






前言
本文基于本人的专科毕业论文简化而写,主要讲述如何实现通过YOLOv7对水中鱼类进行目标检测的实现。文中所有数据为作者当时实验所得,读者复现项目的过程中可能会出现模型效果不一样的问题,这个暂时没有解决方法,机器学习目前为止本来就没有完全合理的数学解释,所以只能多训练几次调整参数,改善模型效果。本项目有参考过网上其他人的数据处理代码,如有雷同,请见谅。
摘要
由于海洋鱼类研究中对于鱼群的生活位置、行为具有较高的监测要求,所以通过深度学习实时监测到鱼类所在位置和种类,对鱼类养殖、海洋资源调查及鱼类行为的研究等具有重要的意义。本文研究如何通过深度学习的技术对水中鱼类进行准确率较高的目标识别。先通过收集水下鱼类图片,人工为不同鱼类打标签,对图片进行优化预处理,然后按8:1:1划分数据集为训练集、验证集和测试集。接着使用迁移学习的方法,调用经过大量图片训练的YOLOv7x预训练模型,冻结前10层,读取自定义的水下鱼类数据集进行训练,不断调整超参数以提升模型的准确率。最终得到了基于YOLOv7x对水中鱼类目标检测效果较优的模型,平均识别准确率达到90%。本文研究所得的模型,与以往关于水下目标检测模型的优势在针对鱼类,优化了检测目标的复杂性,提升了水中鱼类目标检测的准确率,比以往的水下目标检测模型准确率提高了10%。
项目需求
环境需求
1、YOLOv7官方预训练模型
2、Pycharm IDE
3、PyTorch 1.13.0及以上
4、CUDA 11.6及以上
5、LabelImg软件
6、水中鱼类数据集 公开数据集地址:https://github.com/PeiqinZhuang/WildFish
7、Python 3.8
PS:可以使用项目文件夹中YOLOv7自带的requirement.txt安装必要库

硬件需求
作者本人设备:
系统:Windows 11
处理器:Intel® Core™ i7-7700HQ CPU @ 2.80GHz 2.80 GHz
内存大小:16GB运行内存
硬盘大小:2T固态硬盘
显卡:NVIDIA GeForce GTX 3060 6G
外设:水下摄像头(非必须)
系统流程
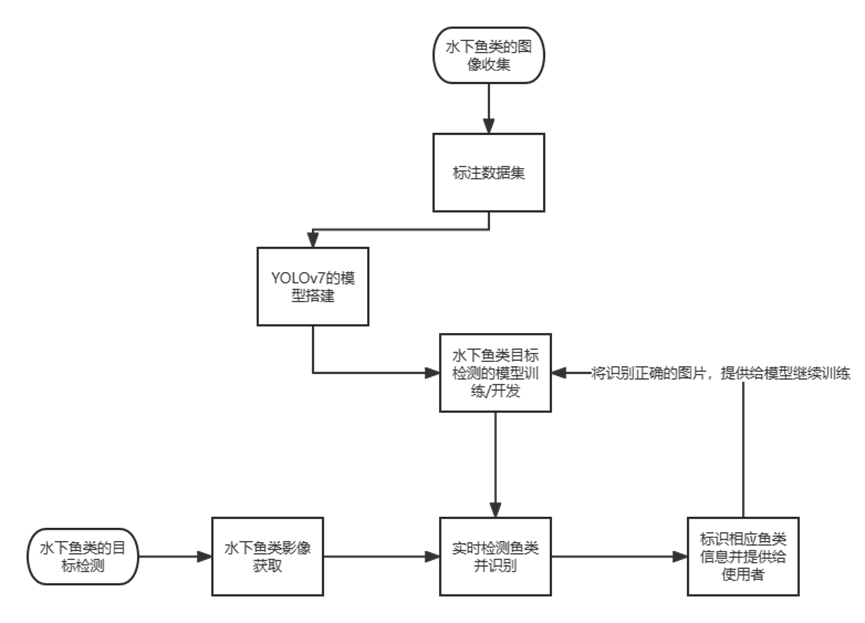
数据预处理
WildFish数据集中含有1000个鱼类类别,总计含有54459张图片。为了保证模型效果以及个人实验设备性能较弱的影响,除去部分无效数据,从采集到的图片中筛选出了10种图片数量多且分布均匀的鱼类,分别是:Acanthurus_coeruleus,Aluterus_scriptus, Carcharhinus_amblyrhynchos,Carcharodon_carcharias,Cephalopholis_fulva,Diodon_holocanthus,Pomacanthus_imperator,Pomacanthus_paru,Pterois_volitans,Rhincodon_typus,参与模型训练,每种鱼类大概100张图片,平均每张图片含有1-2个样本。
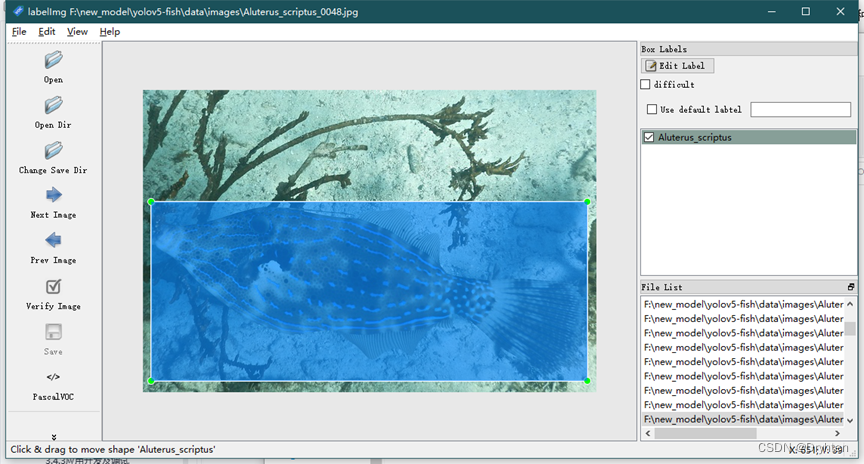
在目标检测中,我们对原始的图片中的目标要进行人工的手动标框,即bounding box。通过LabelImg对水中鱼类数据标注,将图片中的鱼类用矩形框出来,并标注鱼类的种类。
划分数据集
在划分数据集开始之前先检查一下需要的东西:
- data/Annotations文件夹中是否已经把前一步LabelImg标好的标签信息,后缀为.xml格式的文件都放进去了
- data/images文件夹中是否已经把参与模型训练的图片都放在这里了
- 删除data文件夹下的train.txt,test.txt,val.txt,.cache后缀的也删掉。(如果有的话)
- 清空data/ImageSets文件夹。
- 清空data/labels文件夹。
都准备好了就可以开始了。
1、按8:1:1划分为训练集、测试集以及验证集
运行split_train_val.py
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='data/Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='data/ImageSets', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
2、将LabelImg标注的Annotations文件夹里的xml文件读取标签所在坐标信息并转换为txt文件保存
运行voc_label.py
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'test', 'val']
classes = ['Acanthurus_coeruleus', 'Aluterus_scriptus', 'Carcharhinus_amblyrhynchos', 'Carcharodon_carcharias',
'Cephalopholis_fulvaw', 'Diodon_holocanthus', 'Pomacanthus_imperator', 'Pomacanthus_paru',
'Pterois_volitans',
'Rhincodon_typusw']
def convert(size, box):
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
dw = 1. / size[0]
dh = 1. / size[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % image_id)
out_file = open('data/labels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % image_set).read().strip().split()
list_file = open('data/%s.txt' % image_set, 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % image_id)
convert_annotation(image_id)
list_file.close()
最终将图片分为了10类,Acanthurus_coeruleus类有119张,Aluterus_scriptus类有145张,Carcharhinus_amblyrhynchos类有117张,Carcharodon_carcharias类有102张,Cephalopholis_fulva类有114张,Diodon_holocanthus类有115张,Pomacanthus_imperator类有116张,Pomacanthus_paru类有116张,Pterois_volitans类有120张,Rhincodon_typus类有116张,总计图片1180张。
并按9:1:1划分为了训练集、测试集、验证集。训练集有955张,测试集有118张,验证集有107张。
模型训练
训练前设置
在data/fish.yaml中设置训练集、验证集、测试集信息的载入地址,鱼类标签信息以及种类类数。
fish.yaml
train: data/train.txt
val: data/val.txt
test: data/test.txt
test_xml: data/xml
# Classes
names: ['Acanthurus_coeruleus', 'Aluterus_scriptus', 'Carcharhinus_amblyrhynchos', 'Carcharodon_carcharias',
'Cephalopholis_fulvaw', 'Diodon_holocanthus', 'Pomacanthus_imperator', 'Pomacanthus_paru', 'Pterois_volitans',
'Rhincodon_typusw']
# Classes Num
nc: 10
开始训练
我们在YOLOv7x模型基础上冻结前10层进行迁移学习训练水下鱼类目标检测模型。
训练模型,cmd运行代码:
python train.py --img 640 --batch 8 --epoch 300 --data data/fish.yaml --cfg cfg/deploy/yolov7x.yaml --weights weights/yolov7x.pt --device 0 --freeze 10
参数可以根据自己需求调整。
训练结束
模型训练结束后,YOLOv7会自动生成模型训练报告,存储在runs/train/exp_x文件夹内。
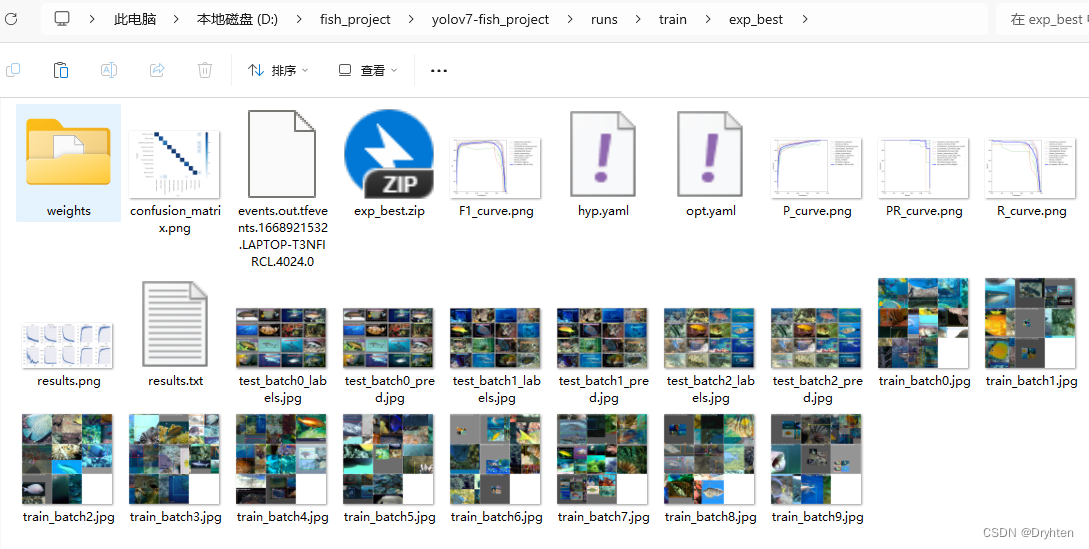
大致展示一下训练报告
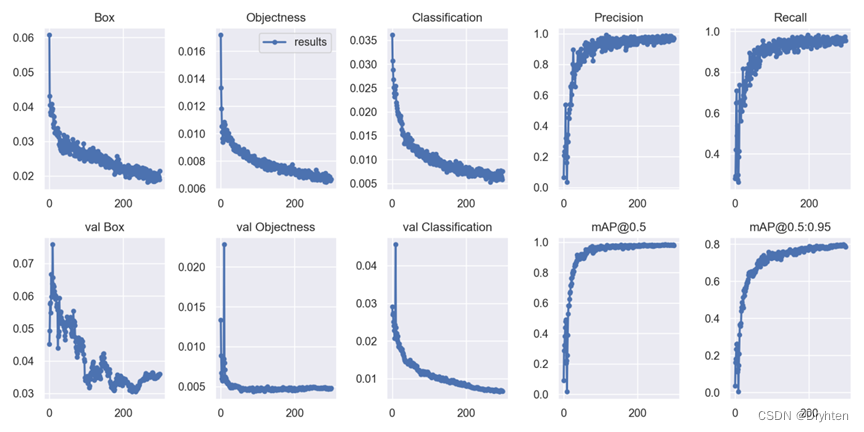
从训练结果中可以看出,模型的mAP_0.5基本在0.97浮动,并且mAP_0.5:0.95接近0.8,说明模型训练效果相对较好。
其余指标下面展示一下,不做分析。
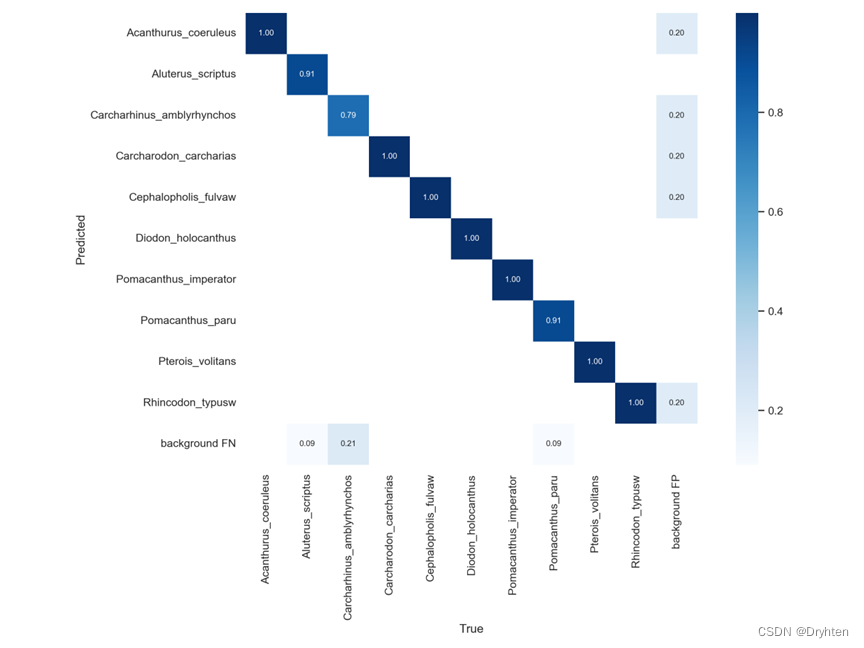
混淆矩阵
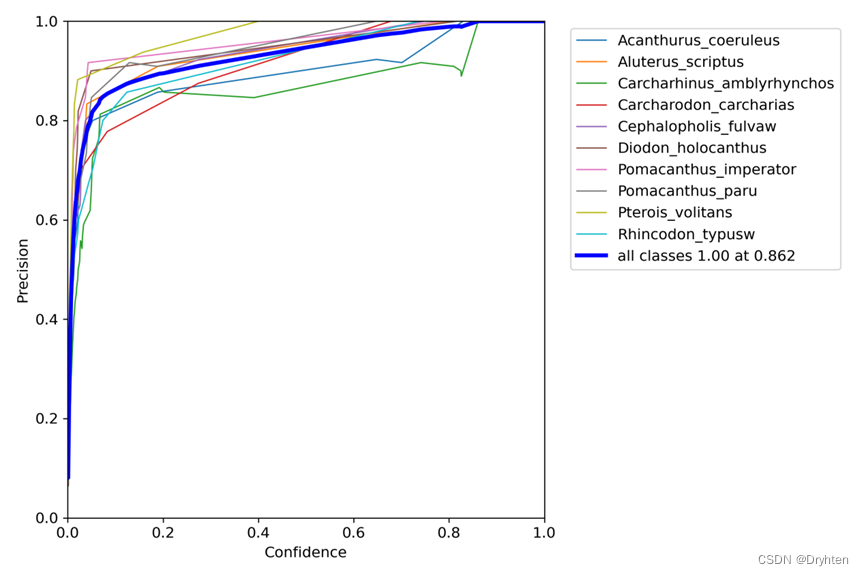
置信度与P准确率的曲线
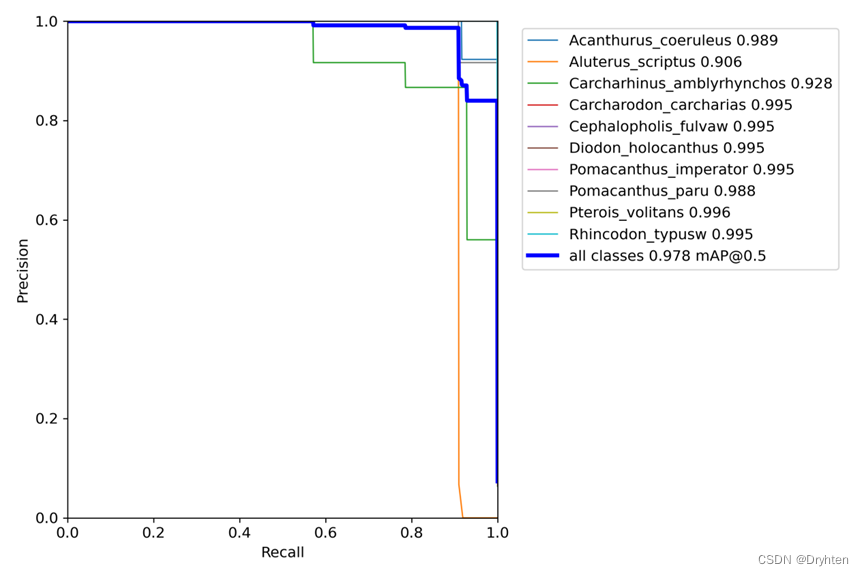
R召回率与P准确率的曲线
置信度与R召回率的曲线
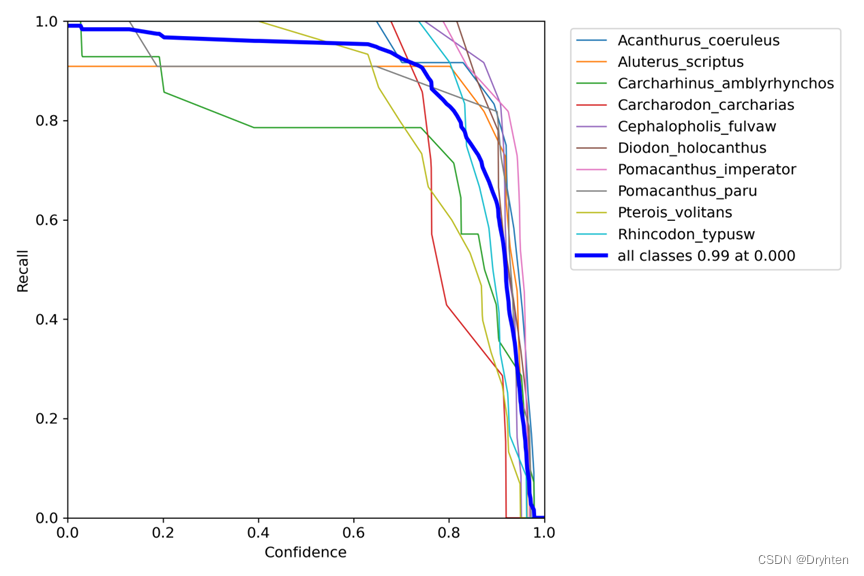
F1-置信度图
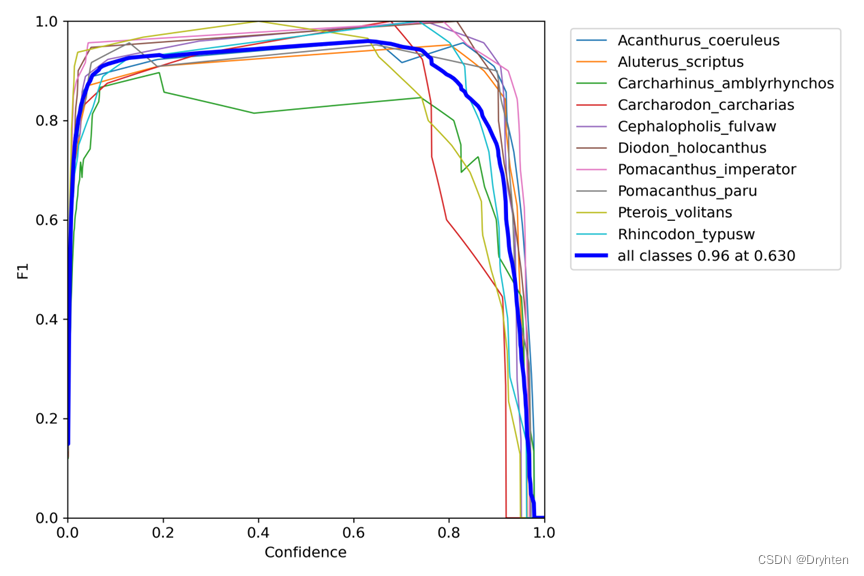
模型预测
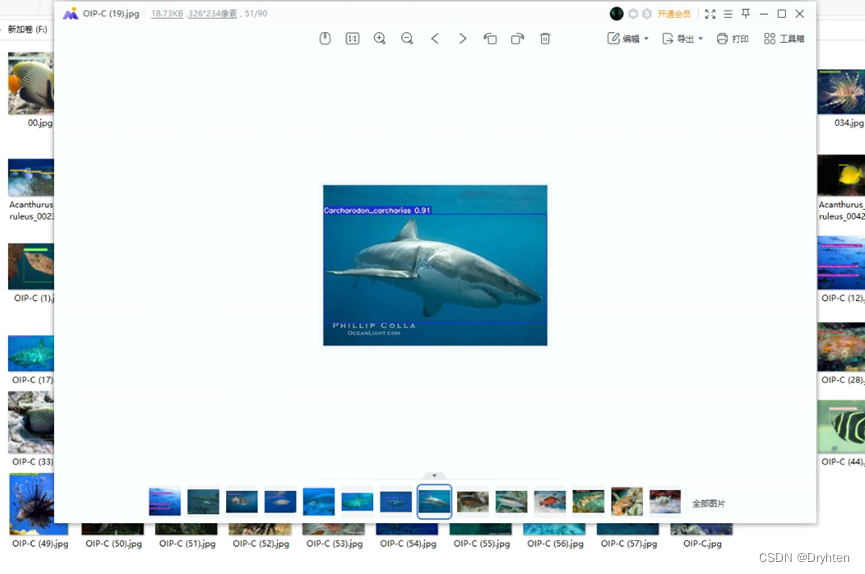
使用模型进行预测,查看模型效果
cmd运行代码:python detect.py --weights 7x_model_freeze10/weights/best.pt --img-size 640 --source data/Samples
单个图片预测效果图
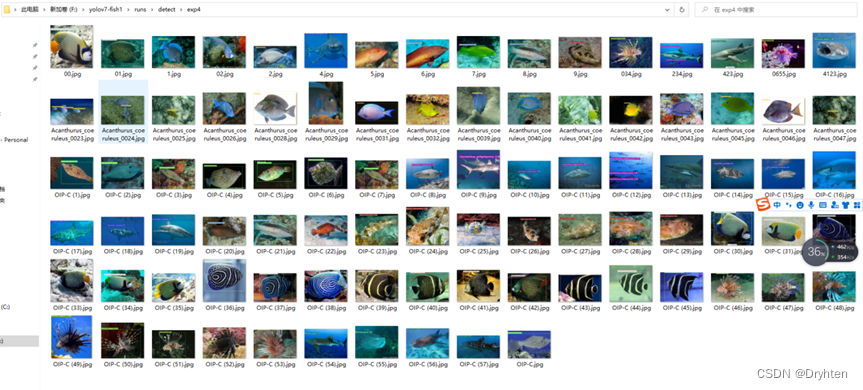
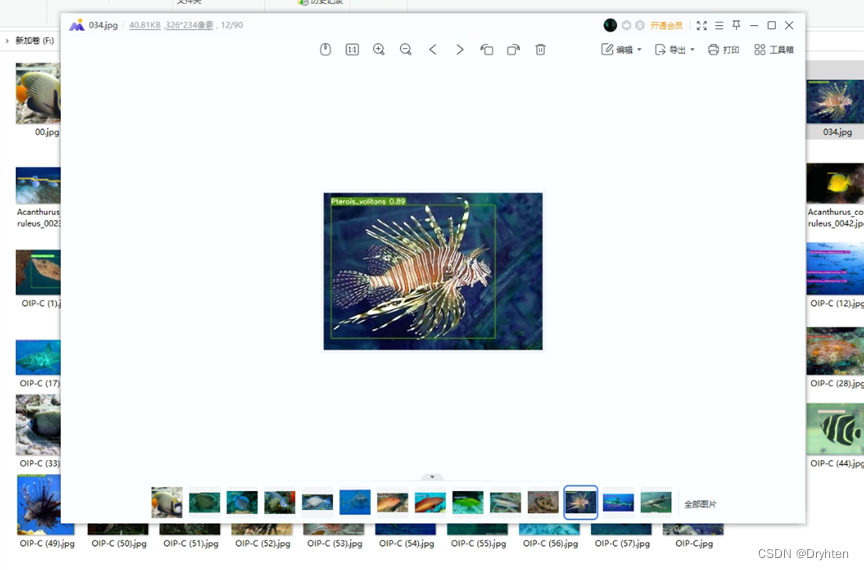
批量图片预测效果图

通过与预先标记的标签与区域进行对比,基于水下鱼类目标检测场景,设计的118个用例,全部测试通过。
问题与展望
存在的问题
1、数据量不足,数据类别少,导致模型的通用性较差。
2、训练环境较差,计算资源少,导致模型训练时长较长。
3、存在部分种类鱼类的识别准确率相对较低,可以针对性增加该种鱼类图片,提升模型识别效果。
展望
在有足够的资源和时间的情况下,可以搜集更多的水下鱼类图片,寻找改善水下场景图片的方法,调优训练参数,训练更多的次数,以提升模型性能与精度。
海洋复杂成像环境导致光视觉系统获取的水下图像严重退化,这也是基于光视觉的水下目标探测识别技术面临的巨大挑战。

水下影像衰减的原因有:光吸收引起的色彩偏移、光前向散射所引起的细节模糊、反差较小。
出现色彩衰退,对比度低,细节不清晰等问题。首先,由于水的吸收,光在传播时会产生能量的衰减;红光在水中的衰减速度最快,而绿光的衰减速度最慢;此外,水中光线的散射效应也会影响到水下影像的成像。散射作用可分为正向散射和逆向散射,即指由水里的物体在向照相机发射时产生的散射,这种散射是从原始发射方向上产生的;所谓后向散射是指当光线碰到水中的物体时,由于受到水中杂质的影响,产生的散射会被相机直接吸收。
由于缺乏有效的识别信息,使得水下目标的检测和识别变得更加困难。近年来,由于高技术水下成像技术的不断发展,所采集的水下影像品质有所提高,但仍存在色彩衰减、对比度低、细节不清晰等问题,同时还需考虑使用费用,所以必须对水下影像进行强化。
完整项目下载
链接:https://pan.baidu.com/s/18VM73ClXYWUPfreT0dvd_g?pwd=eam4
提取码:eam4
项目复现大致说明:
1、创建新的环境
2、前往pytorch官网安装pytorch与cuda
3、通过requirement.txt安装环境
4、运行split_train_val.py
5、运行voc_label.py
6、通过run_code.txt内的运行训练或预测代码

















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









