







本节开始涉及MapReduce的编程设计。
1. MapReduce基础
1.1 MapReduce1.0 模型简介
MapReduce最早是由Google公司提出的一种面向大规模数据处理的并行计算模型和方法。是Hadoop面向大数据并行处理的计算模型、框架和平台。
① MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce。
② 编程容易,不需要掌握分布式并行编程细节,也可以很容易把自己的程序运行在分布式系统上,完成海量数据的计算。
③ MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理.
④ MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销。
⑤ MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave。
⑥ Master上运行JobTracker,Slave上运行TaskTracker .
⑦ Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写 .
1.2 MapReduce1.0的缺陷
① 存在单点故障
② JobTracker“大包大揽”导致任务过重
③ 容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
④ 资源划分不合理(强制划分为slot,包括Map slot 和Reduce slot)
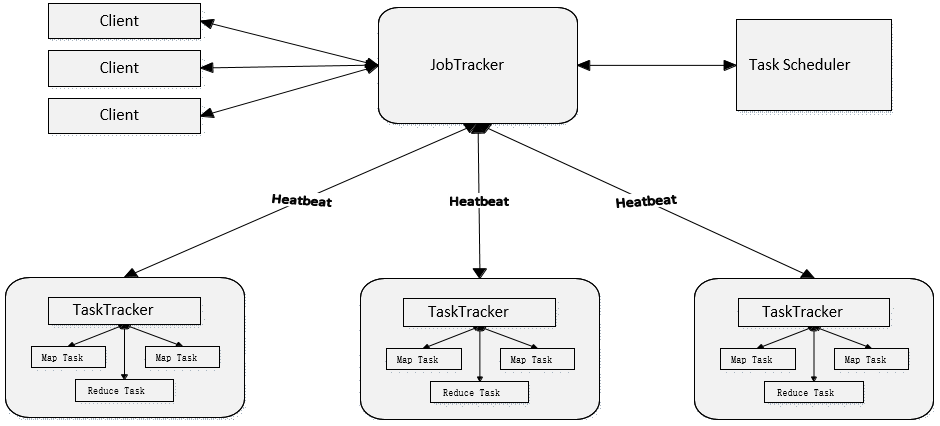
所以,综上,MapReduce1.0既是一个计算框架,也是一个资源管理调度框架。
1.3 MapReduce2.0框架介绍
Hadoop2.0以后,MapReduce1.0 中的资源管理调度功能被单独分离出来形成了YARN,它是一个存粹的资源管理调度框架。
被剥离了资源管理调度功能的MapReduce框架就变成了MapReduce2.0,它是运行在YARN之上的一个纯粹的计算框架,不再自己负责资源的调度管理服务,而是由YARN为其提供资源管理调度服务。
如下图:
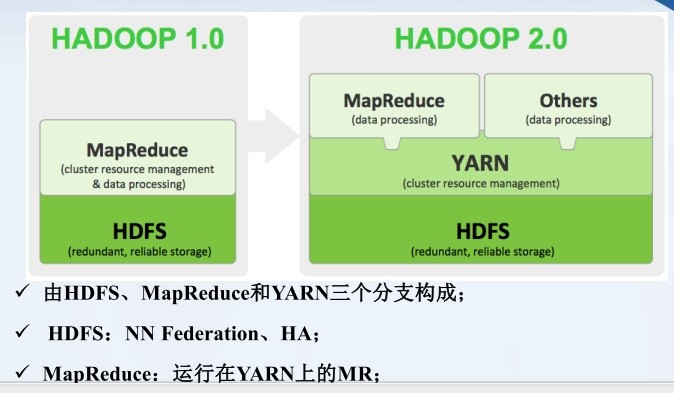
2. MapReduce2 运行原理
2.1 YARN简介
由于MapReduce2是基于YARN的运行原理,所以先简要介绍一下YARN。
2.1.1 YARN架构
YARN架构如下图,将Hadoop1.0的JobTacker三大功能进行拆分。
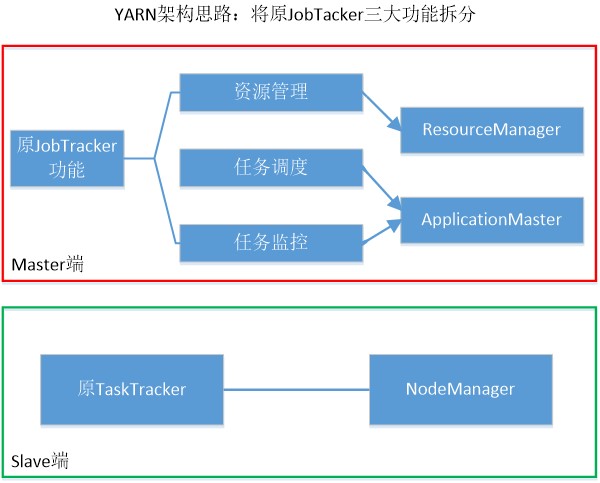
2.1.2 YARN体系结构
由ResourceManager、NodeManager
、ApplicationMaster以及Container组成。
功能分别如下:
- ResourceManager
① 处理客户端请求
② 启动/监控ApplicationMaster
③ 监控NodeManager
④ 资源分配与调度
- ApplicationMaster
① 为应用程序申请资源,并分配给内部任务
② 任务调度、监控与容错
- NodeManager
① 单个节点上的资源管理
② 处理来自ResourceManger的命令
③ 处理来自ApplicationMaster的命令
- Container
一个动态资源的单位。将资源抽象,封装了某个节点(可理解为NodeManager)的多维度资源,封装了内存、CPU、磁盘、网络等。
ResourceManager
① ResourceManager(RM)是一个全局的资源管理器,负责整个系统的资源管理和分配,主要包括两个组件,即调度器(Scheduler)和应用程序管理器(Applications Manager)
② 调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常会考虑应用程序所要处理的数据的位置,进行就近选择,从而实现“计算向数据靠拢”。
③ 容器(Container)作为动态资源分配单位,每个容器中都封装了一定数量的CPU、内存、磁盘等资源,从而限定每个应用程序可以使用的资源量
④ 调度器被设计成是一个可插拔的组件,YARN不仅自身提供了许多种直接可用的调度器,也允许用户根据自己的需求重新设计调度器
⑤ 应用程序管理器(Applications Manager)负责系统中所有应用程序的管理工作,主要包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动等
ApplicationMaster
ResourceManager接收用户提交的作业,按照作业的上下文信息以及从NodeManager收集来的容器状态信息,启动调度过程,为用户作业启动一个ApplicationMaster。
ApplicationMaster的主要功能是:
① 当用户作业提交时,ApplicationMaster与ResourceManager协商获取资源,ResourceManager会以容器的形式为ApplicationMaster分配资源;
② 把获得的资源进一步分配给内部的各个任务(Map任务或Reduce任务),实现资源的“二次分配”;
③ 与NodeManager保持交互通信进行应用程序的启动、运行、监控和停止,监控申请到的资源的使用情况,对所有任务的执行进度和状态进行监控,并在任务发生失败时执行失败恢复(即重新申请资源重启任务);
④ 定时向ResourceManager发送“心跳”消息,报告资源的使用情况和应用的进度信息;
⑤ 当作业完成时,ApplicationMaster向ResourceManager注销容器,执行周期完成。
NodeManager
NodeManager是驻留在一个YARN集群中的每个节点上的代理,主要负责:
容器生命周期管理
监控每个容器的资源(CPU、内存等)使用情况
跟踪节点健康状况
以“心跳”的方式与ResourceManager保持通信
向ResourceManager汇报作业的资源使用情况和每个容器的运行状态
接收来自ApplicationMaster的启动/停止容器的各种请求
需要说明的是,NodeManager主要负责管理抽象的容器,只处理与容器相关的事情,而不具体负责每个任务(Map任务或Reduce任务)自身状态的管理,因为这些管理工作是由ApplicationMaster完成的,ApplicationMaster会通过不断与NodeManager通信来掌握各个任务的执行状态
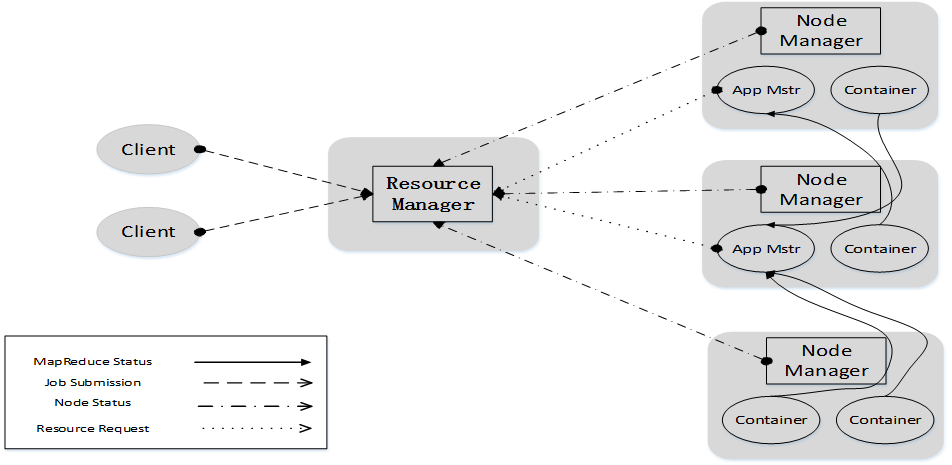
2.1.3 YARN工作流程
如下图:
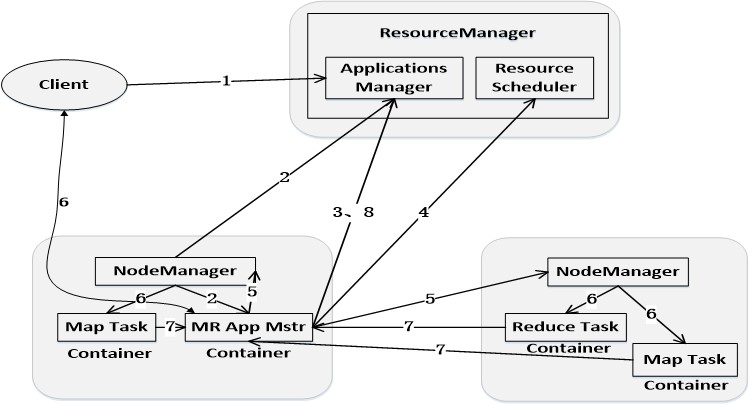
① 用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
② YARN中的ResourceManager负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个ApplicationMaster。
③ ApplicationMaster被创建后会首先向ResourceManager注册
④ ApplicationMaster采用轮询的方式向ResourceManager申请资源
⑤ ResourceManager以“容器”的形式向提出申请的ApplicationMaster分配资源
⑥ 在容器中启动任务(运行环境、脚本)
⑦ 各个任务向ApplicationMaster汇报自己的状态和进度
⑧ 应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己。
2.2 MapReduce执行流
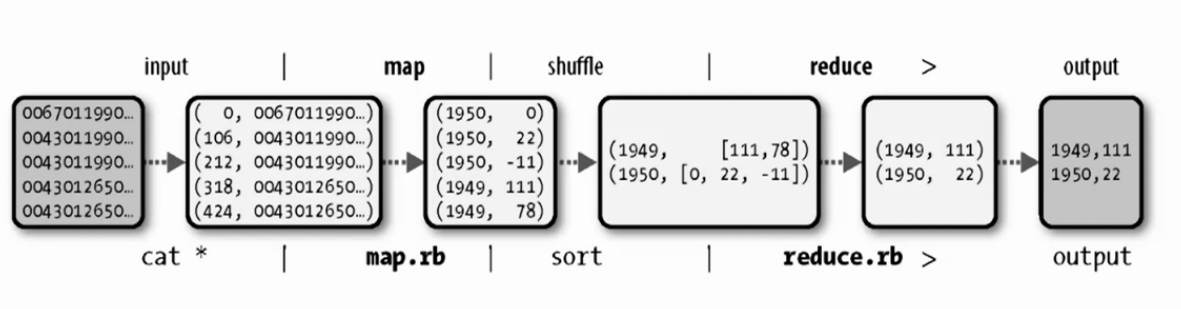
input -> map -> shuffle -> reduce -> output
shuffle是MapReduce的核心,主要用于优化等操作。
① 不同的Map任务之间不会进行通信
② 不同的Reduce任务之间也不会发生任何信息交换
③ 用户不能显式地从一台机器向另一台机器发送消息
④ 所有的数据交换都是通过MapReduce框架自身去实现的
2.3 Shuffle过程详解
2.3.1 Shuffle过程介绍
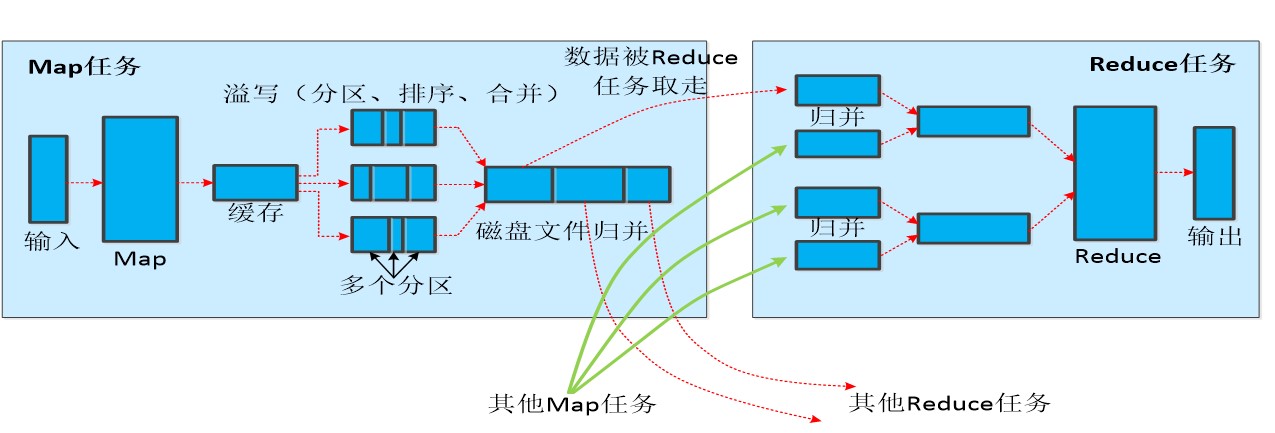
2.3.2 Map端的Shuffle过程
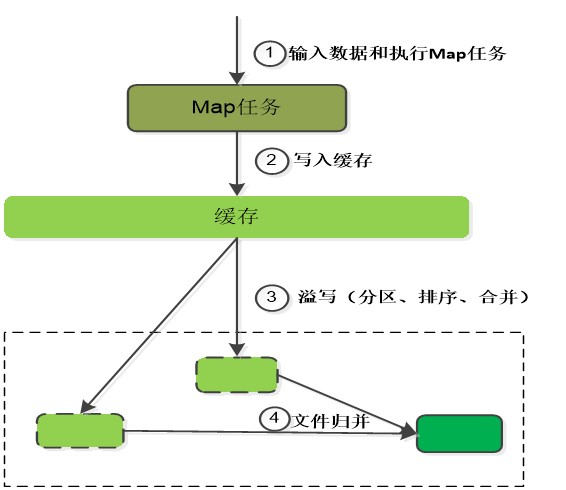
- 每个Map任务分配一个缓存
MapReduce默认100MB缓存 - 设置溢写比例0.8
- 分区默认采用哈希函数
- 排序是默认的操作
- 排序后可以合并(Combine)
合并不能改变最终结果
在Map任务全部结束之前进行归并
- 归并得到一个大的文件,放在本地磁盘
- 文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner,少于3不需要
合并(Combine)和归并(Merge)的区别:
两个键值对<“a”,1>和<“a”,1>,如果合并,会得到<“a”,2>,如果归并,会得到<“a”,<1,1>>
2.3.3 Reduce端的Shuffle过程
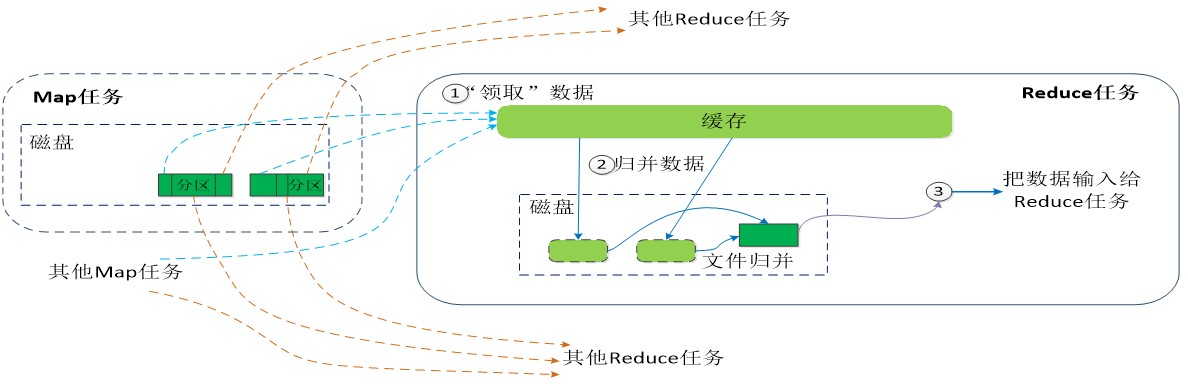
- Reduce任务通过RPC询问Map任务是否已经完成,若完成,则领取数据
- Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
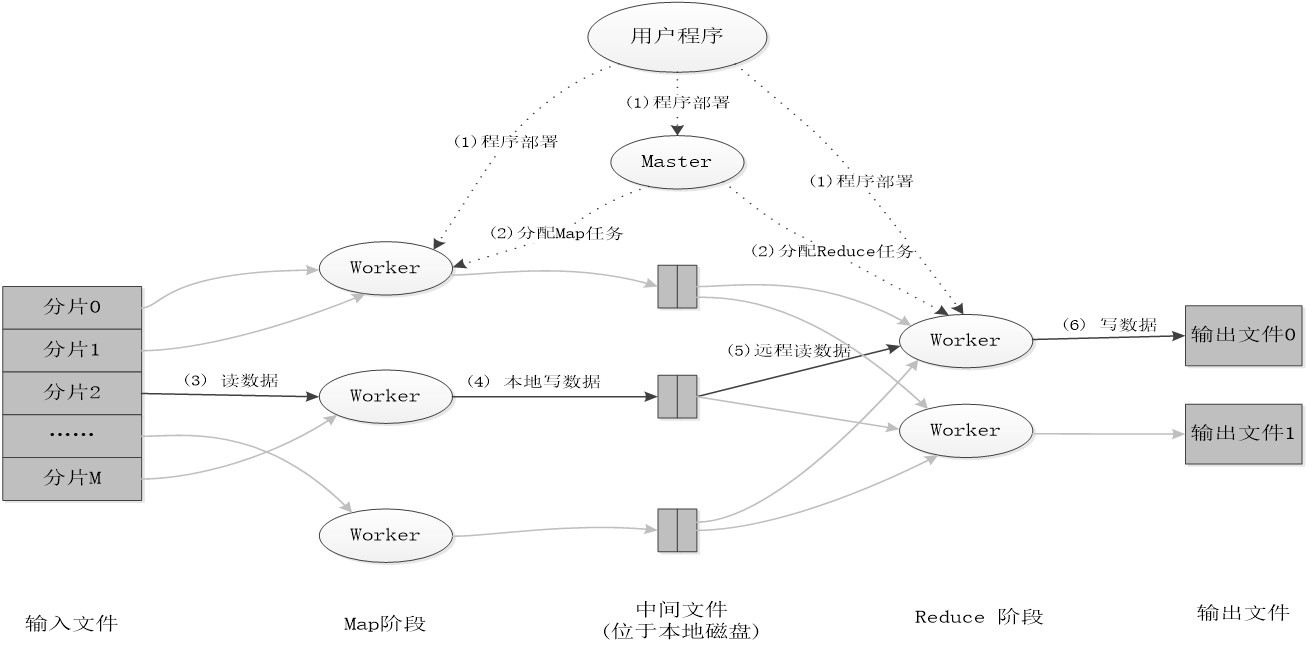
MapReduce应用执行过程
3. MapReduce实例
3.1 程序执行任务
输入:两个维度的数据(字符串和数字)。
输出:相同字符串的数据进行求和。
示例如下:
| 处理前 | 处理后 |
|---|---|
| a 10 | a 15 |
| b 20 | b 40 |
| c 30 | c 30 |
| a 5 | d 19 |
| b 20 | e 60 |
| d 9 | |
| e 60 | |
| d 10 |
(其中分割符为tab)
3.2 操作过程
① 首先启动CentOS和hadoop相关服务。
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver ② 启动eclipse
新建MapReduce项目。(hadoop2.0下)扩展阅读:使用Eclipse编译MapReduce

命名项目为Study。
新建包:com.jdb.mapreduce
新建类:MRClass.java
编写代码如下:
package com.jdb.mapreduce;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MRClass {
public static class ClassMap extends
Mapper<Object, Text, Text, IntWritable> {
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] line = value.toString().split("\t");
if (line.length == 2) {
context.write(new Text(line[0]),
new IntWritable(Integer.parseInt(line[1])));
}
}
}
public static class ClassReduce extends
Reducer<Text, IntWritable, Text, Text> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int i = 0;
for (IntWritable v : values) {
i += v.get();
}
context.write(key, new Text(String.valueOf(i)));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// args0 : dst
// args1 : out
// args2 : split MB
// args3 : reduce num
String dst = args[0];
String out = args[1];
int splitMB = Integer.valueOf(args[2]);
int reduceNum = Integer.valueOf(args[3]);
Configuration conf = new Configuration();
conf.set("mapreducs.input.fileinputformat.split.maxsize",
String.valueOf(splitMB * 1024 * 1024));
conf.set("mapred.in.split.size", String.valueOf(splitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node",
String.valueOf(splitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minseize.per.rack",
String.valueOf(splitMB * 1024 * 1024));
Job job = new Job(conf);
Path outputPath = new Path(out);
outputPath.getFileSystem(conf).delete(outputPath, true);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
job.setMapperClass(ClassMap.class);
job.setReducerClass(ClassReduce.class);
job.setNumReduceTasks(reduceNum);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setJarByClass(MRClass.class);
job.waitForCompletion(true);
}
}③ 运行代码
第一种方法是直接在Eclipse种运行:
cd $HADOOP_HOME
cp etc/hadoop/core-site.xml ~/workspace/study/src
cp etc/hadoop/hdfs-site.xml ~/workspace/study/src
# 以上两个不复制,运行会显示/input目录不存在,因为本地程序读取本地目录而不是HDFS
cp etc/hadoop/log4j.properties ~/workspace/study/src
# 用于记录程序的输出日记,否则只显示报错信息# 编造输入文件并上传到HDFS
cd ~
vim mr1
hdfs dfs -put mr1 /input
rm mr1右键点击包选择Run As -> Run Configurations…
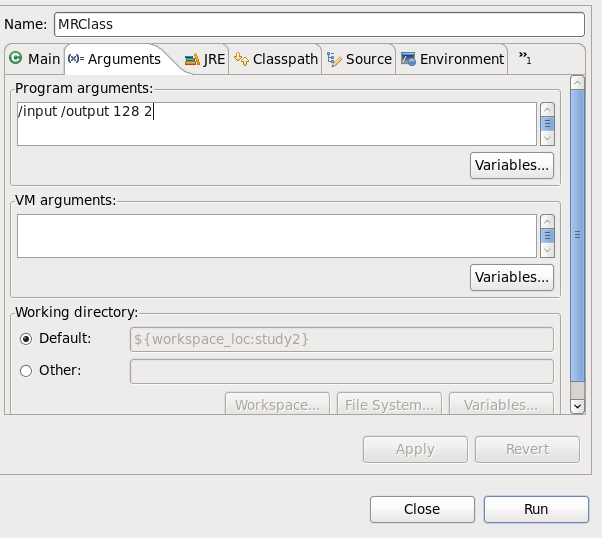
之后点击下方的Run按钮即可运行。
值得一提的是,这样显示的local运行,即本地运行。复制YARN配置文件到目录下运行反而会报错。原因暂时不明。
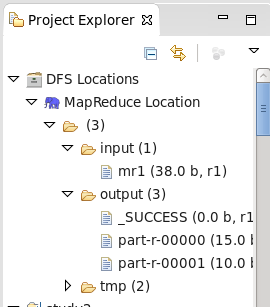
之后在项目目录下的DFS Locations中可以查看运行结果。如下图:
第二种方法使用打包到Hadoop中运行。
编写好程序之后,右键项目名选择Export。选择导出类型:JAR File。
设置导出路径和导出名称(本次设置为桌面和)。值得一提的是,在这里可以选择Main Class,后面运行时就会变得简单。如下图:

cd ~/Desktop
# 选择主类
hadoop jar test.jar /input /output 512 2
# 不选择主类
hadoop jar com.jdb.mapreduce.MRclass test.jar /input /output 512 2这样运行之后,就是在伪分布式下运行,可以通过访问http://localhost:8088查看任务运行状态。

运行完成之后,点击下图中的History查看运行信息。(如果运行错误,可在这里查看错误信息)

同样。也可以使用以下命令查看HDFS输出文件。
hdfs dfs -ls /output
hdfs dfs -cat /output/part-r-00000
hdfs dfs -cat /output/part-r-000001以上代码未使用Combiner,使用Combiner的好处在与数据量大时候,运行效率会更高。这里就不再赘述。















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









