






Neural Graph Collaborative Filtering
INTRODUCTION
可学习CF模型有两个关键组成部分:
1.embedding 嵌入:它将用户和项目转换为矢量化表示
2.interaction modeling 交互建模:它基于嵌入重建历史交互
矩阵分解(MF)直接将用户/项目ID嵌入为一个向量,并用内积对用户-项目交互进行建模[20];协同深度学习通过整合从项目丰富的边信息中学习到的深度表示,扩展了MF嵌入功能[30];神经协同过滤模型用非线性神经网络代替内积的MF交互作用函数[14];而基于翻译的CF模型使用欧几里德距离度量作为交互作用函数[28],等等。
但是这些方法不足以为CF产生令人满意的嵌入。关键原因是嵌入功能缺乏对关键协作信号的明确编码,这种编码隐藏在用户-项目交互中,以揭示用户(或项目)之间的行为相似性。更具体地说,大多数现有方法仅使用描述性特征(例如,标识和属性)构建嵌入函数,而不考虑用户-项目交互——这仅用于定义模型训练的目标函数。因此,当嵌入不足以捕获CF时,这些方法必须依赖交互函数来弥补次优嵌入的不足。
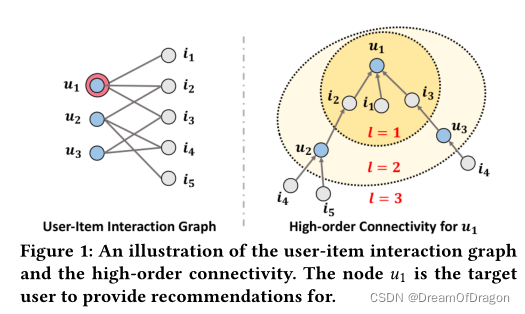
以图一为例解释一下高阶连通性。给U1推荐项目,图一左边为用户项目交互图,右边为根据U1展开的树结构。高阶连通性指的是到U1长度大于1的节点路径(节点包括项目和用户两种)。这种高阶连接包含了丰富的语义,承载着协同信号。例如,路径u1←i2←u2表示u1和u2之间的行为相似性,因为两个用户都与i2交互过;较长的路径u1←i2←u2←i4表明u1很可能会采用i4,因为她相似的用户u2之前已经消费过i4。此外,从l= 3的整体来看,项目i4比项目i5更可能引起u1的兴趣,因为i4有两条路径连接,而i5只有一条路径连接。
作者在嵌入函数中建模高阶连接信息,设计了一种神经网络方法来递归地在图中传播嵌入,而不是将交互图扩展成一棵实现起来很复杂的树。具体来说,我们设计了一个分层传播层,它通过聚合交互项目(或用户)的嵌入来细化用户(或项目)的嵌入。通过堆叠多个嵌入传播层,我们可以强制嵌入以捕获高阶连接中的协作信号。【聚合项目信息来细化用户嵌入,聚合用户信息细化项目嵌入】。通过堆叠多个嵌入传播层,我们可以强制嵌入以捕获高阶连接中的协作信号。以图1为例,堆叠两层捕捉u1←i2←u2的行为相似性,堆叠三层捕捉u1←i2←u2←i4的潜在推荐,信息流的强度(由层间的可训练权重估计)决定i4和i5的推荐优先级。
主要贡献如下:
- 我们强调了在基于模型的CF方法的嵌入功能中明确利用协作信号的至关重要性。
- 我们提出了一种新的基于图神经网络的推荐框架NGCF,它通过执行嵌入传播以高阶连接的形式显式编码协作信号
- 我们在300万个数据集上进行了实证研究。大量的结果证明了NGCF的先进的性能和它在提高神经嵌入传播嵌入质量的有效性
METHODOLOGY
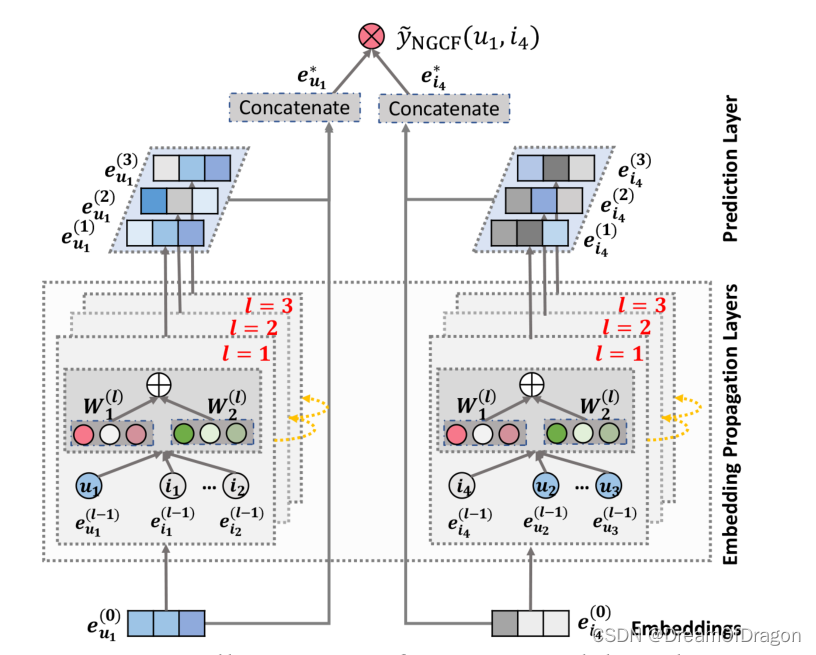
图2:NGCF模型架构的图示(箭头线表示信息流)。用户u1(左)和项目i4(右)的表示通过多个嵌入传播层来细化,这些层的输出被连接以进行最终预测。
框架组成:
(1)嵌入层,提供用户嵌入和项目嵌入的初始化;
(2)多个嵌入传播层,通过注入高阶连接关系来细化嵌入;
(3)预测层,其聚集来自不同传播层的细化嵌入,并输出用户-项目对的相似性分数。
嵌入层
用嵌入向量eu∈Rd(ei∈Rd)来描述用户u(一个项目I),其中d表示嵌入大小。这可以看作是将参数矩阵构建为嵌入查找表:
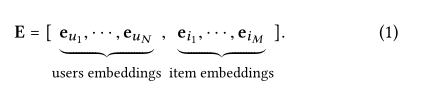
嵌入表作为用户嵌入和项目嵌入的初始状态,以端到端的方式进行优化。
在像MF和神经协同过滤[14]这样的传统推荐器模型中,这些ID直接送到交互层中获得预测分数。NGCF框架中,我们通过在用户-项目交互图上传播来细化嵌入。这导致更有效的推荐嵌入,因为嵌入细化步骤明确地将协作信号注入到嵌入中。这就是下边的嵌入传播层。
嵌入传播层
将嵌入传播层
建立在GNNs的消息传递架构上,以便沿着图结构捕获CF信号,并细化用户和项目的嵌入。
一层嵌入传播层:
交互项目提供了用户偏好的直接证据;类似地,消费项目的用户可以被视为项目的特征,并用于测量两个项目的协作相似性。在此基础上执行连接的用户和项目之间的嵌入传播,用两个主要操作来制定流程:消息构造和消息聚合
消息构造:对于连接的用户-项目对(u,i),我们将从i到u的消息定义为: mu<-i=f(ei,u i,pui)
其中u←i是消息嵌入(即,要传播的信息)。f()是消息编码函数,它将嵌入ei和u i作为输入,并使用系数pui来控制边缘(u,I)上每次传播的衰减因子。因此f()为:
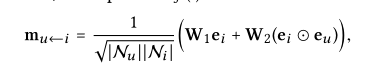
其中的W1,W2∈R d′×d是提取有用信息进行传播的可训练权重矩阵,d′是变换大小。与仅考虑ei贡献的传统图形卷积网络不同,这里我们另外将ei和eu之间的相互作用编码到通过ei⊙eu传递的消息中,其中⊙表示元素积。这使得消息依赖于ei和eu之间的相似性,例如,传递来自相似项目的更多消息。这不仅增加了模型表示能力,还提高了推荐性能。
和图卷积神经网络一样,把pui设置为图拉普拉斯范数,其中Nu和Ni表示用户u和项目i的第一跳邻居。从表征学习的角度来看,pui反映了历史项目对用户偏好的贡献程度。从消息传递的角度来看,pui可以被解释为一个折扣因子,因为被传播的消息应该随着路径长度而衰减
消息聚合:
在这个阶段,我们聚集从u的邻居传播的消息来细化u的表现。聚合函数:
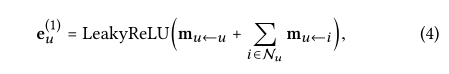
eu(1)表示在第一个嵌入传播层之后获得的用户u的表示。LeakyReLU 的激活功能允许消息编码正和小的负信号。除了u的邻居给u传播的消息之外,还考虑了用户本身的自连接:mu←u=W1*eu。其中w1和消息构造中的w1是一样的(W1是与等式(3)中使用的权重矩阵共享的权重矩阵)。同理,通过传播来自其关联用户的信息来可得ei(1)。总而言之,嵌入传播层的优势在于显式地利用一阶连通性信息来关联用户和项目表示。
高阶传播
堆叠更多的嵌入传播层来探索高阶连通性信息。这种高阶关联性对于编码协作信号以估计用户和项目之间的相关性分数至关重要。通过堆叠L个嵌入传播层,用户(和项目)能够接收从其L-hop邻居传播的消息。如图2所示,在第L步中,用户u的表示被递归地公式化为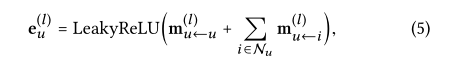
其中被传播的消息定义如下:
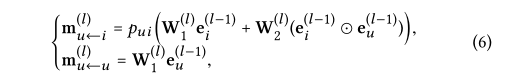
其中W(l)1,W(l)2,∈Rdl×dl1为可训练变换矩阵,dl为变换大小;e(l-1)i是从前面的消息传递步骤中生成的项目表示,存储来自其(L-1)跳邻居的消息。它进一步有助于用户u在L层的表示。类似地,我们可以获得项目i在L层的表示。堆叠多个嵌入传播层无缝地将协作信号注入表示学习过程。
矩阵形式的传播规则
为了提供嵌入传播的整体视图并便于批量实现,我们提供了分层传播规则的矩阵形式(相当于等式(5)和(6))
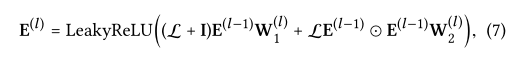
E(l)是经过l步嵌入传播后得到的用户和项目的表示。一开始传播的为E(0) 即e(0)u =eu,E(0)i= ei。I表示单位矩阵。L表示图拉普拉斯矩阵。
图拉普拉斯矩阵公式为: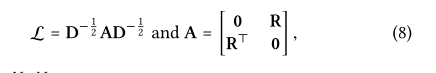
其中R为用户-项目交互矩阵。0为全零矩阵,A为邻接矩阵,D为对角度矩阵,其中第t个对角矩阵Dtt=|Nt|,因此,非零非对角线条目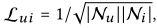
它等于等式(3)中使用的pui。矩阵形式的传播规则可以以一种相当有效的方式同时更新所有用户和项目的表示,它使我们可以抛弃使图卷积网络在大规模图上运行的通常使用的节点抽样过程。
模型预测
用L层传播后,我们得到了用户u的多个表示,即{e(1)u,、e(L)u}。由于在不同层获得的表示强调通过不同连接传递的消息,因此它们在反映用户偏好方面有不同的贡献。因此,我们将它们连接起来,构成用户的最终嵌入;我们对项目进行同样的操作,将不同层学习到的项目表示{e(1) i,e(L) i}串联起来,得到最终的项目嵌入:
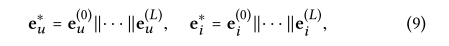
||是串联运算。这样做不仅用嵌入传播层丰富了初始嵌入,还允许通过调整L来控制传播范围。
注意,除了串联之外,还可以应用其他聚合器,例如加权平均、最大池、LSTM等。,这意味着在组合不同顺序的关联性时有不同的假设。
使用串联的优势在于它的简单性,因为它不需要学习额外的参数,并且它已经在最近的图形神经网络的工作中被非常有效地显示出来,该工作涉及layer-aggregation层聚集机制。
最后通过内积来估计用户对目标物品的偏好
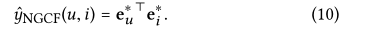
在这项工作中,我们强调嵌入函数学习,因此只使用内积的简单交互函数。其他更复杂的选择,如基于神经网络的交互功能,将在未来的工作中探索。
Optimization最优化
为了学习模型参数,我们优化了成对的BPR损失,这在推荐系统中得到了广泛的应用。它考虑了观察到的和未观察到的用户项目交互之间的相对顺序。具体来说,业务流程重组假设观察到的更能反映用户偏好的交互应该被赋予比未观察到的更高的预测值。
目标函数如下:
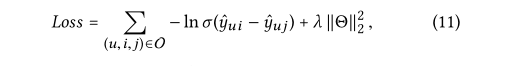
其中O={(u,I,j)|(u,i)∈ R+,(u,j)∈R- }表示成对训练数据,R+表示观察到的相互作用,R-为未观察到的相互作用;
σ()是sigmoid函数
θ= { E,{W(l) 1,W(l) 2}L l=1}表示所有可训练的模型参数,λ控制L2正则化强度以防止过拟合。
采用小批量Adam 来优化预测模型和更新模型参数。特别地,对于一批随机采样的三元组(u,I,j)∈ O,我们在L步传播后建立它们的表示[e(0),,e(L)],然后利用损失函数的梯度更新模型参数。
模型尺寸
在每个传播层都会获得一个嵌入矩阵,只引入了少量参数,两个尺寸为dldl-1的权重矩阵w1和w2。这些嵌入矩阵是从嵌入查找表E(0)中导出的,转换基于用户项目图结构和权重矩阵。因此,与最简洁的嵌入式推荐模型MF相比,我们的NGCF只多使用了2L**dldl-1个参数,又因为L一般小于5,即嵌入传播层数较少,因此dl通常被设置为嵌入的大小,相比于用户和项目数目来说小得多,所以模型参数上的额外成本可以忽略不计。
例如,在我们实验的Gowalla数据集(20K个用户和40K个项目)上,当嵌入大小为64并且我们使用大小为64×64的3个传播层时,MF有450万个参数,而我们的NGCF只使用了0.024万个附加参数。总而言之,NGCF使用非常少的附加模型参数来实现高阶连通性建模。
消息和节点丢失
尽管深度学习模型具有很强的表示能力,但它们通常存在过度拟合的问题。为了解决这种问题,dropout是一种有效的解决办法。以防止神经网络过拟合。
NGCF采用两种丢弃技术:消息丢弃和节点丢弃。
消息丢弃:具体来说,我们以概率p1丢弃等式(6)中传播的消息。因此,在第l传播层中,只有部分消息有助于细化表示。
节点丢弃:随机阻塞一个特定的节点并丢弃它所有的输出消息。对于第l传播层,我们随机丢弃拉普拉斯矩阵的(M+N)个p2节点,其中p2是丢弃率。
注意:dropout只适用于训练,在测试期间不可使用。
作用:消息丢失使表示在用户和项目之间存在或不存在单个连接时更加稳健,节点丢失侧重于减少特定用户或项目的影响。
SVD++可以看作是没有高阶传播层的NGCF的特例。
将L设置为1。在传播层,我们禁用变换矩阵和非线性激活函数。此后,e(1)u和e(1)i分别被视为用户u和项目I的最终表示。我们将这个简化模型称为NGCF-SVD,它可以表述为:
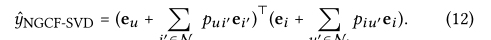
显然,通过将pui’和pu’I分别设置为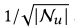
和0,我们可以准确地恢复SVD++模型。此外,另一个广泛使用的基于项目的CF模型FISM 也可以被视为NGCF的特例,其中等式(12)中的piu’被设置为0。
时间复杂性分析
主要操作为分层传播规则。对于第l传播层,矩阵乘法的计算复杂度为O(|R+| dldl-1),其中| R+|表示拉普拉斯矩阵中非零整数的个数,Dl和Dl-1是当前和以前的转换大小。
对于预测层,只涉及内积,对于内积,整个训练epoch的时间复杂度为
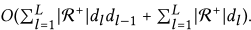
因此,评估NGCF的总体复杂性为
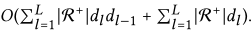
经验上,在相同的实验设置下(如第4节所述),MF和NGCF在Gowalla数据集上的训练成本分别约为20和80个周期;在推断过程中,对于所有测试实例,MF和NGCF的时间成本分别为80和260秒。
实验
Dataset Description
为了评估NGCF的有效性,我们在三个基准数据集上进行了实验:Gowalla、yelp 2018 * 2和Amazon-book,这些数据集是公共可访问的,并且在域、大小和稀疏性方面各不相同。我们在表1中总结了三个数据集的统计数据。
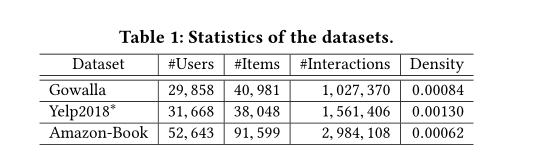
Gowalla:这是从Gowalla获得的签到数据集[21],用户通过签到共享他们的位置。为了确保数据集的质量,我们使用10核心设置[10],即保留至少有十次交互的用户和项目。
Yelp2018:该数据集采用了Yelp挑战赛2018版的数据。其中,像餐馆和酒吧这样的地方企业被视为项目。为了确保数据质量,我们使用相同的10核设置。
Amazon-book: Amazon-review是一个广泛用于产品推荐的数据集[9]。我们从收藏品中挑选亚马逊书籍。同样,我们使用十核设置来确保每个用户和项目至少有十次交互。
对于每个数据集,我们随机选择每个用户80%的历史交互构成训练集,剩余的作为测试集。从训练集中,我们随机选择10%的交互作为验证集来调整超参数。对于每个观察到的用户-项目交互,我们将其视为一个正实例,然后进行负采样策略,将其与用户以前没有消费过的一个负项目配对。
Experimental Settings
Evaluation Metrics
对于测试集中的每个用户,我们将用户没有交互过的所有项目视为阴性项目。然后除了训练集中使用的正项,每种方法输出用户对所有项目的偏好分数。为了评估top-K推荐和偏好排序的有效性,我们采用了两个广泛使用的评估协议[14,40]: recall@K和ndcg@K3。默认情况下,我们设置K= 20。我们报告测试集中所有用户的平均指标。
基线
为了证明有效性,我们将建议的NGCF与以下方法进行比较:
MF:这是利用贝叶斯个性化排序(BPR)损失优化的矩阵分解,它只利用用户-物品直接交互作为交互函数的目标值。
NeuMF:该方法是一种先进的神经CF模型,它在用户和项目嵌入的元素之上使用多个隐藏层来捕获它们的非线性特征交互。特别是,我们采用了两层的简单架构,其中每个隐藏层的维度保持不变。
CMN[5]: 这是一种最先进的基于内存的模型,其中用户表示通过内存层细心地结合相邻用户的内存插槽。请注意,一阶连接用于查找与相同项目交互的类似用户。
HOP-Rec:这是一个最先进的基于图的模型,其中从随机行走中得到的高阶邻居被利用来丰富用户-项目交互数据。
PinSage:PinSage被设计成在项目-项目图中使用GraphSAGE [8]。在这项工作中,我们将其应用于用户-项目交互图。特别地,我们采用了[42]中建议的两个图形卷积层,并且隐藏维度被设置为等于嵌入大小。
GC-MC:该模型采用GCN [18]编码器为用户和项目生成表示,其中只考虑一阶邻居。因此,如[29]中所建议的,使用一个图形卷积层,其中隐藏维度被设置为嵌入大小。
我们还尝试了spectralrCF[43],但发现特征分解会导致很高的时间成本和资源成本,尤其是当用户和项目数量很大时。因此,尽管它在小数据集上取得了令人满意的性能,但我们没有选择它进行比较。为了公平比较,所有方法都优化了BPR loss,如等式(11)所示。
早期停止策略,即,如果验证数据上的回忆@20在50个连续时期内没有增加,则提前停止。为了模拟以第三连通性编码的CF信号,我们将NGCF L的深度设置为3。在没有说明的情况下,我们显示了三个嵌入传播层的结果,节点丢失率为0.0,消息丢失率为0.1。
Performance Comparison
Overall Comparison
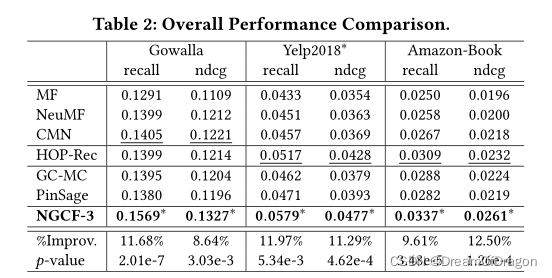
MF在三个数据集上表现不佳。这表明内部产品不足以捕捉用户和项目之间的复杂关系,进一步限制了性能。
NeuMF在所有情况下都始终优于MF,证明了用户和项目嵌入之间非线性特征交互的重要性。.
但是,,MF和NeuMF都没有对嵌入学习过程中的连通性进行显式建模,这很容易导致次优表示
与MF和NeuMF相比,GC-MC的性能验证了加入一阶邻居可以提高表征学习。然而,在Yelp2018中,GC-MC的表现不如NeuMF w.r.t. ndcg@20。原因可能是GC-MC没有充分探索用户和项目之间的非线性特征交互。
在大多数情况下,CMN通常比GC-MC具有更好的性能。这种改进可能归因于神经注意机制,它可以指定每个相邻用户的注意权重,而不是GC-MC中使用的相等或启发式权重
PinSage在Gowalla和AmazonBook中的表现略逊于CMN,而在Yelp2018中的表现则要好得多;同时,在大多数情况下,HOP-Rec通常会实现显著的改进。这是有意义的,因为PinSage在嵌入函数中引入了高阶连通性,HOP-Rec利用高阶邻居来丰富训练数据,而CMN只考虑相似的用户。因此,它指出了高阶连通性或邻居对建模的积极作用。
NGCF始终在所有数据集上产生最佳性能。通过堆叠多个嵌入传播层,NGCF能够以显式方式探索高阶连通性,而CMN和GC-MC仅利用一阶邻居来指导表示学习。这验证了在嵌入函数中捕获协作信号的重要性。此外,与PinSage相比,NGCF考虑多粒度表示来推断用户偏好,而PinSage仅使用最后一层的输出。这表明不同的传播层在表示中编码不同的信息。对HOP-Rec的改进表明嵌入函数中的显式编码CF可以获得更好的表示。我们进行单样本t检验,p-value< 0.05表明NGCF在最强基线(下划线)上的改善具有统计学意义。
相互作用稀疏度水平的性能比较
稀疏性问题通常会限制推荐系统的表达能力,因为不活跃用户的少量交互不足以生成高质量的表示。我们调查利用连接信息是否有助于缓解这个问题。
我们对不同稀疏度的用户组进行实验。特别是,基于每个用户的交互数量,我们将测试集分成四组,每组都有相同的总交互。
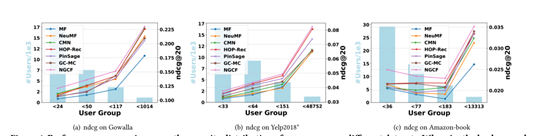
不同数据集上用户组稀疏性分布的性能比较。其中,背景直方图表示每个组中涉及的用户数量,线条表示w.r.t. ndcg@20的性能。
NGCF和HOP-Rec在所有用户组上的表现始终优于所有其他基准。它表明,利用高阶连通性极大地促进了非活跃用户的表示学习,因为协作信号可以被有效地捕获。因此,解决推荐系统中的稀疏性问题是有希望的。
嵌入传播有利于相对不活跃的用户。
Effect of Layer Numbers
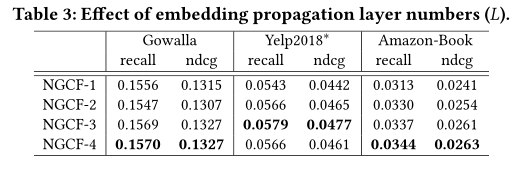
- 增加NGCF的深度会大大增加推荐案例。显然,NGCF-2和NGCF-3在所有方面都比NGCF-1取得了一致的进步,后者只考虑了一阶邻居。我们将这种改进归因于CF效应的有效建模:协同用户相似性和协同信号分别由二阶和三阶连接性承载。
- 当在NGCF-3的顶部进一步叠加传播层时,我们发现NGCF-4导致在yelp 2018 *数据集上过度拟合。这可能是由于应用过深的体系结构可能会给表示学习带来噪声。另外两个数据集上的边际改进验证了传导三个传播层足以捕获CF信号。
- 当改变传播层数时,NGCF在三个数据集上始终优于其他方法。它再次验证了NGCF的有效性,经验表明高阶连通性的显式建模可以极大地促进推荐任务。
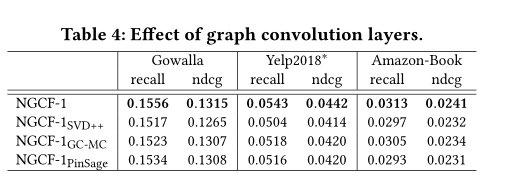
嵌入传播层和分层隔离机制的影响
设置了不同的NGCF-1的变体:
- 消息传递函数中移除了节点和邻居之间的表示交互,设置为PinSage和GC-MC的表示交互。目的是为了突出节点与邻居之间表示交互的作用,即eu⊙ei,这使得信息的传播依赖于ei和eu之间的亲和力。而且这两个变体的表现比原来的要好,说明了层聚集机制的重要性。
- 在SVD++之后,我们获得了一个基于等式(12)的变量,称为NGCF-1SVD++。在大多数情况下,NGCF-1SVD++的表现不如NGCF-1insagea和NGCF-1GC-MC。它说明了节点本身传递的消息和非线性转换的重要性
Effect of Dropout
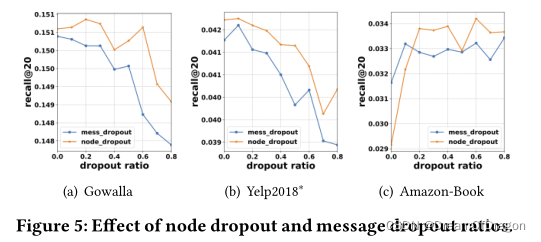
node dropout提供了更好的性能。一个原因可能是,丢弃来自特定用户和项目的所有传出消息使得表示不仅不受特定边缘的影响,而且不受节点的影响。因此,节点丢失比消息丢失更有效。意味着node dropout可以成为解决图神经网络过拟合的有效策略。
Test Performance w.r.t. Epoch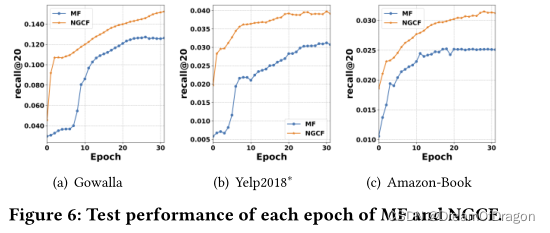
NGCF表现出比MF更快的收敛。这是合理的,因为当在小批量中优化交互对时,涉及间接连接的用户和项目。这样的观察证明了NGCF更好的模型容量和在嵌入空间中执行嵌入传播的有效性
Effect of High-order Connectivity
从Gowalla数据集中随机选择了六个用户,以及他们的相关项目。我们观察他们的表现如何影响NGCF的深度。
图7(a)和7(b)分别显示了从MF(即NGCF-0)和NGCF-3导出的表示的可视化。请注意,这些项目来自测试集,在培训阶段不会与用户配对。有两个关键观察结果:
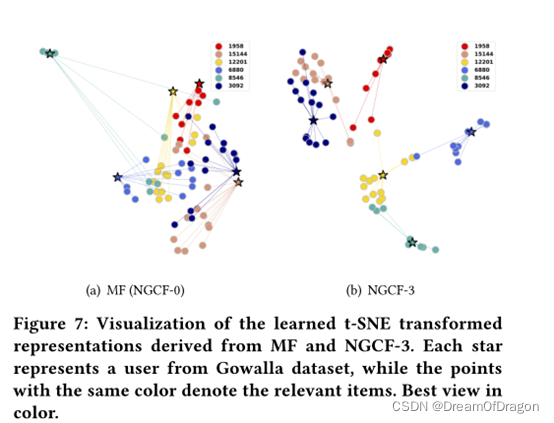
图7:从MF和NGCF-3导出的经验t-SNE变换表示的可视化。每个星星代表一个来自Gowalla数据集的用户,而具有相同颜色的点表示相关项目。彩色最佳视角。
- 用户和项目的关联性在嵌入空间中得到了很好的体现,即嵌入到空间的近部。特别地,NGCF-3的表示呈现可辨别的聚类,这意味着具有相同颜色的点(即,由相同用户消费的项目)倾向于形成聚类
- 在图7(a)和7(b)中联合分析相同的用户(例如12201和6880),我们发现,当堆叠三个嵌入传播层时,它们的历史项目的嵌入往往更接近。它定性地验证了所提出的嵌入传播层能够将显式协作信号(通过NGCF-3)注入到表示中
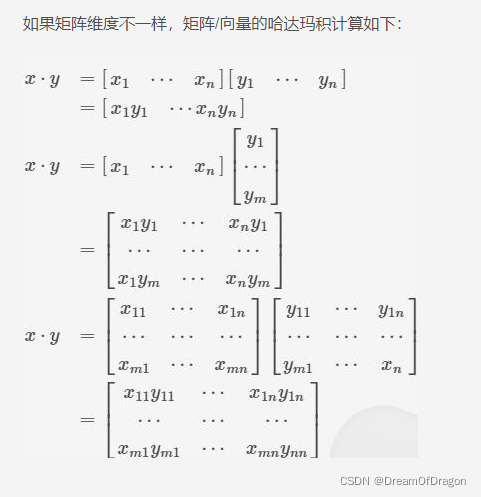
元素积
哈达玛积(Hadamard product) ,又名舒尔积或逐项积。
在机器学习中,哈达玛积还称为,元素积(element-wise product/point-wise product)。
输入: 两个相同形状的矩阵。
输出: 具有同样形状的、各个位置的元素等于两个输入矩阵相同位置元素的乘积的矩阵。

















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









