







目录
agg
agg方法可以被groupby,DataFrame,Series等对象调用。官网文档
语法:
df.agg(func, axis=0, *args, **kwargs)
参数:
func : function, str, list or dict
Function to use for aggregating the data. If a function, must either
work when passed a DataFrame or when passed to DataFrame.apply.
Accepted combinations are:
- function
- string function name
- list of functions and/or function names, e.g. ``[np.sum, 'mean']``
- dict of axis labels -> functions, function names or list of such.
axis : {0 or 'index', 1 or 'columns'}, default 0
If 0 or 'index': apply function to each column.
If 1 or 'columns': apply function to each row.
*args
Positional arguments to pass to `func`.
**kwargs
Keyword arguments to pass to `func`.
func可以是function, str, list或dict,可以接受的形式有函数、函数名称的字符串、函数列表或字典。
agg可以直接以字符串的形式使用pandas和Python内置的函数,也可以使用用户自定义的函数,并且有axis参数。
还可以一次性传入多个函数,给函数设置计算结果的列名,支持对不同的series使用不同的函数(以字典形式传参)。
本方法主要用于聚合,首先对Frame对象的各行(或列)进行计算并得到标量聚合结果,然后汇总所有组的聚合结果为一个数组。
df=DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
df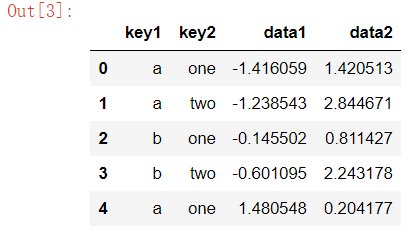
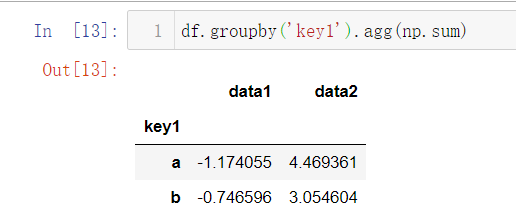
1)与groupby一起使用,可以传入标准的函数std,sum,mean,max,min
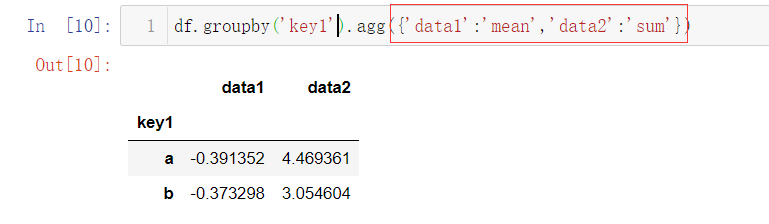
还可以对每列数据使用不同的聚合函数,那就给agg传入一个字典。
groupby和agg都可以传入列表形式的参数

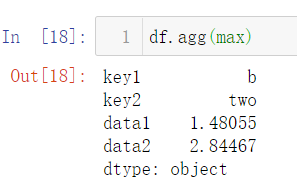
2)直接对DataFrame使用
3)给agg传入一个自定义的函数
df2 = DataFrame({'类别':['水果','水果','水果','蔬菜','蔬菜','肉类','肉类'],
'产地':['美国','中国','中国','中国','新西兰','新西兰','美国'],
'种类':['苹果','梨','草莓','番茄','黄瓜','羊肉','牛肉'],
'数量':[5,5,9,3,2,10,8],
'价格':[5,5,10,3,3,13,20]})
df2
'''
类别 产地 种类 数量 价格
0 水果 美国 苹果 5 5
1 水果 中国 梨 5 5
2 水果 中国 草莓 9 10
3 蔬菜 中国 番茄 3 3
4 蔬菜 新西兰 黄瓜 2 3
5 肉类 新西兰 羊肉 10 13
6 肉类 美国 牛肉 8 20
'''自定义一个函数:
def ptp(arr):
return arr.max()-arr.min()给agg传入参数
#不同的列用不同的聚合函数
mapping={'数量':np.sum,'价格':ptp}
df2.groupby('类别').agg(mapping)
'''
数量 价格
类别
水果 19 5
肉类 18 7
蔬菜 5 0
'''transform
语法:
df.transform(func, axis=0, *args, **kwargs)
Parameters
----------
func : function, str, list or dict
Function to use for transforming the data. If a function, must either
work when passed a DataFrame or when passed to DataFrame.apply.
Accepted combinations are:
- function
- string function name
- list of functions and/or function names, e.g. ``[np.exp. 'sqrt']``
- dict of axis labels -> functions, function names or list of such.
axis : {0 or 'index', 1 or 'columns'}, default 0
If 0 or 'index': apply function to each column.
If 1 or 'columns': apply function to each row.
*args
Positional arguments to pass to `func`.
**kwargs
Keyword arguments to pass to `func`.transform方法可以被groupby、resampler、dataframe、series等对象调用。官方文档
func与agg中的func的说明完全相同。
其特点是,按元素进行操作,所以输入dataframe与输出dataframe的大小完全相同。
本方法同样支持对不同的轴调用不同的函数,以及通过字符串形式调用内置函数。
transform可以实现的操作,apply都可以,但是反之不成立。同agg一样,与内建函数一起使用时,比apply速度快。
在groupby对象中执行函数时,会同时使用元素的信息和所在组的信息。
df2[['类别','价格']].groupby('类别').transform(lambda x:x-x.mean())
'''
价格
0 -1.666667
1 -1.666667
2 3.333333
3 0.000000
4 0.000000
5 -3.500000
6 3.500000
'''
s=Series(range(3))
s
'''
0 0
1 1
2 2
dtype: int64
'''
s.transform([np.sqrt,np.exp])
'''
sqrt exp
0 0.000000 1.000000
1 1.000000 2.718282
2 1.414214 7.389056
'''apply
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
参数的官方文档
agg可以做的,好像apply都可以做,所以apply比agg更加灵活,更一般化,但是调用Python内置函数和pandas函数时,运行速度比agg慢。
不同的是apply还能传入自定义参数(自定义函数),而且支持在同一个dataframe的不同series间进行运算,当应用的不是聚合函数时,就是对每个元素的逐一操作。
其返回值可以是标量也可以是Series、DataFrame对象。
applymap先应用apply再对每个Series使用map,可实现逐个元素操作。















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









