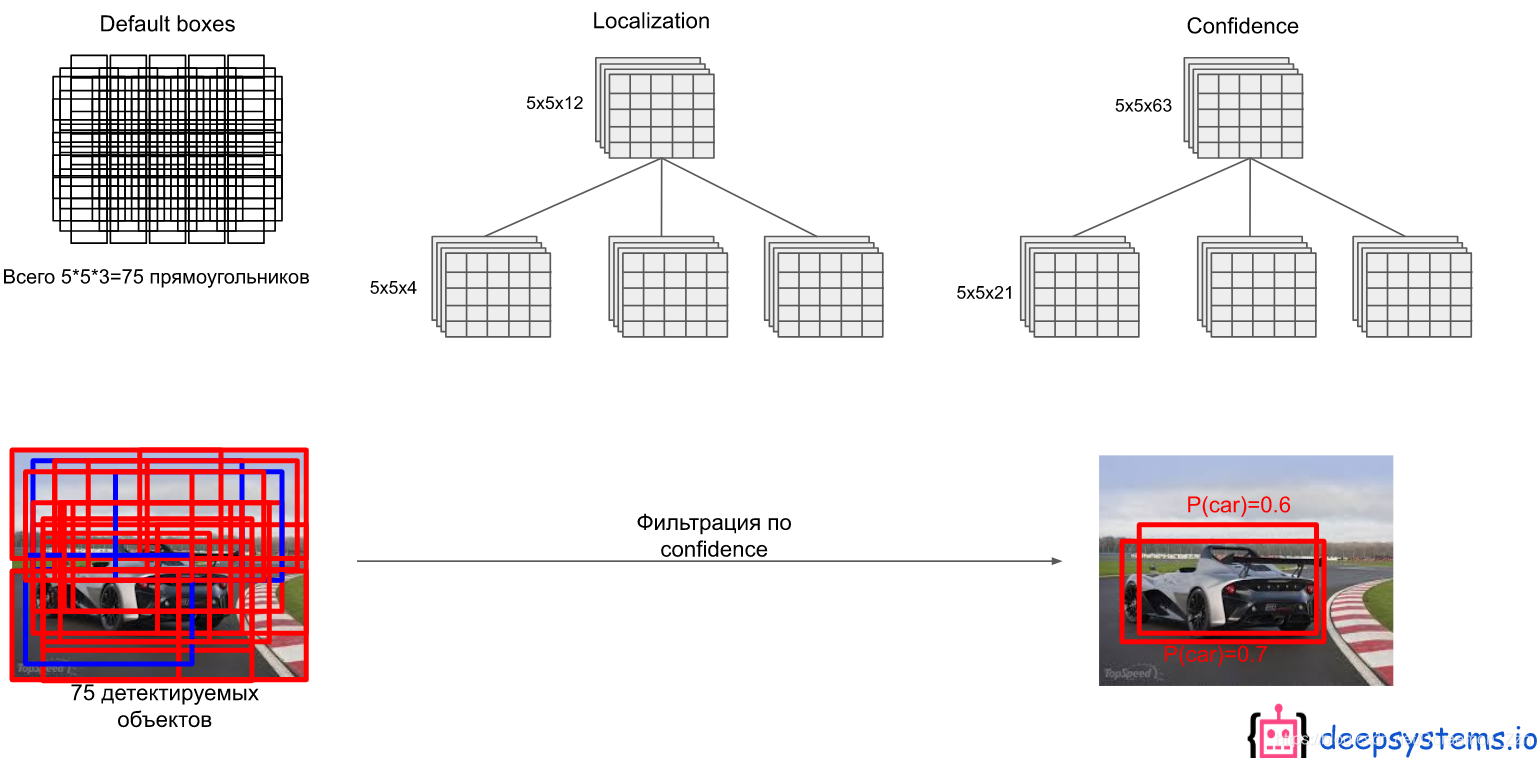
所有的bounding box回归之后,是很乱的,然后再通过NMS过滤掉一大部分:
当把所有用于预测的feature map进行预测之后(multi-scale),再通过一个NMS,又过滤掉一部分,保留下来的即是最终的结果
数据集
1.PASCAL VOC2007
2.PASCAL VOC2012
3.CoCo
参考
1.SSD的PPT,很清楚,本文图的来源(需要梯子)
2.https://arleyzhang.github.io/articles/786f1ca3/

















 1821
1821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









