







源码地址:https://recognize-anything.github.io/
Abstract
主要内容 RAM 算法:
- 提出了 Recognize Anything Model(RAM),一个强的基础模型用于image tagging,表现出在各种常见类别上的高精度的零样本泛化能力
- RAM 提出了新的image tagging 范式,利用图像文本对训练,而不是手工标注数据
RAM 由四部分组成:
- 通过 自动文本语义解析(automatic text semantic parsing) 图像文本对的文本中提取图像的 tags (annotation-free image tags)
- 初步模型使用自动标注训练。训练策略使用 image caption 和 image tagging 两个任务真值分别监督。
- 数据引擎(data engine) 用于生成额外的标注以及清除不正确的标注
- 使用处理(第三步)处理过后的数据,重新训练模型。然后使用更高质量的数据进行微调。
实验效果:
- 在大量的 benchmark 上测试 RAM 的 image tagging 能力,观察到了强大的零样本泛化能力,超过了 CLIP,BLIP
- RAM 超过了使用监督训练的模型,和 Google tagging API 由相当的能力。

Introduction
故事逻辑:
- 大语言模型,通过在 large-scale web dataset 数据集上训练,表现出了强大的零样本泛化能力。能够泛化到和训练数据不同域的任务和数据上(tasks and data distributions beyond training domain)
- SAM 同样表现出强大的零样本定位能力,通过扩展数据尺度;但是 SAM 缺少捕捉图像语义标签的能力
- 多标签图像识别,又称 image tagging 目标是提供给定图像的多个语义标签;图像标签任务是很重要且有用的计算机视觉任务,由于图像本质上包含了多个标签,(objects, scenes, attributes, and actions);然而现有的多标签分类、检测、分割以及视觉语言算法,都表现出了一定的缺陷(limit scopes,poor accuracy)
两个主要的缺点:
- 收集大规模的高质量的训练数据。具体来讲:缺少通义的标签系统和高效的数据注释引擎,去实现大量类别的大规模的自动或半自动的标注
- 缺少有效且灵活的模型设计,去充分利用大规模的弱监督数据构建开放词汇的强大的模型
为了解决上述问题,RAM 针对 标签系统、数据集、数据引擎和模型进行针对设计
- 通用和统一的标签系统 Label System(具体有哪些类别)。综合当前的公开的学术数据集(包括分类,检测和分割)以及商用标签产品的类别。最终的标签是合并所有的公共标签以及从文本中得到的常见标签。(6449个标签)。剩余的开放词汇标签,可以通过开集识别实现。
- 数据集 充分利用公开可获取的大规模的图像文本对(参考 CLIP,ALIGN)。通过自动的文本语义解析算法解析文本获得图像标签。通过这种方式,从图像文本对中获取了大量的无需标注的图像标签
- 数据引擎 通过文本语义解析得到的数据通常含还有噪声,缺失或含有不正确的标签,因此设计了 tagging data engine。利用现有模型生成标签,定位不同标签对应的区域,然后使用区域聚类region clustering techniques,识别和消除同义类别,并且过滤掉,相同区域含义相反的标签,确保更清晰和准确的注释
- 模型 Tag2Text 是之前的图像标签算法,只能识别固定的预定义好的类别。本文的RAM 能够泛化到位置类别,通过将语义信息结合到类别标签上。(开集识别)
受益于大规模的高质量的 image-tag-text 数据以及整合 tagging 以及 caption,RAM能够在有噪声的,无标注的数据上表现超过使用监督训练的模型。
- 强的泛化能力
- 成本低且容易复现,低成本的 open-source and annotation-free dataset;3-days 8 A100 GPUs training
- 灵活和多样,结合 Grounding DINO 和 SAM 的定位能力,能够实现强大的泛化视觉语义分析流程(RAM 识别图像标签,Grounding DINO 检测标签实例位置,SAM利用检测结果实现准确分割)
Method
Model Architecture
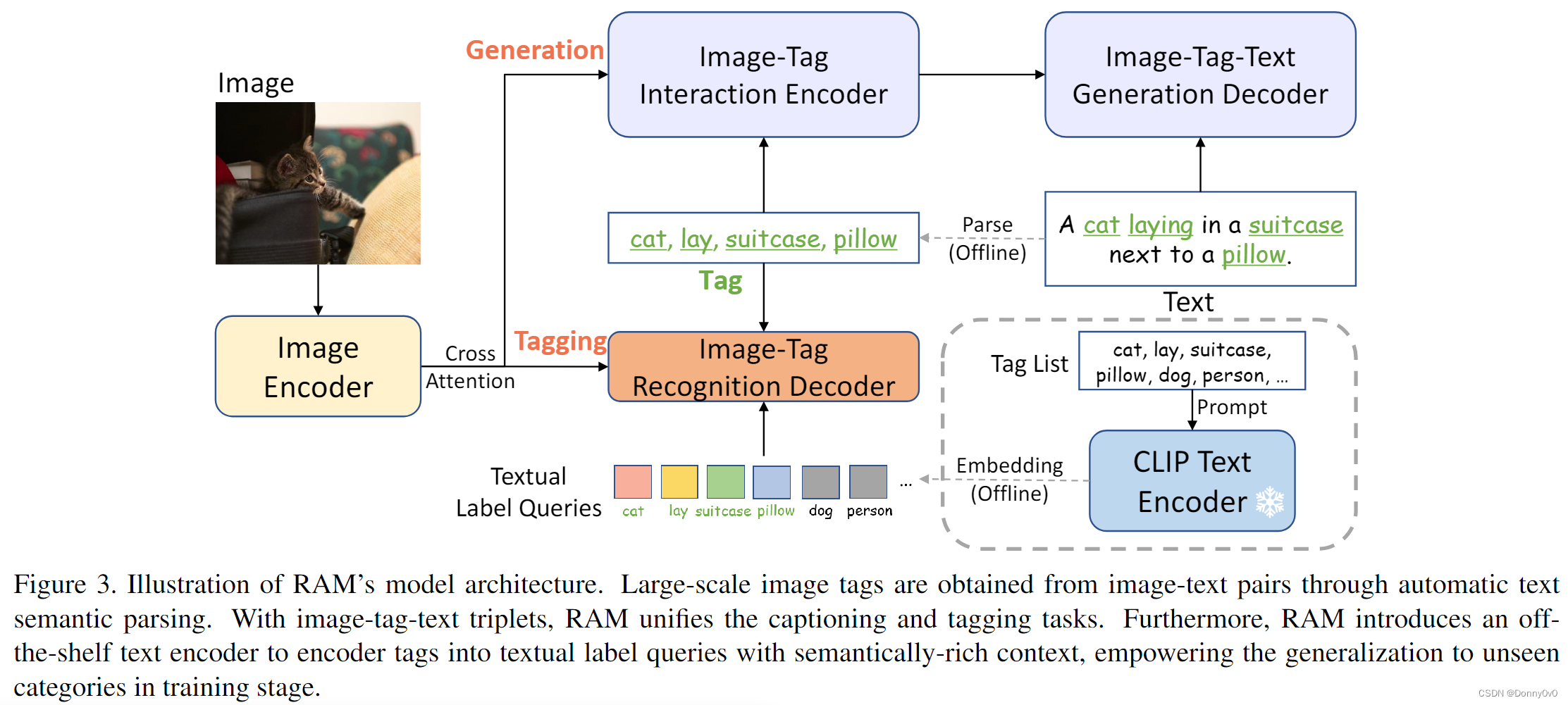
模型包括
- 图像编码器用于特征提取
- image-tag recognition decoder for tagging
- image-tag interaction encoder and decoder for generation
训练阶段,image-tag recognition decoder 用于预测 tags
推理阶段,image-tag recognition decoder 生成的 tags 用于指导 generation
这里的Recognition decoder 输入的每个query 在结果和图像特征的交叉注意力之后,会经过线性层 + sigmoid得到0~1的值,进行二分类,因为queries 是使用 文本的embedding,也就是说每个queries在初始化时就确定了语义。因此想实现开集,只需要在初始化时使用新类别的embedding进行初始化即可
![[Pasted image 20240508173313.png]]
Data Engine
- 训练baseline 使用原始的步骤训练一个baseline模型(使用图像文本对,以及文本解析的标签训练)
- 生成与合并 使用baseline 对训练集图像生成新的 caption 和 tags,合并生成的 tags 和 原始的 tags
- 清除 不正确的tags,使用 Grounding-DINO 识别tags对应的区域,对区域进行聚类,消除相关的tags;去除没有预测结果的 tags
实验
略~















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









