







·错误率(error rate)&精度(accuracy)
分类错误的样本数占样本总数的比例,即如果在m个样本中有n个样本分类错误,则错误率E=n/m;
相应的,精度是分类正确的样本数占样本总数的比例,1-n/m称为“精度”。即精度=1-错误率
·查准率(precision)&查全率(recall)
初学机器学习,概念看到这里是有点懵的,询问过老师,恍然大悟。
上例子:
我们对一堆西瓜进行采样分类,我们用训练好的模型进行判别。因为我们关心的是好瓜的情况,则把好瓜定为正例。经过判别,会产生四种结果:真正例(TP),假正例(FP),真反例(TN),假反例(FN)。
TP是指事实是好瓜,测出的也是好瓜。
FP是指事实是坏瓜,测出的是好瓜。
TN是指事实是坏瓜,测出的也是坏瓜。
FN是指事实是好瓜,测出的是坏瓜。
查准率是指,真正的好瓜在预测出来是好瓜中的比例,即P=TP/(TP+FP)
查全率是指,真正的好瓜在所有好瓜中的比例,即有多少好瓜被测出来,R=TP/(TP+FN)
查准率又叫准确率,查全率又叫召回率。
顾名思义,一个关心的是查的准不准,一个关心的是查的全不全。
经验之谈,实际上不存在数学上的相关关系,但是实际应用中 查准率和查全率是一对矛盾的度量。
·P-R曲线

若一个学习器的P-R曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者。
平衡点是指查全率=查准率的点。
·ROC和AUC
ROC和AUC是评价分类器的指标,用到的数据依然包括TP,FP,TN,FN。
ROC全称是“受试者工作特征”曲线,纵轴是“真正例率”,(True Positive Rate,TPR),横轴是“假正例率”(False Positive Rate,FPR)
两者分别定义为
TPR=TP/(TP+FN)
FPR=FP/(TN+FP)
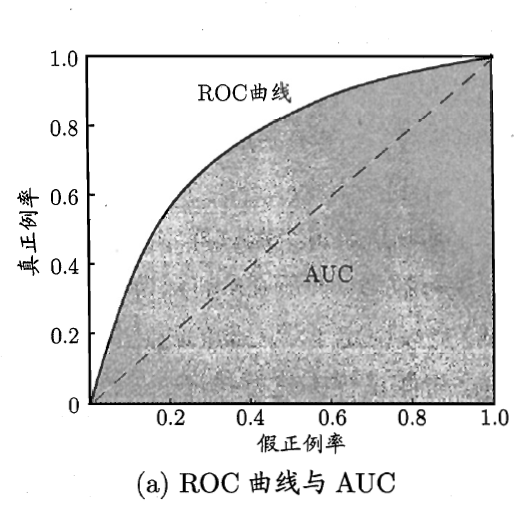
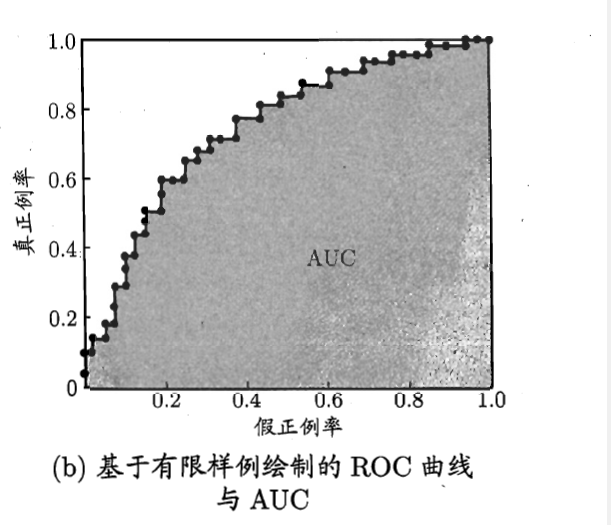
现实任务中通常是利用有限个测试样例来绘制ROC图,此时仅能获得由限个坐标时,无法产生图a中的光滑的ROC曲线,只能绘制出图b所示的近似ROC曲线。
进行学习器的比较时,与P-R图相似,若一个学习器的ROC曲线被另一个学习器的曲线完全包住,则可断言后者的性能优于前者。
若连个学习器的ROC曲线发生交叉,则难以一般性地断言两者孰优孰劣。此时如果一定要进行比较,则较为合理的判断是根据比较ROC曲线下的面积,即AUC。
注:图片均来自周志华《机器学习》















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









