









读者要先自行安装python以及anaconda,并且配置pytorch环境
第一步 测试环境
import torch
# 判断macOS的版本是否支持
print(torch.backends.mps.is_available())
# 判断mps是否可用
print(torch.backends.mps.is_built())
- 如果第一个语句为
False,说明当前MacOS的版本不够,需要升级到12.3版本及以上,且安装了arm64原生Python - 如果第二个语句为
Fasle,代表还没有安装nightly版本的Pytorch
第二步 安装nightly版本的Pytorch
conda install pytorch torchvision torchaudio -c pytorch-nightly
安装完成后使用
print(torch.backends.mps.is_built())
进行验证是否可以使用mps进行训练
当两项都为True的时候,在进行下面的步骤
第三步 使用GPU进行训练
代码演示为自定义的CIFAR10数据集的训练 可以参考【Pytorch】13.搭建完整的CIFAR10模型
首先我们先要引入设备
# 配置GPU为mps
device = torch.device("mps")
然后我们需要在三处添加为gpu训练
- 神经网络对象
- 损失函数
- DataLoader中的数据
# 3.创建神经网络
model = CIFAR10Model().to(device)
# 4.设置损失函数与梯度下降算法
loss_fn = nn.CrossEntropyLoss().to(device)
for data in train_loader:
# 训练基本流程
inputs, labels = data
# 加入gpu训练
inputs, labels = inputs.to(device), labels.to(device)
with torch.no_grad():
for data in test_loader:
# 测试集流程
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
分别在上面四处进行修改
就可以实现m1芯片来进行gpu训练
性能对比
M1 mac CPU训练

batch_size=64的情况下每训练100次的时间
M1 mac GPU训练
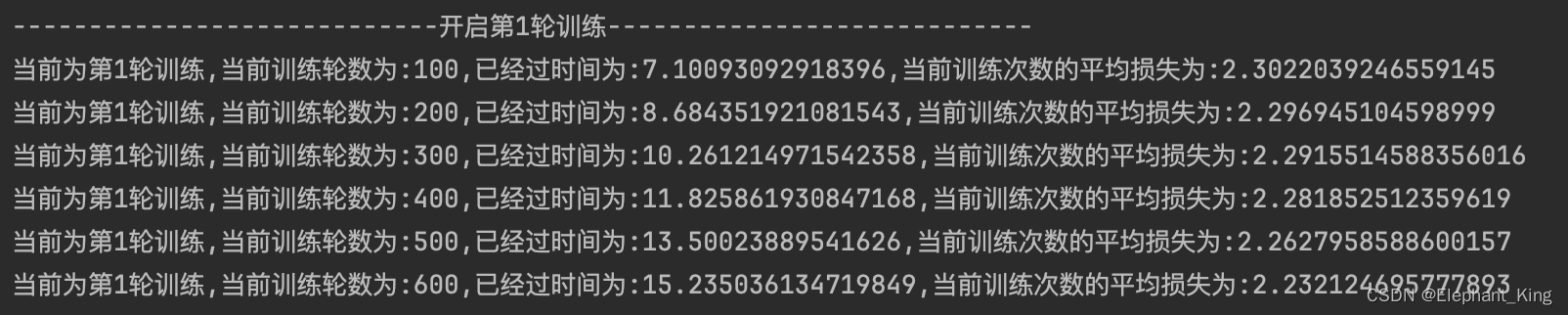
batch_size=64的情况下每训练100次的时间
我们可以看到使用GPU的速度在本模型中还是比CPU快不少的
参考文章
炼丹速度×7!你的Mac电脑也能在PyTorch训练中用GPU加速了
【MacOS】MacBook使用本机m1芯片GPU训练的方法(mps替代cuda)















 3166
3166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









