






使用docker构建spark运行环境
安装docker与docker-compose
可参考
https://blog.csdn.net/Dragon_qing/article/details/124416383
系统构架图:
![[(./images/spark-env.png)]](https://i-blog.csdnimg.cn/blog_migrate/63ababdb7c3cda8e59264e66ecb83384.png)
使用docker hub查找我们需要的镜像。
docker compose部署文件:
version: '3.8'
services:
spark-master:
image: bde2020/spark-master:3.2.0-hadoop3.2
container_name: spark-master
ports:
- "8080:8080"
- "7077:7077"
volumes:
- ~/spark:/data
environment:
- INIT_DAEMON_STEP=setup_spark
spark-worker-1:
image: bde2020/spark-worker:3.2.0-hadoop3.2
container_name: spark-worker-1
depends_on:
- spark-master
ports:
- "8081:8081"
volumes:
- ~/spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
spark-worker-2:
image: bde2020/spark-worker:3.2.0-hadoop3.2
container_name: spark-worker-2
depends_on:
- spark-master
ports:
- "8082:8081"
volumes:
- ~spark:/data
environment:
- "SPARK_MASTER=spark://spark-master:7077"
使用yml部署文件部署spark环境
推荐配置好docker的国内镜像源,pull的速度会更快
参考:https://blog.csdn.net/whatday/article/details/86770609
在spark.yml文件所在的目录下,执行命令:
sudo docker-compose -f spark.yml up -d
查看容器创建与运行状态
sudo docker ps
对输出进行格式化
sudo docker ps --format '{{.ID}} {{.Names}}'
使用浏览器查看master的web ui界面
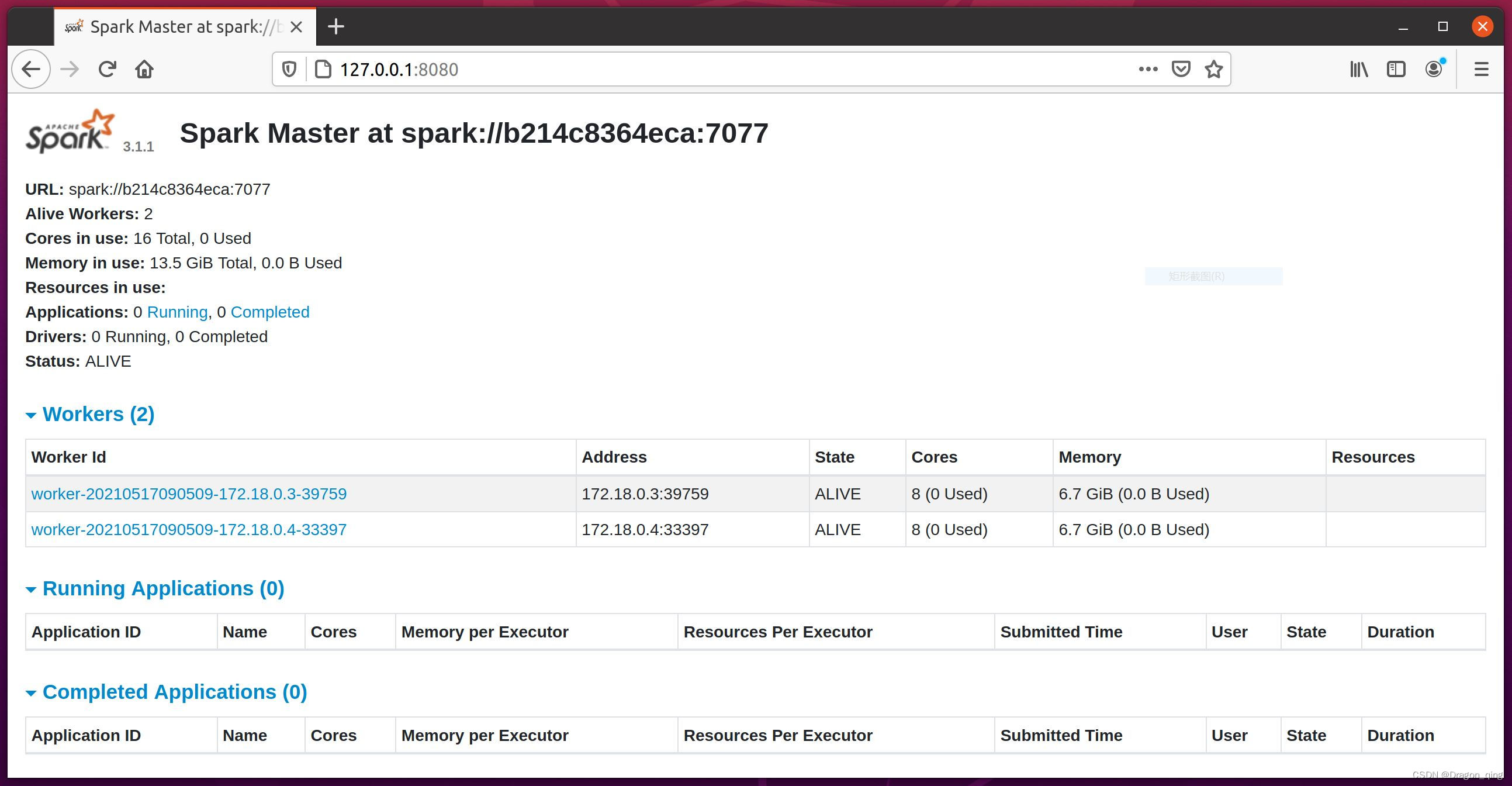
进入spark-master容器
sudo docker exec -it <master容器的id,仅需输入一部分即刻> /bin/bash
查询spark环境,安装在/spark下面。
ls /spark/bin
进入spark-shell
/spark/bin/spark-shell --master spark://spark-master:7077 --total-executor-cores 8 --executor-memory 2560m
进入浏览器查看spark-shell的状态

测试:创建RDD与filter处理
创建一个RDD
val rdd=sc.parallelize(Array(1,2,3,4,5,6,7,8))
打印rdd内容
rdd.collect()
查询分区数
rdd.partitions.size
选出大于5的数值
val rddFilter=rdd.filter(_ > 5)
打印rddFilter内容
rddFilter.collect()
退出spark-shell
:quit

















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









