






UltraGCN: Ultra Simplification of Graph Convolutional Networks for Recommendation
三个缺点
本文首先指出了LightGCN的三个缺点:
- 消息传递期间在边缘上的分配的权重与直觉相反。
- 传播过程中未能区分不同类型关系对(用户项目,项目项目,用户用户)之间的重要性。此操作还可能i引入嘈杂和信息不足的关系。
- 过渡平滑问题限制了不饿能使用太多的消息层。
缺点一
LightGCN中的消息传递操作为:

那么内积操作就可以表示为:

其中α系数为:

其中的ik项和uv项:同样为项目-项目和用户-用户,但是i和k以及u和v的系数确实不一样的,这显然是很不公平的,至少从直觉上讲是不公平的。
缺点二
上述的消息传递公式未能捕捉到他们不同的重要性。
缺点三
堆叠更多的消息传递层应该可以捕捉更高阶的协作信号,但是实际上LightGCN在第二层或者第三层效率就开始下降,作者将其中一部分原因归结为消息传递的过度平滑问题。
改动
进行了一下几个改动:
改动一:用户-项目图上的学习
由于图卷积是拉普拉斯平滑的一种特殊形式,执行过多的消息传递层会让具有相同程度的节点具有完全相同的嵌入。
作者开始思考能否跳过无穷的消息传递,直接接近所达到的最终状态即收敛状态。
首先,最终的收敛条件为

即最后两层的表示是一样的,所以选择用eu和ei表示
所以缺点一第一个公式可改写为:

进一步简化后得到:

我们的目标是接近收敛状态,而不是执行显示的消息传递(这只是一种方法而已)。所以我们直接最小化等式9两边的差值。
作者的做法是将嵌入归一化为单位向量,然后最大化两项的点积(没看懂哈哈哈)。

相当于最大化u和i之间的余弦相似度。为了方便优化 假如了sigmoid激活和负对数似然:

但是这样还是可能遭受到过度平滑的问题,因为它要求所有的连接对都相似。这样用户和项目非常容易聚合到相同的嵌入中。所以为了缓解过度平滑问题,在训练期间执行负采样。:

又选择了一个主损失函数BCE。:

将两者结合起来组成用户项目图上学习的损失函数:

改动二 项目-项目图学习
首先构造了项目-项目图(之前都是直接隐性的学习项目项目之间的关系,现在直接显性的学习项目之间的关系。)

G为项目项目图,A为用户项目图的邻接矩阵。
由于项目项目图的邻接矩阵G的数据比较密集,直接引入优化会使得难以训练所以选最相似的k个项目s(i)进行训练

因为Lc和Lo中的负采样已经使UltraGCN能够抵消过平滑。有了这种约束损失,我们扩展UltraGCN以更好地学习项目-项目关系,并最终导出UltraGCN的以下训练目标
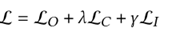
作者认为用户的兴趣比项目的种类多得多,所以没有改动用户-用户图。
系,并最终导出UltraGCN的以下训练目标
[外链图片转存中…(img-e5lFicgt-1646623501256)]
作者认为用户的兴趣比项目的种类多得多,所以没有改动用户-用户图。














 2108
2108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









