







本节介绍HBase1.2.3下的批量导入数据BulkLoad
如果我们一次性入库hbase巨量数据,处理速度慢并且占用Region资源, 一个比较高效便捷的方法就是使用 “Bulk Loading”方法,即hbase提供的HFileOutputFormat类。
它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接生成这种hdfs内存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
1. 课前准备
1.1 BulkLoad原理介绍
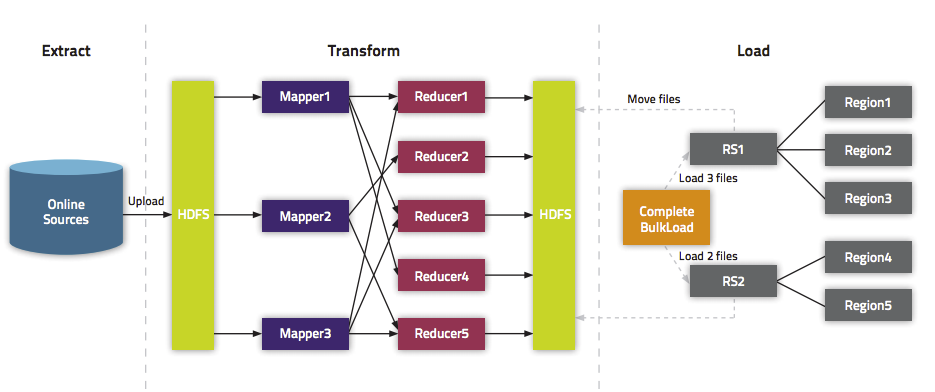
① 根据HDFS上的数据或者外部的数据生成Hbase的底层Hfile数据。
② 根据生成的目标Hfile,利用Hbase提供的BulkLoad工具将Hfile Load到Hbase目录下面。
根据HBase官网的介绍,流程图如下:
1.2 启动相应的服务
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
zkServer.sh start
start-hbase.sh1.3 实例介绍
本节仍旧以学生成绩表studentScore为例。其中rowkey为name,failmycolumn为grade。
| name | grade |
|---|---|
| zhao | A |
| qian | B |
| sun | C |
| li | A- |
| zhou | B+ |
| wu | D- |
| wang | D+ |
| feng | A+ |
| ceng | B- |
| jiang | C+ |
① 以上两列数据以TAB(\t)间隔,存储在HDFS的/input/目录下。
命令如下:
vim blukloadExample
hdfs dfs -put blukloadExample /input/② 创建hbase表
create 'studentScore', 'grade'2. 代码讲解
2.1 Map类介绍
public static class BulkMap extends Mapper<Object, Text, ImmutableBytesWritable, Put> {
public final static String SP = "\t";
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] values = value.toString().split(SP);
if (values.length == 2) {
byte[] rowkey = Bytes.toBytes(values[0]);
byte[] c_v = Bytes.toBytes(values[1]);
byte[] family = Bytes.toBytes("grade");
byte[] cloumn = Bytes.toBytes("");
ImmutableBytesWritable rowkeyWritable = new ImmutableBytesWritable(rowkey);
Put put = new Put(rowkey);
put.addColumn(family, cloumn, c_v);
context.write(rowkeyWritable, put);
}
}
}2.2 Main函数功能
主要功能就是接收参数,运行job。
if (arsgs.length != 4) {
System.exit(0);
}
// 输入路径或文件
String dst = args[0];
// 输出路径
String out = args[1];
int SplitMB = Intger.valueOf(args[2]);
//表名
String table_name = args[3];
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(SplitMB * 1024*1024));
conf.set("mapred.min.split.size", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(SplitMB * 1024 * 1024));
Job job = new Job(conf, "BulkLoad");
job.setJarByClass(BulkloadMR.class);
job.setMapperClass(BulkMap.class);
job.setReducerClass(PutSortReducer.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
Configuration hbaseconf = HBaseConfiguration.create();
HTable table = new HTable(hbaseconf, table_name);
HFileOutputFormat2.configureIncrementalLoad(job, table);
job.waitForCompletion(true);
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(hbaseconf);
loader.doBulkLoad(new Path(out), table);2.3 完整JAVA代码
package edu.hbase.study4;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.mapreduce.PutSortReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class BulkloadMR {
public static class BulkMap extends
Mapper<Object, Text, ImmutableBytesWritable, Put> {
public final static String SP = "\t";
@Override
protected void map(
Object key,
Text value,
Mapper<Object, Text, ImmutableBytesWritable, Put>.Context context)
throws IOException, InterruptedException {
String[] values = value.toString().split(SP);
if (values.length == 2) {
byte[] rowkey = Bytes.toBytes(values[0]);
byte[] c_v = Bytes.toBytes(values[1]);
byte[] family = Bytes.toBytes("grade");
byte[] cloumn = Bytes.toBytes("");
ImmutableBytesWritable rowkeyWritable = new ImmutableBytesWritable(
rowkey);
Put put = new Put(rowkey);
put.addColumn(family, cloumn, c_v);
context.write(rowkeyWritable, put);
}
}
}
public static void main(String[] args) throws Exception {
// args0 dst
// args1 out
// args2 split MB
// args3 hbase table name
if (args.length != 4) {
System.exit(0);
}
String dst = args[0];
String out = args[1];
int SplitMB = Integer.valueOf(args[2]);
String table_name = args[3];
Configuration conf = new Configuration();
conf.set("mapreduce.input.fileinputformat.split.maxsize",
String.valueOf(SplitMB * 1024*1024));
conf.set("mapred.min.split.size", String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.node",
String.valueOf(SplitMB * 1024 * 1024));
conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack",
String.valueOf(SplitMB * 1024 * 1024));
Job job = new Job(conf, "BulkLoad");
job.setJarByClass(BulkloadMR.class);
job.setMapperClass(BulkMap.class);
job.setReducerClass(PutSortReducer.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(out));
Configuration hbaseconf = HBaseConfiguration.create();
HTable table = new HTable(hbaseconf, table_name);
HFileOutputFormat2.configureIncrementalLoad(job, table);
job.waitForCompletion(true);
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(hbaseconf);
loader.doBulkLoad(new Path(out), table);
}
}
3. 运行代码并查看结果
① 设置环境变量
之前安装HBase时候没有设置环境变量。所以这里设置一下
vim ~/.bashrc
# 在最后增加两行
source ~/.bashrcexport HBASE_HOME=/usr/local/hbase-1.2.3
export PATH=$PATH:$HBASE_HOME/bin② 将JAVA项目打包
这里命名为test4.jar.
③ 运行jar包
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` hadoop jar test4.jar edu.hbase.study4.BulkloadMR /input/blukloadExample /outputExample 64 studentScore结果如下图:
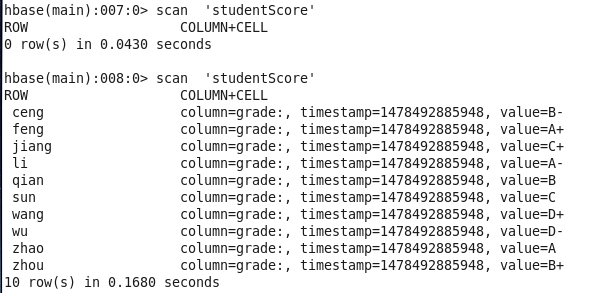
当然,也可以访问http://localhost:8088查看任务运行情况。
4.总结
本节介绍了如何批量导入HBase的方法。但是还有一部分内容不太清楚,需要进一步的学习。
参考内容:
HBase 官方文档
网易微专业大数据工程师















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









