







简介
CTPN,全称Connectionist Text Proposal Network,连接文本建议网络。
它是用来定位文本序列的一种网络,利用垂直anchor来预测固定宽度建议框的位置坐标和分类分数。基于目标检测网络Faster-rcnn中的RPN区域建议网络和LSTM循环神经网络,可以得到准确的文本框。
网络模型
1.采用VGG16网络提取空间特征,下采样16倍后的卷积特征图Conv5层,输出维度为Nx H x W x C;
2.采用3x3大小的滑动窗口在feature map上滑窗,每个窗口得到3x3xC的特征向量,每个点都融合了周围9个点的信息,输出维度为tf:N x H x W x C(或caffe:N x H x W x 9C);
3.把feature map reshape为(NH) x W × C,输入BLSTM中提取每一列的特征,输出维度为(NH) × W × 256,然后reshape为N × 256 × H × W;
4.输入FC全卷积层,输出维度为N × H × W × 512;
5.输入RPN网络,输出三个分支,从上到下分别为:
(1)维度N × H × W × 2k,k表示每个像素位置有k个anchor,每个anchor有2个坐标,分别为中心y坐标vc 和 高度vh;
(2)维度为N × H × W × 2k,k表示每个像素位置有k个anchor,每个anchor有2个前背景得分;
(3)维度为N × H × W × k,k表示每个像素位置有k个anchor,每个anchor的水平精修side-refinement比例o。
6.得到很多text proposal,使用nms来过滤掉多余的box;
7.使用基于图的文本行构造算法,将得到的一个一个的box合并成文本行。

anchor机制
10个anchor的尺寸如下:
宽度都是16像素,高度从11~273像素变化(每次除以0.7)
heights=[11, 16, 23, 33, 48, 68, 97, 139, 198, 283]
widths=[16,16,16,16,16,16,16,16,16,16]
因为宽度是固定的,所以只需要anchor的中心的y坐标以及anchor的高度就可以确定一个anchor,anchor坐标计算公式如下:
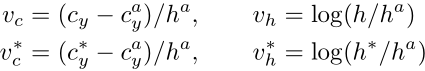
损失函数
损失函数分为三部分:
1.Ls:每个anchor是否是正样本的分类loss;
2.Lv:每个anchor的中心y坐标和高度loss;
3.Lo:因为每个anchor的宽是一定的,所以代表box的x轴回归损失。
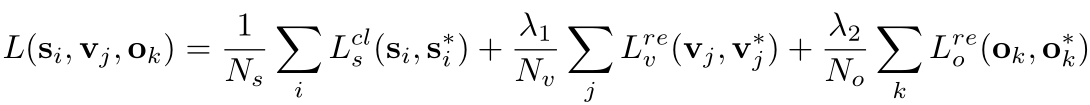
训练
NMS阈值设置:
1.与实际边界框IoU大于0.7的anchor作为正样本,与实际边界框IoU最大的那个anchor也定义为正样本;
2.与实际边界框IoU小于0.5的anchor定义为负样本。
训练数据:
每个小批量数据的anchor数量固定为128,正负样本的比例为1:1。如果正样本不够就用负样本补齐。
训练时将输入图像的短边resize为600来调整输入图像的大小,同时保持其原始长宽比。
代码实现
VGG特征提取========>输出维度为N x H x W x C
def vgg_base(input, trainable):
base_model = VGG16(weights=None, include_top=False, input_shape=input)
base_model.load_weights('vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
if (trainable == False):
for ly in base_model.layers:
ly.trainable = False
return base_model.input, base_model.get_layer('block5_conv3').output
3x3滑动窗口========>输出维度为N x H x W x C(tensorflow)
x = Conv2D(512, (3, 3), strides=(1, 1), padding='same', activation='relu',
name='rpn_conv1')(base_layers)
reshape========>输出维度为(NH) x W × C
def reshape(x):
b = tf.shape(x)
x = tf.reshape(x, [b[0] * b[1], b[2], b[3]])
return x
BLSTM网络========>输出维度为(NH) × W × 256
# 双向LSTM,每个LSTM有128个隐层
x2 = Bidirectional(LSTM(128, return_sequences=True), name='blstm')(x1)
reshape========>输出维度为N × H × W × 256
def reshape2(x):
x1, x2 = x
b = tf.shape(x2)
x = tf.reshape(x1, [b[0], b[1], b[2], 256])
return x
FC层========>输出维度为N × H × W × 512
x3 = Conv2D(512, (1, 1), padding='same', activation='relu', name='lstm_fc')(x3)
RPN层========>输出维度为N × H × W × 20
#由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels
cls = Conv2D(10 * 2, (1, 1), padding='same', activation='linear', name='rpn_class')(x3)
regr = Conv2D(10 * 2, (1, 1), padding='same', activation='linear', name='rpn_regress')(x3)
Loss函数
loss={'rpn_class_reshape': rpn_loss_cls, 'rpn_regress_reshape': rpn_loss_regr}
def rpn_loss_cls(y_true, y_pred):
"""
softmax loss
"""
y_true = y_true[0][0]
cls_keep = tf.where(tf.not_equal(y_true, -1))[:, 0]
cls_true = tf.gather(y_true, cls_keep)
cls_pred = tf.gather(y_pred[0], cls_keep)
cls_true = tf.cast(cls_true, 'int64')
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=cls_true, logits=cls_pred)
return K.switch(tf.size(loss) > 0, K.clip(K.mean(loss), 0, 10), K.constant(0.0))
def rpn_loss_regr(y_true, y_pred):
"""
smooth L1 loss
"""
sigma = 9.0
cls = y_true[0, :, 0]
regr = y_true[0, :, 1:3]
regr_keep = tf.where(K.equal(cls, 1))[:, 0]
regr_true = tf.gather(regr, regr_keep)
regr_pred = tf.gather(y_pred[0], regr_keep)
diff = tf.abs(regr_true - regr_pred)
less_one = tf.cast(tf.less(diff, 1.0 / sigma), 'float32')
loss = less_one * 0.5 * diff ** 2 * sigma + tf.abs(1 - less_one) * (diff - 0.5 / sigma)
loss = K.sum(loss, axis=1)
return K.switch(tf.size(loss) > 0, K.mean(loss), K.constant(0.0))















 5679
5679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









