








1. 区别
本文工作基于faster RCNN , 区别在于
- 改进了rpn,anchor产生的window的宽度固定为3。
- rpn后面不是直接接全连接+分类/回归,而是再通过一个LSTM,再接全连接层。
- 坐标仅仅回归一个y,而不是x1, y1, x2, y2
- 添加 side-refinement offsets(可能这个就是4个回归值中的其中2个)
2. 问题分析
- 文字目标的特殊性,一个很大的先验是,文字总是水平排列的。
- 文字的特征总感觉体现在edge上。
自然场景文字检测的难点在于:小目标,遮挡,仿射畸变。本文使用VGG16,只使用conv5,可能对小文字的检测效果不好。
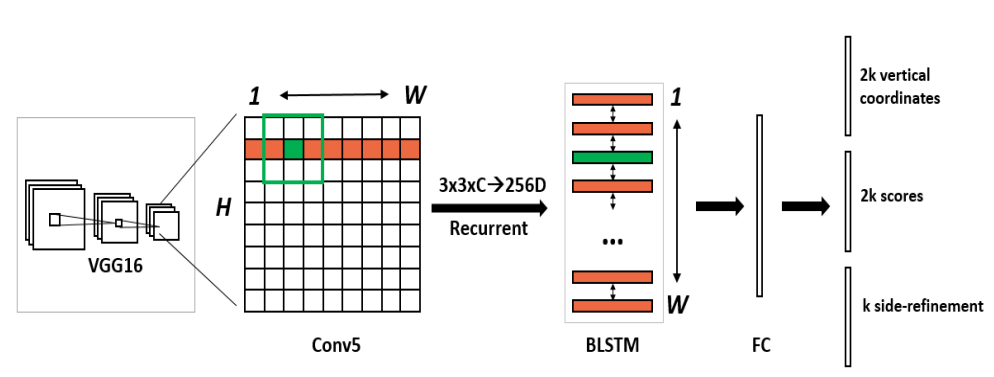
3. 实验
CTPN用在ICDAR2017中文检测数据集上的结果:AP=0.18
1.检测准确率和目标大小的关系
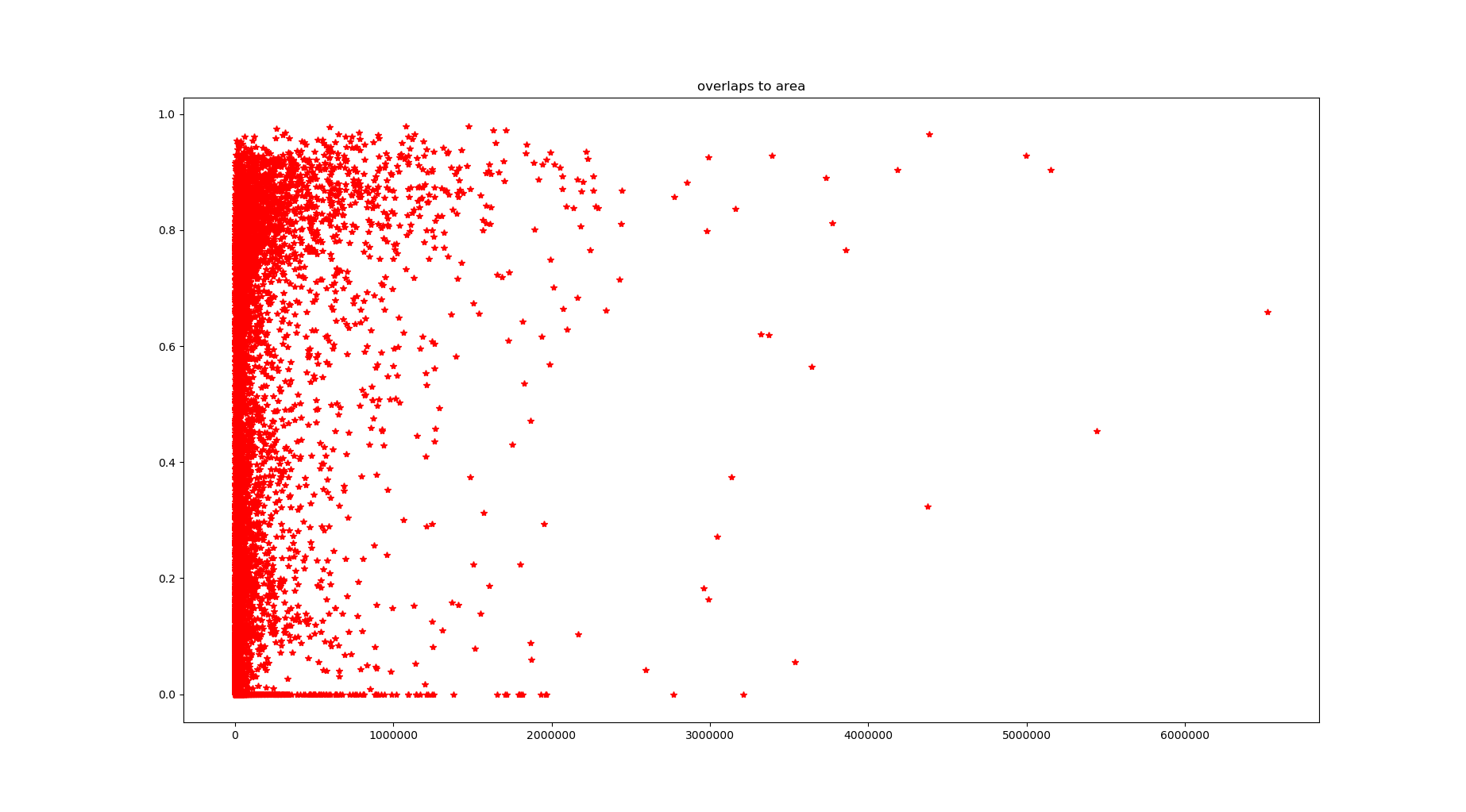
图1
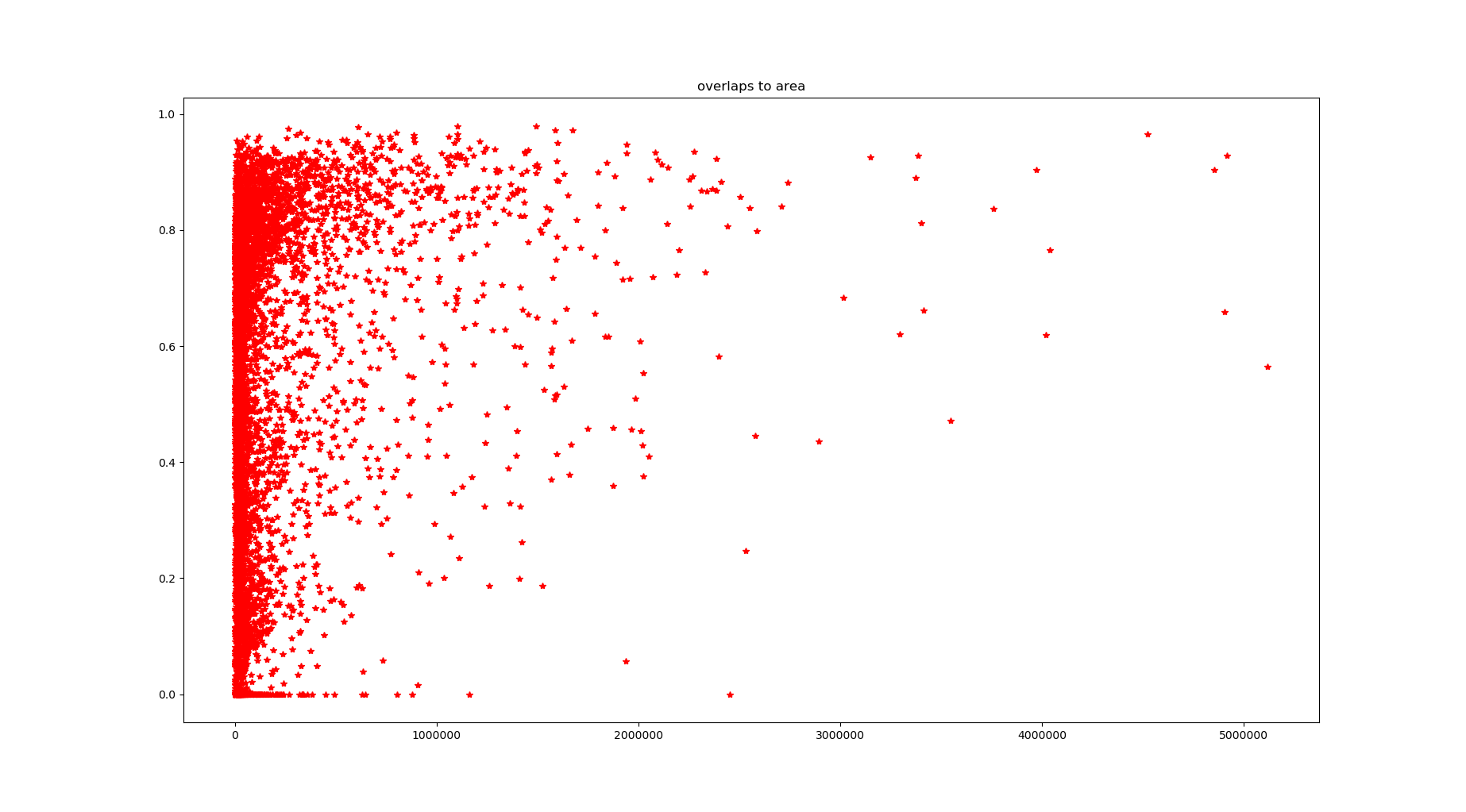
图2
图1、2是目标重叠率和目框面积的关系,其中图1是手工标记框和预测框的重叠率,纵坐标低于0.5表示漏检测;图2是预测框和手工标记框的重叠率,纵坐标低于0.5表示错检测。
当目标比较小时,漏检测和误检测的数量比较多。图片如下:


2.检测准确率和目标长宽比的关系
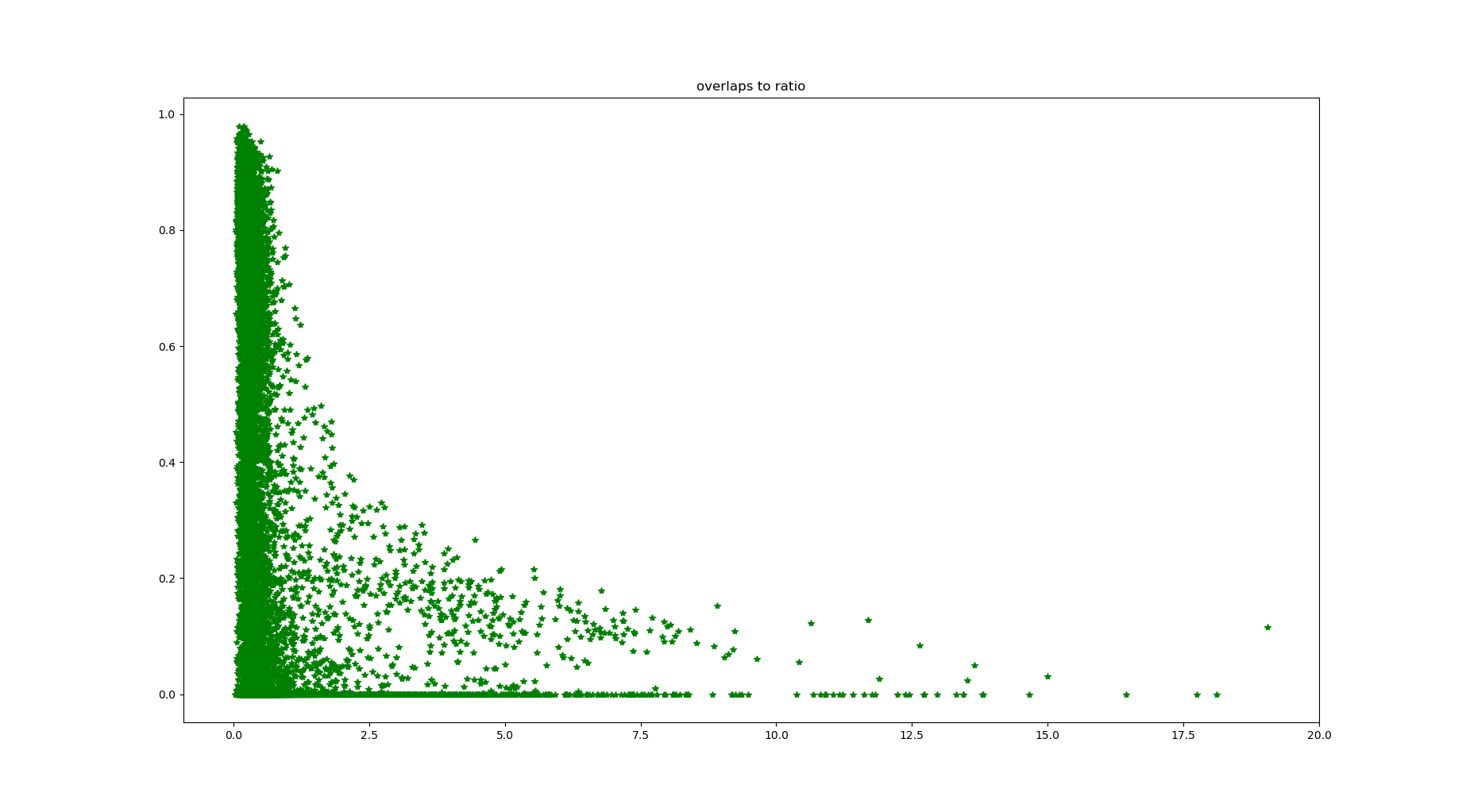
图3
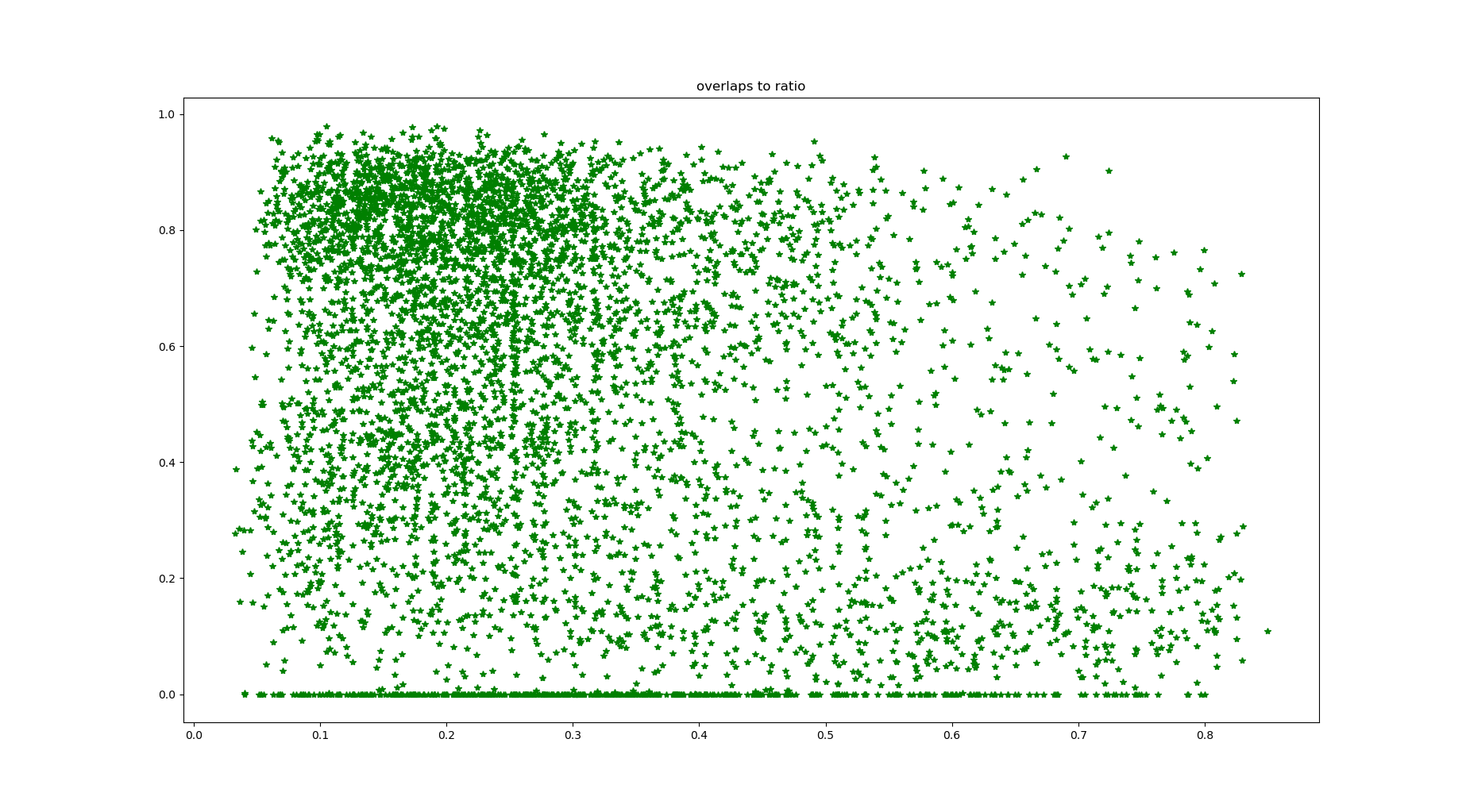
图4
图3、4分别是重叠率和目标长宽比的关系。图3的横坐标是手工标记的目标长宽比,最大能到20,图4的横坐标最大只有1(anchor的限制)。该算法对于垂直排列的中文汉字,识别率很低(毕竟只是针对英文文字的检测,英文字母只有水平排列)这是这个算法本身的限制所在。

















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









