







目录
前言
今天我们回到ResNet问世之前,聊一篇比较有意思的论文:《Going deeper with convolutions》,这篇文章里提出了Inception架构,以及著名的GoogLeNet,注意它的L是大写的,作者的意思是为了致敬LeNet。
这篇论文我个人觉得讲得有些许哲学,因此今天我们的重点主要放在它的Inception结构和网络结构上。
为何Inception
论文作者在论文中提到,当时提高网络性能最直接的方法有两个,加宽与加深。加深当然就是堆叠更多层数。而加宽对于卷积神经网络来说,就是增加通道数。
这种直接的方法会带来两个问题。首先是会增加参数,从而带来过拟合问题,如果数据集有限的话,过拟合问题会更严重。第二个问题就是需要更多计算,但大多数计算很有可能无质量,比如说最后计算出来一些权重为0,那么这些神经元基本就等于没用的。所以这不仅是计算量的问题,还有计算效率低下的问题。
随后作者提出,解决这两个问题的根本方法就是引入稀疏性,比如把全连接换成稀疏连接,甚至在卷积里也引入稀疏。这个稀疏在整篇论文里出现了很多次,但作者对它的描述有些抽象,我对其理解也不是很深,因此我们这里直接给出作者的结论:为了解决上述的问题,所以要引入稀疏性,但涉及非均匀稀疏数据结构的数值计算时,当今的计算基础设施效率非常低,所以作者就想,能不能搞一种结构,可以用密集的组件去近似和覆盖最优局部稀疏结构。因此作者就整出了下面的Inception结构。
Inception结构
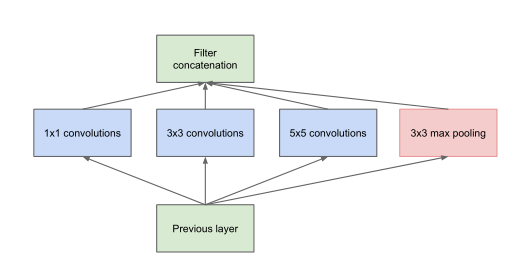
图片来自论文
作者想出这样一个结构,下面是入口,然后分成四条路,分别进行三个卷积核一个池化,然后合在一起输出。经过这四条路后,得到的特征图的长宽都是一样的,只是在通道这里合在一起。
先说说为什么要分三个卷积。根据我们之前说的感受野概念和例子,我们可以知道,卷积核大的,感受野也越大。感受野,顾名思义,就是卷积核从图像中获取信息的区域,如果这个区域越大,说明我获得的越是一个尺度大的特征(或者说偏向全体的特征),而区域越小,说明我获得的是一个尺度小的特征(或者说是偏向局部的特征)。就像我们拿个放大镜一点点看和我一瞥扫一眼,获得的信息尺度是不一样的。
走三条路,相当于我们获取了三个不同尺度的信息。那为什么要获取三个不同尺度的信息呢?作者在论文中提到赫布原理:两个神经元或者神经元系统,如果总是同时兴奋,就会形成一种组合,其中一个神经元的兴奋会促进另一个的兴奋。放到这里我们可以理解为同一个尺度的信息相关性强,把他们组合在一起,可以相互促进,加快收敛。
然后为什么有条路是池化呢?论文作者是这么说的:“此外,由于池操作对于当前最先进的卷积网络的成功至关重要,因此建议在每个这样的阶段添加一个替代的并行池路径也应具有额外的有益效果。”总结一下就是,因为现在先进的卷积能成功都是有池化的,所以我们在这里加一个,应该也是有益的吧。
四条路过后为什么要合一块呢?举个例子,有一个Inception结构的块,它的输入是16个通道的,输出是256个通道的。而有另外一个卷积层,设它的卷积核是5*5的,它的输入和输出也是16和256个通道。那么其实卷积层的这个输出是冗余的256个5*5尺度的信息,但Inception输出同样是256个通道,但是它有四个尺度的信息,可能每个尺度占据64个通道,冗余信息就更少,这个输出更加“干货”。
但这个结构其实存在问题,比如说到了深的层,每条路输出的通道数也多起来了,四条路加在一起,通道数就更多了,参数量就会蹭蹭上涨,那怎么办呢?这个时候就要1*1卷积出马了。比如说我们通过一个3*3的卷积,将16通道的变为256通道,那么这个参数就有3*3*16*256=36864个。但如果我先通过一个1*1的卷积,将通道16变为8通道,进行一个降维后,再通过3*3的卷积,变成256通道的,那么参数就变为:1*1*16*8+3*3*8*256=18560个。可以说是少了一半有多。作者使用了这个方法,因此上面的结构就变成了下面这个:
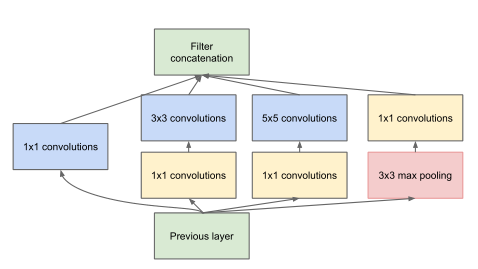
图片来自论文
GoogLeNet网络结构
这个网络的网络结构有点大,我就不摆出来了,这里推荐一篇博客,里面有一张图标注了每一层的计算细节,大家可以结合下面这个图研究一下:
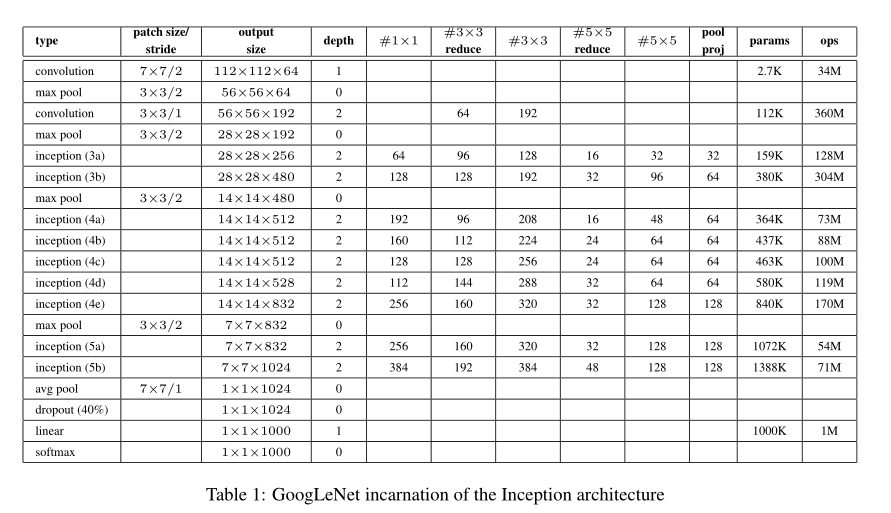
图片来自论文
这里主要讲几个细节。
首先是辅助分类器。作者在论文中提到:“我们期望鼓励分类器中较低阶段的区分,增加传播回的梯度信号,并提供额外的正则化。”,所以他在中间搞了两个如下图的分支,在训练期间,它们的损失以折扣权重加到网络的总损失中(辅助分类器的损失加权为0.3)。在推理时,这些辅助网络被丢弃。后面被证明其实这两个分支基本没什么用。
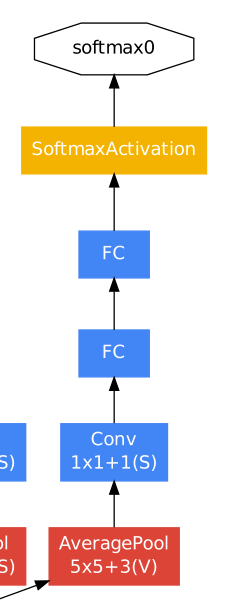
图片来自论文
第二个细节是均值池化层,也就是下图这个:

图片来自论文
这个东西实际就是将每个通道的特征图的所有值加起来求平均。比如说,最后这个均值池化的输入是7*7*1024,那么就相当于有1024个通道,每个通道都是7*7的大小,我将这7*7=49个数据全部加起来求平均。最后输出的就是1*1024。
Pytorch实现
下面依然是熟悉的代码实现环节,关键的点都在注释里了:
# 引入
import torch.nn as nn
import torch
# 先来定义Inception模块
class InceptionBlock(nn.Module):
def __init__(self,in_channels,ch1x1,ch3x3red,ch3x3,ch5x5red,ch5x5,chproj):
super(InceptionBlock,self).__init__()
# 1*1卷积分路
self.branch1=nn.Sequential(
nn.Conv2d(in_channels=in_channels,out_channels=ch1x1,kernel_size=1,stride=1),
nn.ReLU(inplace=True)
)
# 3*3卷积分路
self.branch2=nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=ch3x3red, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=ch3x3red, out_channels=ch3x3, kernel_size=3, stride=1,padding=1),
nn.ReLU(inplace=True)
)
# 5*5卷积分路
self.branch3=nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=ch5x5red, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=ch5x5red, out_channels=ch5x5, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True)
)
# 池化层
self.branch4=nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channels=in_channels, out_channels=chproj, kernel_size=1, stride=1),
nn.ReLU(inplace=True)
)
def forward(self,x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
all=[branch1,branch2,branch3,branch4]
out=torch.cat(all,dim=1)
return out
# 定义辅助分类器
class Auxclassifier(nn.Module):
def __init__(self,in_channels,class_num):
super(Auxclassifier, self).__init__()
# 均值池化
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
# 1*1卷积
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=128, kernel_size=1,stride=1)
self.ReLU = nn.ReLU(inplace=True)
# 全连接输出
self.classifier=nn.Sequential(
nn.Dropout(p=0.7),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, class_num)
)
def forward(self,x):
x=self.averagePool(x)
x=self.conv(x)
x=self.ReLU(x)
x=torch.flatten(x,start_dim=1)
out=self.classifier(x)
return out
# 定义GoogLeNet
class GooLeNet(nn.Module):
def __init__(self,class_num=1000,aux_flag=True):
super(GooLeNet, self).__init__()
self.aux_flag=aux_flag
# 在堆叠inception模块前那些
self.before_inception=nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
# LRN没鬼用就不写了
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=192, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# LRN没鬼用就不写了
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 堆叠inception
self.inception3a = InceptionBlock(192, 64, 96, 128, 16, 32, 32)
self.inception3b = InceptionBlock(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.inception4a = InceptionBlock(480, 192, 96, 208, 16, 48, 64)
self.inception4b = InceptionBlock(512, 160, 112, 224, 24, 64, 64)
self.inception4c = InceptionBlock(512, 128, 128, 256, 24, 64, 64)
self.inception4d = InceptionBlock(512, 112, 144, 288, 32, 64, 64)
self.inception4e = InceptionBlock(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.inception5a = InceptionBlock(832, 256, 160, 320, 32, 128, 128)
self.inception5b = InceptionBlock(832, 384, 192, 384, 48, 128, 128)
# 如果使用aux
if aux_flag:
self.aux1=Auxclassifier(512,class_num)
self.aux2=Auxclassifier(528,class_num)
# 均值池化
self.averagePool = nn.AdaptiveAvgPool2d((1,1))
# 全连接输出
self.classifier = nn.Sequential(
nn.Dropout(p=0.4),
nn.Linear(1024, class_num)
)
def forward(self,x):
x=self.before_inception(x)
x=self.inception3a(x)
x = self.inception3b(x)
x=self.maxpool3(x)
x = self.inception4a(x)
if self.training and self.aux_flag:
out1=self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.training and self.aux_flag:
out2=self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x=self.averagePool(x)
x = torch.flatten(x, start_dim=1)
out=self.classifier(x)
if self.training and self.aux_flag:
return out,out1,out2
return out作者:公|众|号【荣仙翁】
内容同步在其中,想看更多内容可以关注我哦。














 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









