







------------------------------------------------2021年6月18日重大更新--------------------------------------------------------------
目前已经退出bug修复之后的tensorflow2.3物体分类代码,大家可以训练自己的数据集,快来试试吧
csdn教程链接:手把手教你用tensorflow2.3训练自己的分类数据集_CSDN博客
b站视频链接:手把手教你用tensorflow2训练自己的数据集
数据集链接:计算机视觉数据集清单-附赠tensorflow模型训练和使用教程_CSDN博客
代码链接:vegetables_tf2.3: 基于tensorflow2.3开发的水果蔬菜识别系统 (gitee.com)
------------------------------------------------------------------dejahu---------------------------------------------------------------------
花卉识别是卷积神经网络的入门案例,这里我将模型的训练、测试、保存以及使用整合在了一起,至于原理部分,大家可以参考知乎或者B站上的回答,在这里我就不赘述了
数据集和模型下载地址
https://download.csdn.net/download/ECHOSON/19687660?spm=1001.2014.3001.5503
一起来玩
qq群:821429104
b站:宋老狗97
git地址:https://gitee.com/song-laogou/Flower_tf2.3
博客地址:https://blog.csdn.net/ECHOSON/article/details/111083808
文件目录
# 数据下载地址 https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
# 参考代码 https://tensorflow.google.cn/tutorials/images/classification
flower_tensorflow2.0
├─ data_read.py # 数据读取
├─ data_split.py # 数据切分
├─ images # 图片文件
│ ├─ 123.jpg
│ ├─ init.png
│ ├─ logo.png
│ ├─ target.png
│ ├─ 主页面.png
│ └─ 关于.png
├─ window.py # ui界面
├─ models # 模型
│ ├─ cnn_flower.h5
│ └─ mobilenet_flower.h5
├─ readme.md
├─ requirements.txt # 安装需求
├─ test_model.py # 模型测试
└─ train_model.py # 模型训练
如何使用
首先你需要git项目到你的本地
确定你的电脑已经安装好了PyQt5、tensorflow2.0以及opencv-python等相关软件,你可以执行下列命令进行安装
cd flower_tensorflow2.3
conda create -n flower_demo
pip install -r requirements.txt
如果你想要重新训练你的模型,请执行
python train_model.py
如果你想要测试模型的准确率,请执行
python test_model.py
如果你想看看图形化的界面,请执行
python window.py
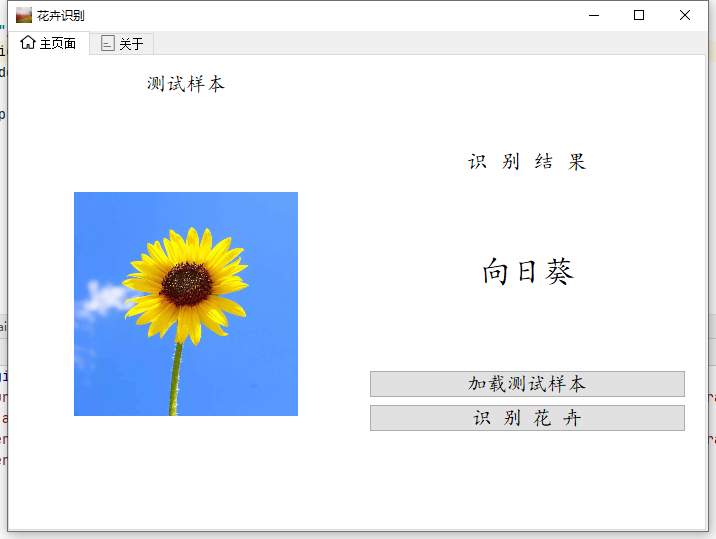
执行效果
图形化界面
捐助
如果您觉得我的项目帮助了您,您可以给我一点小小的鼓励,您的鼓励将会是我进一步创作的动力!😁😁😁



















 4016
4016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











