







目录
3.1 struct file_system_type-文件系统类型
3.2 register_filesystem-注册文件系统
3.3 find_filesystem-查找文件系统是否已被注册
3.4 kern_mount&vfs_kern_mount&vfs_kern_mount
5.源码与测试
0.一些链接
张天飞《奔跑吧,linux内核》,微信读书有此书的电子版本,如果不想买纸质书或电子书,可在微信读书中查阅.1.一些数据结构
file_system_type--文件系统类型的结构体
super_block --每个注册的文件系统都会有对应的超级块,用于存储特定文件系统的习性
inode --存放具体文件的信息
dentry --目录项,方便查找文件
vfsmount --用于挂载,这个是老版本的,新版本的将vfsmount放在了mount结构体中
编写文件系统的过程实际上就是填充这些数据结构并添加进系统的过程.
2.编写一个文件系统的过程
1.创建一个struct file_system_type对象,假设其为my_fs,其创建方式为:
static struct file_system_type my_fs_type = {
.owner = THIS_MODULE,
.name = MYFS,
.mount = myfs_get_sb,
.kill_sb = kill_litter_super
};
name --文件系统的名字
mount --挂载函数,sb代表super block,也许下次再看到的时候,就该有专业敏锐度
kill_sb --卸载函数
2.将创建的文件系统对象注册到文件系统中.3.用到的一些数据结构及函数的原型
3.1 struct file_system_type-文件系统类型
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\include\linux\fs.h
struct file_system_type {
const char *name;
int fs_flags;
#define FS_REQUIRES_DEV 1
#define FS_BINARY_MOUNTDATA 2
#define FS_HAS_SUBTYPE 4
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct hlist_head fs_supers;
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};3.2 register_filesystem-注册文件系统
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\filesystems.c
/**
* register_filesystem - register a new filesystem
* @fs: the file system structure
*
* Adds the file system passed to the list of file systems the kernel
* is aware of for mount and other syscalls. Returns 0 on success,
* or a negative errno code on an error.
*
* The &struct file_system_type that is passed is linked into the kernel
* structures and must not be freed until the file system has been
* unregistered.
*/
/*
注册成功则返回0,注册失败则返回一个负数错误码.
*/
int register_filesystem(struct file_system_type * fs)
{
int res = 0;
struct file_system_type ** p;
BUG_ON(strchr(fs->name, '.'));
if (fs->next)
return -EBUSY;// EBUSY 表示设备或资源正忙
write_lock(&file_systems_lock);
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
write_unlock(&file_systems_lock);
return res;
}
注:
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\include\uapi\asm-generic\errno-base.h
#define EBUSY 16 /* Device or resource busy */3.3 find_filesystem-查找文件系统是否已被注册
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\filesystems.c
static struct file_system_type **find_filesystem(const char *name, unsigned len)
{
struct file_system_type **p;
for (p = &file_systems; *p; p = &(*p)->next)
if (strncmp((*p)->name, name, len) == 0 &&
!(*p)->name[len])
break;
return p;
}
已经注册过,则p不为空;
如果没有注册过,p为NULL,此函数返回NULL.
p = find_filesystem(fs->name, strlen(fs->name));
if (*p)
res = -EBUSY;
else
*p = fs;
如果p为NULL,则将fs赋值给*p.
在这个函数中如果我们请求注册的文件系统不存在,那么将会被链接到struct file_system_type结构体
对象的组成的链表的最后一个节点上.
3.4 kern_mount&vfs_kern_mount&vfs_kern_mount
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\include\linux\fs.h
#define kern_mount(type) kern_mount_data(type, NULL)
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namespace.c
struct vfsmount *kern_mount_data(struct file_system_type *type, void *data)
{
struct vfsmount *mnt;
mnt = vfs_kern_mount(type, SB_KERNMOUNT, type->name, data);
if (!IS_ERR(mnt)) {
/*
* it is a longterm mount, don't release mnt until
* we unmount before file sys is unregistered
*/
real_mount(mnt)->mnt_ns = MNT_NS_INTERNAL;
}
return mnt;
}
EXPORT_SYMBOL_GPL(kern_mount_data);
/*
第一个参数表示文件系统类型;
第二个参数是标志位,SB_KERNMOUNT表示mount操作;
第三个参数是文件系统名称;
第四个是空指针.
*/
struct vfsmount *
vfs_kern_mount(struct file_system_type *type, int flags, const char *name, void *data)
{
struct mount *mnt;
struct dentry *root;
if (!type)
return ERR_PTR(-ENODEV);
mnt = alloc_vfsmnt(name);
if (!mnt)
return ERR_PTR(-ENOMEM);
if (flags & SB_KERNMOUNT)
mnt->mnt.mnt_flags = MNT_INTERNAL;
root = mount_fs(type, flags, name, data);
if (IS_ERR(root)) {
mnt_free_id(mnt);
free_vfsmnt(mnt);
return ERR_CAST(root);
}
mnt->mnt.mnt_root = root;
mnt->mnt.mnt_sb = root->d_sb;
mnt->mnt_mountpoint = mnt->mnt.mnt_root;
mnt->mnt_parent = mnt;
lock_mount_hash();
list_add_tail(&mnt->mnt_instance, &root->d_sb->s_mounts);
unlock_mount_hash();
return &mnt->mnt;
}
EXPORT_SYMBOL_GPL(vfs_kern_mount);
第一个参数是文件系统类型,第二个是表示为3.5 lookup_one_len
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namei.c
/**
* lookup_one_len - filesystem helper to lookup single pathname component
* @name: pathname component to lookup
* @base: base directory to lookup from
* @len: maximum length @len should be interpreted to
*
* Note that this routine is purely a helper for filesystem usage and should
* not be called by generic code.
*
* The caller must hold base->i_mutex.
*/
struct dentry *lookup_one_len(const char *name, struct dentry *base, int len)
{
struct qstr this;//struct qstr是quickstring的意思,简化传递参数,但更重要的作用是保存关于字符串的源数据,即长度和哈希
unsigned int c;
int err;
WARN_ON_ONCE(!inode_is_locked(base->d_inode));
this.name = name;
this.len = len;
this.hash = full_name_hash(base, name, len);// 计算文件的哈希值
if (!len)
return ERR_PTR(-EACCES);
if (unlikely(name[0] == '.')) {
if (len < 2 || (len == 2 && name[1] == '.'))
return ERR_PTR(-EACCES);
}
while (len--) {
c = *(const unsigned char *)name++;
if (c == '/' || c == '\0')
return ERR_PTR(-EACCES);
}
/*
* See if the low-level filesystem might want
* to use its own hash..
*/
if (base->d_flags & DCACHE_OP_HASH) {
int err = base->d_op->d_hash(base, &this);
if (err < 0)
return ERR_PTR(err);
}
err = inode_permission(base->d_inode, MAY_EXEC);
if (err)
return ERR_PTR(err);
return __lookup_hash(&this, base, 0);// 利用之前生成的哈希值来查找同名字的dentry结构,在这里可以体现出dentry的索引作用
}
EXPORT_SYMBOL(lookup_one_len);
3.6__lookup_hash
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namei.c
static struct dentry *__lookup_hash(const struct qstr *name,
struct dentry *base, unsigned int flags)
{
struct dentry *dentry = lookup_dcache(name, base, flags);
if (dentry)// 如果缓存中有这个dentry结构,就将其指针返回
return dentry;
// 如果缓存中没有这个dentry结构,则返回NULL,执行d_alloc,分配新的dentry结构
dentry = d_alloc(base, name);
if (unlikely(!dentry))
return ERR_PTR(-ENOMEM);
// 查找是否有同名的dentry存在,查找的目的是看看是否有其他用户创建了这样的目录
return lookup_real(base->d_inode, dentry, flags);
}
3.7 环形缓冲区
https://www.cnblogs.com/java-ssl-xy/p/7868531.html
3.8 其他待补充很多内容
等待...
4.逻辑图
4.1建立一个文件系统

4.2建立一个文件系统并且创建文件夹和文件

5.源码与测试
5.1内核模块源码
# include <linux/module.h>
# include <linux/fs.h>
# include <linux/dcache.h>
# include <linux/pagemap.h>
# include <linux/mount.h>
# include <linux/init.h>
# include <linux/namei.h>
//current_fsuid函数:
//current_fsgid函数:
# include <linux/cred.h>
//加入misc机制
# include <linux/kfifo.h>
//每个文件系统需要一个MAGIC number
# define MYFS_MAGIC 0X64668735
# define MYFS "myfs"
static struct vfsmount * myfs_mount;
static int myfs_mount_count;
// 初始化一个环形缓冲区,环形缓冲区中有64个字符类型的数据
DEFINE_KFIFO(mydemo_fifo,char,64);
int g_val;
/*底层创建函数*/
static struct inode * myfs_get_inode(struct super_block * sb, int mode, dev_t dev)
{
struct inode * inode = new_inode(sb);// 申请inode空间
// 如果空间申请成功,那么将要对inode的各个内部成员赋值
if(inode)
{
// 访问权限,之前我们赋值的权限
inode -> i_mode = mode;
//@i_uid:user id,用户id
inode->i_uid = current_fsuid();
//@i_gid:group id组标识符
inode->i_gid = current_fsgid();
//@i_size:文件长度
inode -> i_size = VMACACHE_SIZE;
//@i_blocks:指定文件按块计算的长度
inode -> i_blocks = 0;
//@i_atime:最后访问时间
//@i_mtime:最后修改时间
//@i_ctime:最后修改inode时间
inode -> i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
switch(mode & S_IFMT)
{
default:
init_special_inode(inode,mode,dev);
break;
case S_IFREG:// 文件
printk("creat a file\n");
break;
case S_IFDIR:// 文件夹
printk("creat a content\n");
//inode_operations
inode -> i_op = &simple_dir_inode_operations;
//file_operation
inode -> i_fop = &simple_dir_operations;
//@:文件的链接计数,使用stat命令可以看到Links的值,硬链接数目
//inode -> i_nlink++,将文件的链接计数+1
inc_nlink(inode);
break;
}
}
return inode;
}
/*把创建的inode和dentry连接起来*/
static int myfs_mknod(struct inode * dir, struct dentry * dentry, int mode, dev_t dev)
{
struct inode * inode;
int error = -EPERM;
// 判断dentry -> d_inode是否存在,如果存在就退出函数,如果不存在就调用myfs_get_inode去创建inode
if(dentry -> d_inode)
return -EPERM;
inode = myfs_get_inode(dir->i_sb, mode, dev);
if(inode)
{
d_instantiate(dentry,inode);
dget(dentry);
error = 0;
}
return error;
}
/*创建目录*/
static int myfs_mkdir(struct inode * dir, struct dentry * dentry, int mode)
{
int res;
res = myfs_mknod(dir, dentry, mode|S_IFDIR, 0);
if(!res)
{
inc_nlink(dir);
}
return res;
}
/*创建文件*/
static int myfs_creat(struct inode * dir, struct dentry * dentry, int mode)
{
return myfs_mknod(dir, dentry, mode|S_IFREG, 0);
}
/*注册信息*/
static int myfs_fill_super(struct super_block *sb, void *data, int silent)
{
//这个结构体如下:
//struct tree_descr { const char *name; const struct file_operations *ops; int mode; };
static struct tree_descr debug_files[] = {{""}};
return simple_fill_super(sb,MYFS_MAGIC,debug_files);
}
/*
这个函数是按照内核代码中的样子改的,是struct dentry *类型,这里是一个封装,这里可以返回好几种函数:
- mount_single
- mount_bdev
- mount_nodev
*/
static struct dentry *myfs_get_sb(struct file_system_type *fs_type, int flags, const char *dev_name, void *data)
{
return mount_single(fs_type, flags, data, myfs_fill_super);
}
/*文件操作部分*/
/*open 对应于打开aufs文件的方法 */
static int myfs_file_open(struct inode *inode, struct file *file)
{
printk("已打开文件");
return 0;
}
/*read 对应于读取的aufs文件的读取方法 */
/*
read和write实现的方法有很多,这里给出的是kfifo(first in first out)
需要研究一下kfifo这个数据结构,参考张天飞老师的《奔跑吧 Linux内核》(微信读书上可找到本书)
环形缓冲区通常有一个读指针和一个写指针,环形缓冲区通常有一个读指针和一个写指针,
读指针指向环形缓冲区可读的部分,写指针指向环形缓冲区可写部分,通过移动读指针和写指针
来实现缓冲区数据读取和写入,linux也实现了kfifo环形缓冲区可以在一个读线程和写线程并发
执行的情况下不用使用锁机制来保证环形缓冲区的安全,在linux内核中,kfifo机制的API
在include/linux/kfifo.h,kernel/kfifo.c中
*/
static ssize_t myfs_file_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
int actual_readed;
int ret;
// 将环形缓冲区的数据复制到用户空间中
ret = kfifo_to_user(&mydemo_fifo,buf, count, &actual_readed);
if(ret)
return -EIO;
printk("%s,actual_readed=%d,pos=%lld\n",__func__,actual_readed,*ppos);
return actual_readed;
}
/*write 对应于写入的aufs文件的写入方法 */
static ssize_t myfs_file_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
// actual_write用作保存成功复制数据的数量
unsigned int actual_write;
int ret;
// kfifo_from_user 将用户空间的数据写入环形缓冲区
ret = kfifo_from_user(&mydemo_fifo, buf, count, &actual_write);
if(ret)
return -EIO;
printk("%s: actual_write=%d,ppos=%lld\n",__func__,actual_write,*ppos);
return actual_write;
}
/* 文件系统类型的对象my_fs_type的初始化 */
static struct file_system_type my_fs_type = {
.owner = THIS_MODULE,
.name = MYFS,
.mount = myfs_get_sb,// super block
.kill_sb = kill_litter_super
};
/* 文件的操作函数-打开,读,写 */
static struct file_operations myfs_file_operations = {
.open = myfs_file_open,
.read = myfs_file_read,
.write = myfs_file_write,
};
/*根据名字创建文件夹或者文件*/
static int myfs_creat_by_name(const char * name, mode_t mode,struct dentry * parent, struct dentry ** dentry)
{
int error = 0;
// 首先判断是否有父目录,如果没有父目录就赋一个父目录
if(!parent)
{
if(myfs_mount && myfs_mount -> mnt_sb)
{
parent = myfs_mount->mnt_sb->s_root;
}
}
if(!parent)
{
printk("can't find a parent");
return -EFAULT;
}
*dentry = NULL;
inode_lock(d_inode(parent));// 可以将锁注释掉然后编译试试,看看会发生什么情况
// lookup_one_len这个函数的作用是在父目录下根据名字来查找dentry结构,如果存在就返回指针,如果不存在就创建一个dentry结构
*dentry = lookup_one_len(name,parent,strlen(name));
if(!IS_ERR(*dentry))
{
// 如果是目录,那么就执行myfs_mkdir
if((mode & S_IFMT) == S_IFDIR)
{
error = myfs_mkdir(parent->d_inode, *dentry, mode);
}
else
{
error = myfs_creat(parent->d_inode, *dentry, mode);
}
}
//error是0才对
if (IS_ERR(*dentry)) {
error = PTR_ERR(*dentry);
}
inode_unlock(d_inode(parent));
return error;
}
/*
用来创建文件或者文件夹
第一个参数:文件夹或文件的名字;
第二个参数:文件夹或文件的权限;
第三个参数:父目录项
第四个参数: 对应的是Inode里面的iprivate字段
第五个参数: fops,操作函数
*/
struct dentry * myfs_creat_file(const char * name, mode_t mode,
struct dentry * parent, void * data,
struct file_operations * fops)
{
struct dentry * dentry = NULL;
int error;
printk("myfs:creating file '%s'\n",name);
error = myfs_creat_by_name(name, mode, parent, &dentry);
if(error)
{
dentry = NULL;
goto exit;
}
if(dentry->d_inode)
{
if(data)
dentry->d_inode->i_private = data;
if(fops)
dentry->d_inode->i_fop = fops;
}
exit:
return dentry;
}
/*
第一个参数:文件夹的名字;
第二个参数:父目录项
*/
struct dentry * myfs_creat_dir(const char * name, struct dentry * parent)
{
//使用man creat查找
//@S_IFREG:表示一个目录
//@S_IRWXU:user (file owner) has read, write, and execute permission
//@S_IRUGO:用户读|用户组读|其他读
return myfs_creat_file(name, S_IFDIR|S_IRWXU|S_IRUGO, parent, NULL, NULL);
}
/*模块注册*/
static int __init myfs_init(void)
{
int retval;
struct dentry * pslot;
//将文件系统登录到系统中去
retval = register_filesystem(&my_fs_type);
if(!retval)
{
//创建super_block根dentry的inode
myfs_mount = kern_mount(&my_fs_type);
//如果装载错误就卸载文件系统
if(IS_ERR(myfs_mount))
{
printk("--ERROR:aufs could not mount!--\n");
unregister_filesystem(&my_fs_type);
return retval;
}
}
pslot = myfs_creat_dir("First", NULL);
//@S_IFREG:表示一个文件
//@S_IRUGO:用户读|用户组读|其他读
myfs_creat_file("one", S_IFREG|S_IRUGO|S_IWUSR, pslot, NULL, &myfs_file_operations);
myfs_creat_file("two", S_IFREG|S_IRUGO|S_IWUSR, pslot, NULL, &myfs_file_operations);
pslot = myfs_creat_dir("Second", NULL);
myfs_creat_file("one", S_IFREG|S_IRUGO|S_IWUSR, pslot, NULL, &myfs_file_operations);
myfs_creat_file("two", S_IFREG|S_IRUGO|S_IWUSR, pslot, NULL, &myfs_file_operations);
return retval;
}
/*模块退出*/
static void __exit myfs_exit(void)
{
//退出函数中卸载super_block根dentry的inode
simple_release_fs(&myfs_mount,&myfs_mount_count);
//卸载文件系统
unregister_filesystem(&my_fs_type);
//aufs_mount = NULL;
}
module_init(myfs_init);
module_exit(myfs_exit);
MODULE_LICENSE("GPL");
/*
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\include\uapi\linux\stat.h
#define S_IFMT 00170000 1111 0000 0000 0000
#define S_IFSOCK 0140000 1100 0000 0000 0000
#define S_IFLNK 0120000 1010 0000 0000 0000
#define S_IFREG 0100000 1000 0000 0000 0000
#define S_IFBLK 0060000 0110 0000 0000 0000
#define S_IFDIR 0040000 0100 0000 0000 0000
#define S_IFCHR 0020000 0010 0000 0000 0000
#define S_IFIFO 0010000 0001 0000 0000 0000
#define S_ISUID 0004000 0000 1000 0000 0000
#define S_ISGID 0002000 0000 0100 0000 0000
#define S_ISVTX 0001000 0000 0010 0000 0000
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\fs\dcache.c
* d_instantiate - fill in inode information for a dentry
* @entry: dentry to complete
* @inode: inode to attach to this dentry
*
* Fill in inode information in the entry.
*
* This turns negative dentries into productive full members
* of society.
*
* NOTE! This assumes that the inode count has been incremented
* (or otherwise set) by the caller to indicate that it is now
* in use by the dcache.
void d_instantiate(struct dentry *entry, struct inode * inode)
{
BUG_ON(!hlist_unhashed(&entry->d_u.d_alias));
if (inode) {
security_d_instantiate(entry, inode);
spin_lock(&inode->i_lock);
__d_instantiate(entry, inode);
spin_unlock(&inode->i_lock);
}
}
EXPORT_SYMBOL(d_instantiate);
void d_instantiate(struct dentry *entry, struct inode * inode)
{
BUG_ON(!hlist_unhashed(&entry->d_u.d_alias));
if (inode) {
security_d_instantiate(entry, inode);
spin_lock(&inode->i_lock);
__d_instantiate(entry, inode);
spin_unlock(&inode->i_lock);
}
}
EXPORT_SYMBOL(d_instantiate);
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\include\linux\dcache.h
static inline struct dentry *dget(struct dentry *dentry)
{
if (dentry)
lockref_get(&dentry->d_lockref);
return dentry;
}
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\lib\lockref.c
* lockref_get - Increments reference count unconditionally
* @lockref: pointer to lockref structure
*
* This operation is only valid if you already hold a reference
* to the object, so you know the count cannot be zero.
void lockref_get(struct lockref *lockref)
{
CMPXCHG_LOOP(
new.count++;
,
return;
);
spin_lock(&lockref->lock);
lockref->count++;
spin_unlock(&lockref->lock);
}
EXPORT_SYMBOL(lockref_get);
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\fs\libfs.c
const struct inode_operations simple_dir_inode_operations = {
.lookup = simple_lookup,
};
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\fs\libfs.c
struct dentry *simple_lookup(struct inode *dir, struct dentry *dentry, unsigned int flags)
{
if (dentry->d_name.len > NAME_MAX)
return ERR_PTR(-ENAMETOOLONG);
if (!dentry->d_sb->s_d_op)
d_set_d_op(dentry, &simple_dentry_operations);
d_add(dentry, NULL);
return NULL;
}
E:\004-代码\002-内核源码\linux-4.15.1\linux-4.15.1\fs\libfs.c
const struct file_operations simple_dir_operations = {
.open = dcache_dir_open,
.release = dcache_dir_close,
.llseek = dcache_dir_lseek,
.read = generic_read_dir,
.iterate_shared = dcache_readdir,
.fsync = noop_fsync,
};
*/
/*
关于文件系统数据结构图:
需要注意的是不管是file_operations还是inode_operations,都是在inode结构体中的,
我们可以看到
inode_operations中有lookup,mkdir,rmdir等操作函数,
file_operations是对文件的操作,有read,write,open等操作函数,
在初学文件系统的时候可能就会有一个疑问:
mkdir,rmdir应该是对目录的操作,而目录的操作为什么不在dentry结构体中呢?
这个是因为在linux中一切皆文件,不管是文件夹还是文件,都是有dentry和inode共同描述,
也就是说文件夹有自己的dentry和inode结构体,文件也有自己的dentry和inode结构体,
inode用来存放元数据,
当它是文件夹的时候,则执行inode_operations中的操作;
当它是文件的时候,则执行file_operations中的操作.
insmod my_file_system.ko
lsmod
dmesg
接下来要进行挂载,什么是挂载?简单来说,系统本身有一个“/”文件树,我们自己的my_file_system是一个树枝,
挂载就是将这个树枝挂到树上,并且以后从树找到这个树枝,mount命令执行后,会调用sysmount系统调用,可以在源代码
中看一下这个简单过程.
SYSCALL_DEFILE5
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\include\linux\syscalls.h
#define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__)
#define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__)
问题:
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namespace.c与
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namei.c
有什么区别?它们都定义了SYSCALL_DEFINE5.
D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namespace.c
中的SYSCALL_DEFINE5调用了do_mount函数
do_mount函数也在D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namespace.c中.
由于我们这里是第一次操作,所以此时do_mount函数调用的是do_new_mount函数.
do_new_mount函数也在D:\005-代码\001-开源项目源码\004-内核源码\linux-4.15.1\linux-4.15.1\fs\namespace.c中.
在这里又可以看到我们之前分析的vfs_kern_mount函数,即用来创建根dentry和根inode结构体,这里又执行了一次,由于之前
我们之前插入内核模块的时候已经执行了一次,所以在这里获取的就是我们刚刚执行的生成的结构体.
之后执行do_add_mount,
把原文件系统挂载到目的文件系统.
挂载过程:
进入根目录 cd /
创建文件夹 /myfs/
挂载 mount -t myfs none /myfs/
(t表述文件系统类型)
到目录/myfs/下查看我们在内核代码中创建的两个文件夹和两个文件夹下的分别两个文件,都和我们的预期一致.
cat /proc/filesystems
官方文档中对linux内核中的文件系统的描述也十分详细,可对其进行阅读学习.
https://www.kernel.org/doc/html/latest/filesystems/index.html
*/5.2 Makefile文件的编写
#modules:
# $(MAKE) -C $(KERNELDIR) M=$(PWD) modules
#
#这句是Makefile的规则:这里的$(MAKE)就相当于make,-C 选项的作用是指将当前工作目录转移到你所指定的位置。
#“M=”选项的作用是,当用户需要以某个内核为基础编译一个外部模块的话,需要在make modules 命令中加入“M=dir”,
#程序会自动到你所指定的dir目录中查找模块源码,将其编译,生成KO文件。
module_name=my_file_system
obj-m := $(module_name).o
myHello := module
kdir := /lib/modules/4.10.1/build
myinclude := /root/
all:
make -I $(myinclude) -C $(kdir) SUBDIRS=$(PWD) modules
clean:
rm -rf *.ko Module.* *.mod.* modules.* *.o
i:
insmod $(module_name).ko
r:
rmmod $(module_name).ko
ir:
insmod $(module_name).ko
sleep 1
rmmod $(module_name).ko5.3 用户测试程序源码
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <malloc.h>
#include <string.h>
#define FILE_NAME "/myfs/First/one"
int main()
{
char buffer[64];
int fd;
int ret;
size_t len;
char message[] = "I am myfs";
char *read_buffer;
len = sizeof(message);
fd = open(FILE_NAME,O_RDWR);
if(fd<0)
{
printf("open wrong\n");
return -1;
}
ret = write(fd,message,len);
if(ret != len)
{
printf("write wrong");
return -1;
}
read_buffer = malloc(2*len);
memset(read_buffer,0,2*len);
ret = read(fd,read_buffer,2*len);
printf("read %d bytes",ret);
printf("read buffer = %s\n",read_buffer);
close(fd);
return 0;
}5.4 一些测试截图
图一:插入内核模块及执行测试代码之后dmesg得到;
图二:插入内核模块之后查看当前系统所拥有的文件系统类型得到.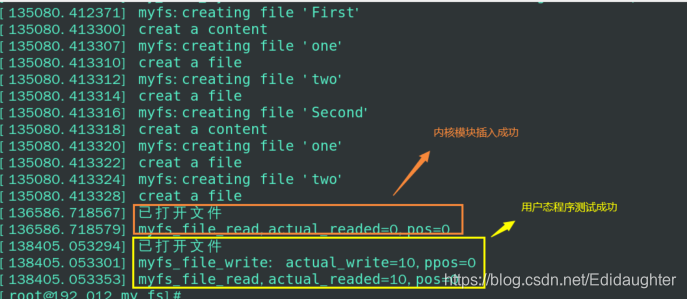















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









