






1.np
1.np.c_
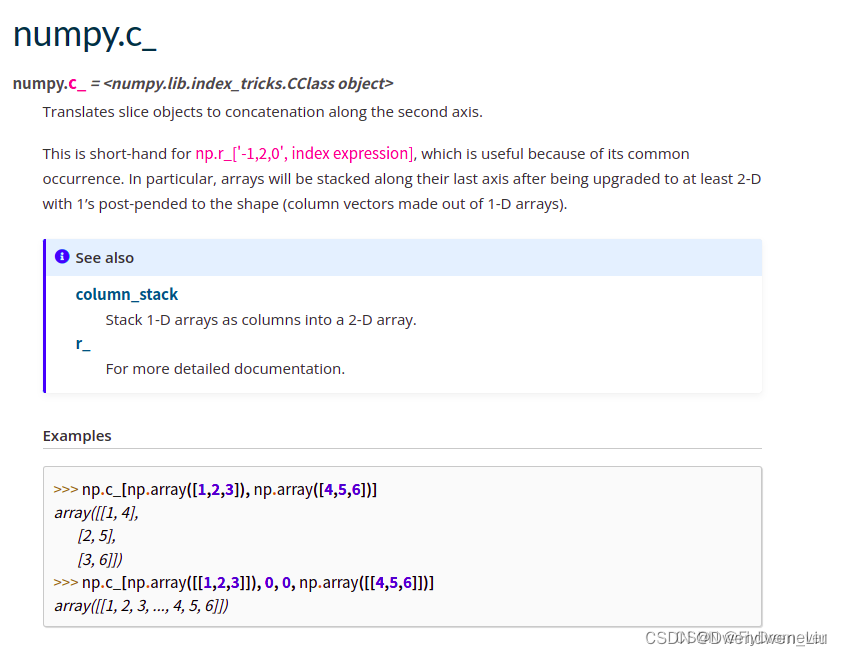
numpy 学习之 np.c_的用法_np.c_函数-CSDN博客
2.pd
1.dataframe.pivot()
对数据重塑df = df.pivot(index='name',columns='year',values='gdp')的功能
新数据集索引列 = 原数据集'name'列中的值
新数据集列名 = 原数据集‘year’列中的值
新数据集数据 = 原数据集'gdp'列中的值
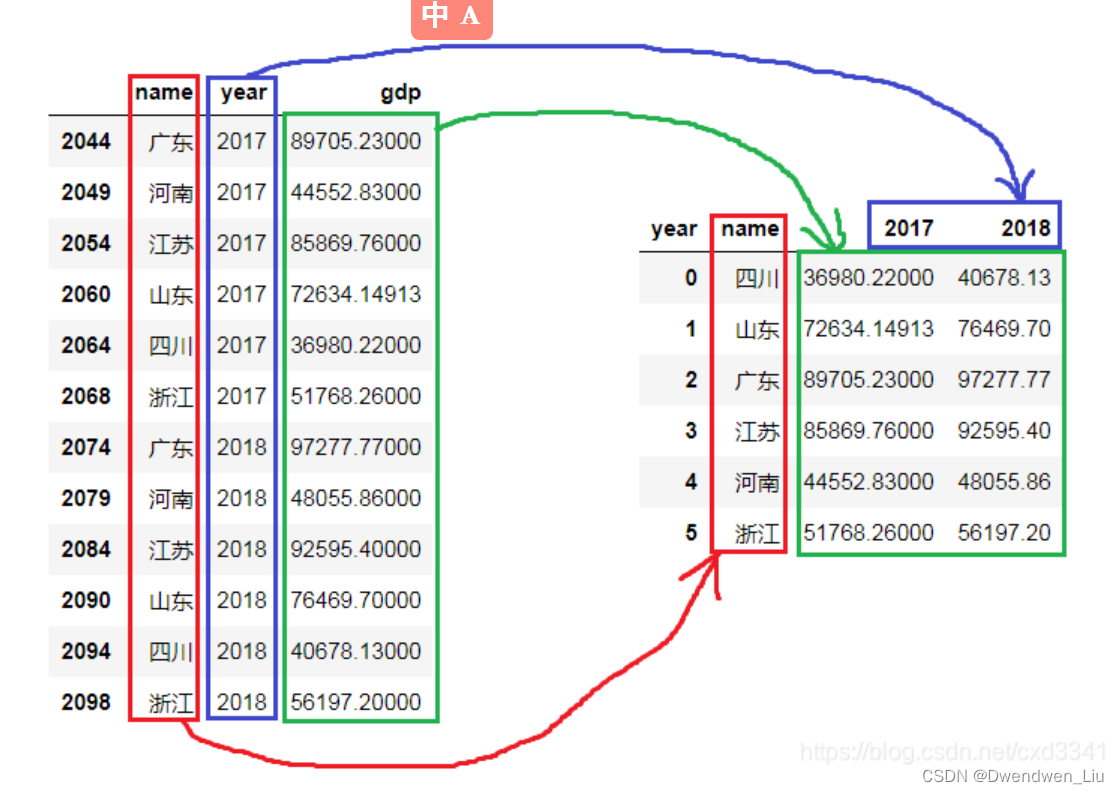
Python dataframe.pivot()用法解析_dataframe pivot-CSDN博客
2.pd.merge()
以index为链接键 需要同时设置left_index= True 和 right_index= True,或者left_index设置的同时,right_on指定某个Key。总的来说就是需要指定left、right链接的键,可以同时是key、index或者混合使用。
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
# 只有K0、K2有对应的值
pd.merge(left,right,how= 'inner',left_index=True,right_index=True)
Out[51]:
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/brucewong0516/article/details/82707492【python】详解pandas库的pd.merge函数_pd.merge( how='left', left_on='i', right_on=')-CSDN博客
3.pd.sort_values()
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
#### 参数说明
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照索引排序,即纵向排序,如果为1,则是横向排序
by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名";
ascending:布尔型,True则升序,可以是[True,False],即第一字段升序,第二个降序
inplace:布尔型,是否用排序后的数据框替换现有的数据框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心
na_position : {‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面
例子:
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_35290785/article/details/892825043.plt
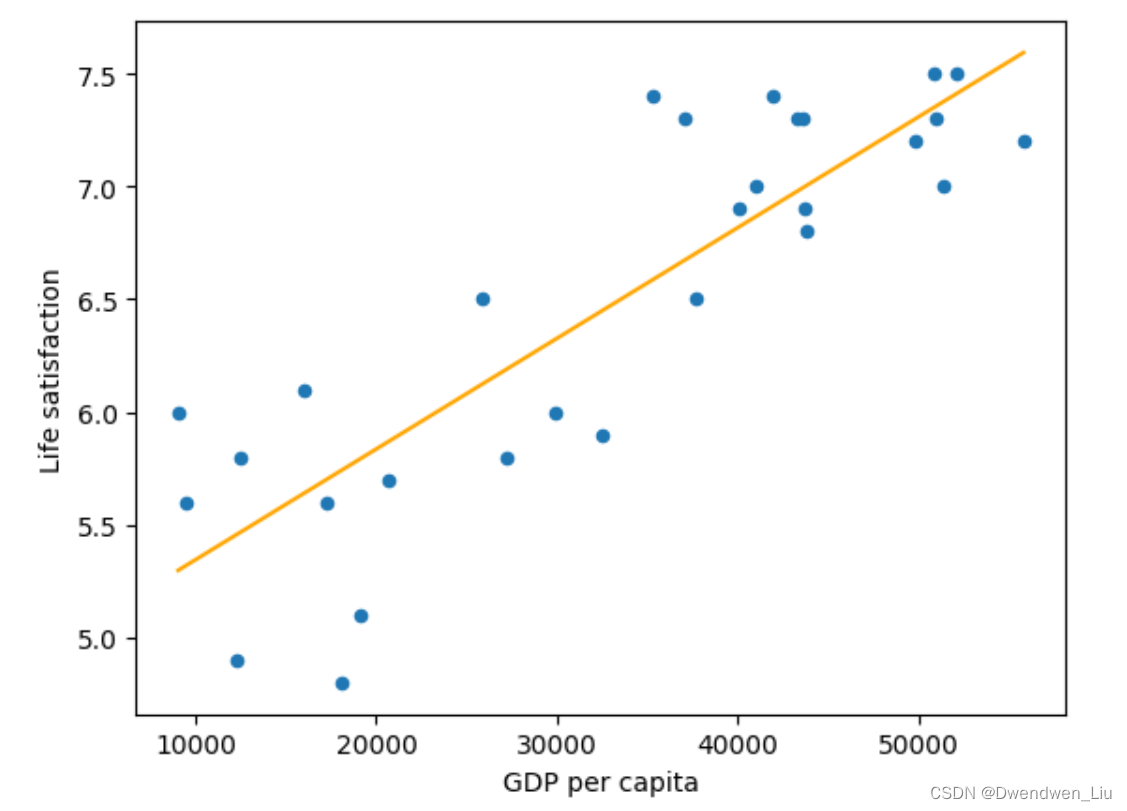
1.一个图内添加多个曲线,第一个图下面紧接着写要添加的内容
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
y_hat=[float(model.predict([[float(i)]])) for i in X]
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.plot(X,y_hat,color="orange")
plt.show()















 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









