







今天通过一个简单的网易云音乐排行榜数据抓取与音乐下载实战案例,带着大家一起来学习如何抓取动态生成的页面内容。网易云音乐排行榜网址:https://music.163.com/#/discover/toplist,界面效果如下。
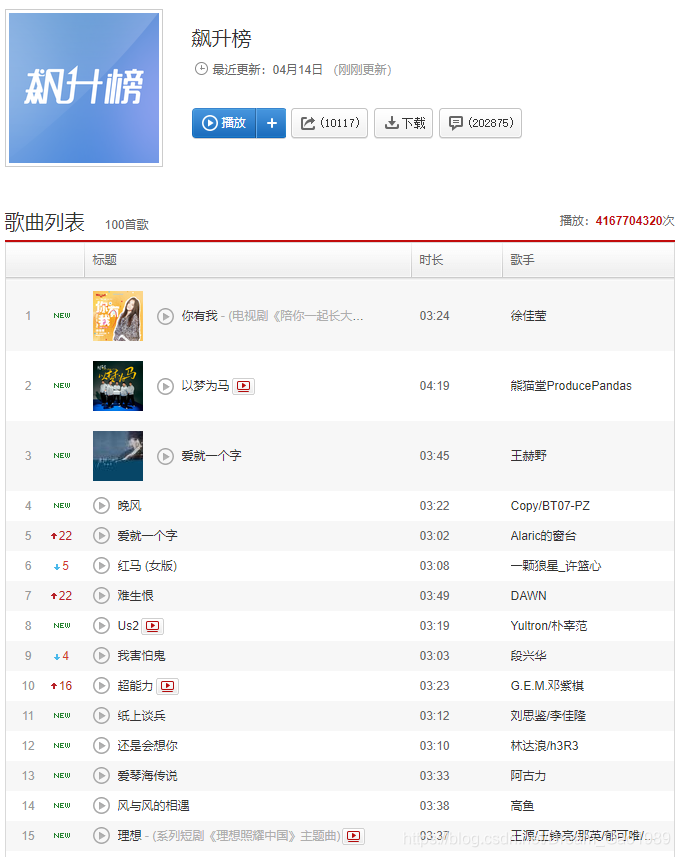
查看页面源代码,发现并没有这些歌曲信息,说明这些内容都是通过JavaScript动态生成的。使用普通的requests库无法直接获取相关内容,这里我们采用Selenium模拟人操作浏览器,从而获取动态生成的内容。(Selenium是一个用于Web应用程序测试的工具,Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,Python中Selenium库的安装与使用请参考另一篇博文:Selenium + Chrome 网络爬虫学习笔记)
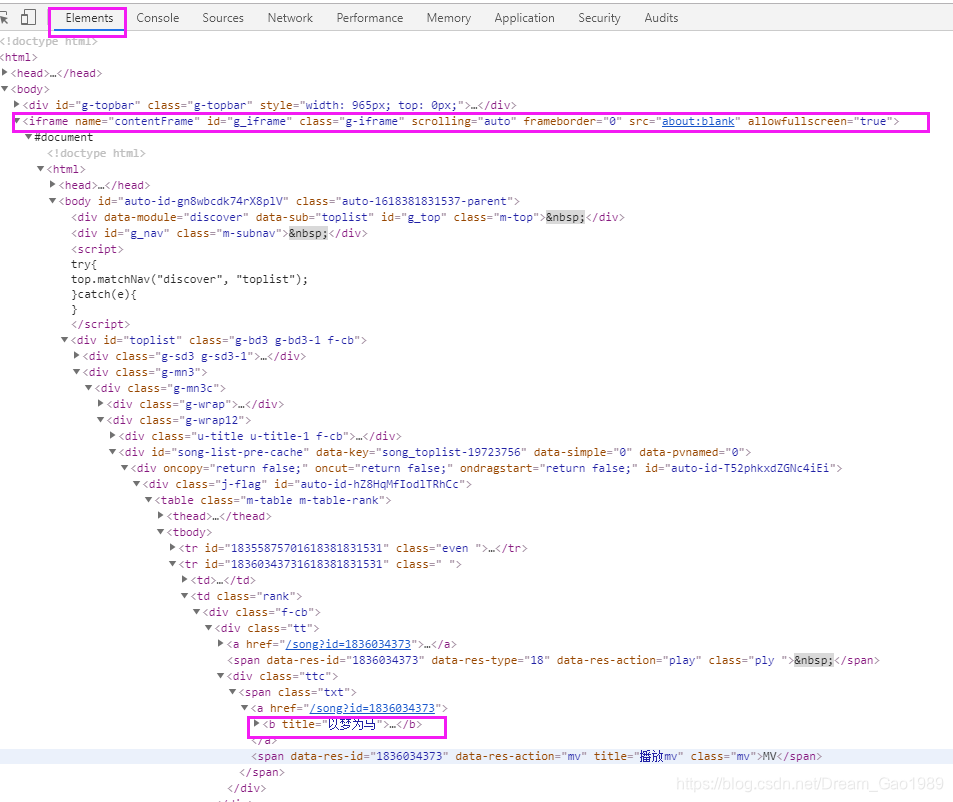
以第 2 首歌 以梦为马 为例,将鼠标放在文字上方,右键选择检查(不同浏览器叫法可能不一样)即可打开网页分析工具,如下图所示。可知网页中使用了框架,音乐排行榜内容所在框架的id为"g_iframe"。
抓取网易云音乐排行榜数据的关键代码如下:

这里的关键是要切换到指定的页面框架中去,即 browser.switch_to.frame("g_iframe"),否则无法获取相关内容。
运行后,控制台打印结果如下(部分内容截图):
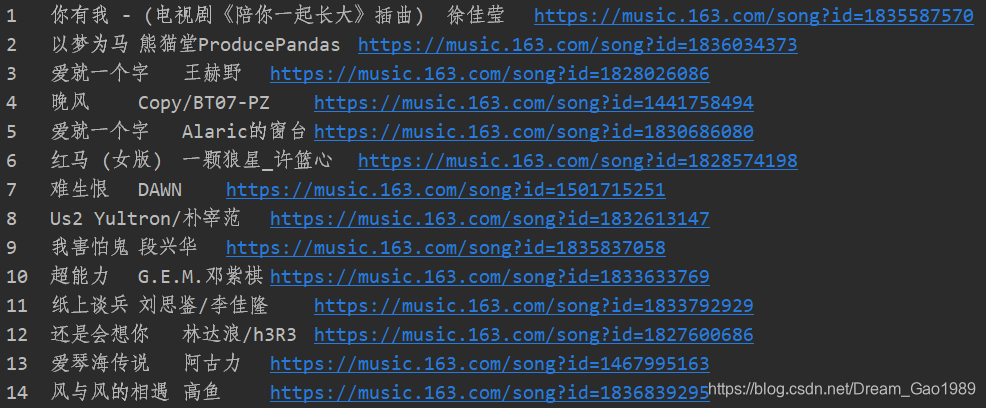
获取到音乐详情网址和音乐ID后,可以跳转页面进一步获取更多关于音乐的信息,例如作词、作曲、制片人、歌词、评论等,甚至可以直接下载音乐,主要流程都是类似的,不同的是页面解析的xpath有所不同,感兴趣的同学可以深入拓展,遇到问题可以在评论区交流。
相关代码可以关注微信公众号:Python资源分享,回复 网易 即可获取。




















 3215
3215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











