









背景
大模型训练好后,进行部署时,发现可使用的显卡容量远大于模型占用空间 。是否可以同时加载多个模型实例到显存空间,且能实现多个实例同时并发执行?本次实验测试基于mps的方案,当请求依次过来时,多个相同的实例推理任务就可以同时运行。显然,该方法需要显卡测提供某种支持。这种就是 nvidia 的 Multi-Processing Services,即显卡多进程服务。一些网上公布的资料[1],主要是基于已经编译好的二进制程序在终端,通过指定不同的配置参数,如多进程数量,测试不同进程数执行同样的推理任务耗时,来证明mps对于并发推理任务的支持。本次实验基于Pytorch的模型仓库和多进程库,来实现类似的测试。
MPS的开启和关闭
# 服务开启
export CUDA_VISIBLE_DEVICES=0
nvidia-smi -i 0 -c 3 # -c 3 同 -c EXCLUSIVE_PROCESS
nvidia-cuda-mps-contrl -d
服务开启成功后并不会有任何显示,只有当运行一次任务后才能看到服务进程。
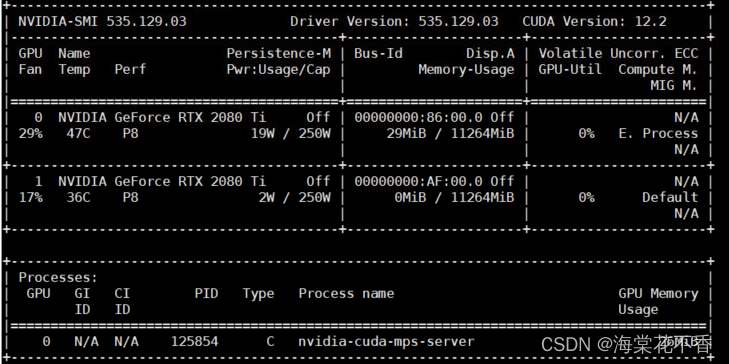
# 服务关闭
sudo nvidia-cuda-mps-control quit # 通常不能关闭mps服务,需要强制关闭
ps -ef | grep mps # 查看mps的进程号
sudo kill -9 mps的进程号
Pytorch 多进程管理多个cuda流
nvidia显卡上的并发推理计算,是通过cuda流来管理的。在 mps 服务的模型中,cpu进程与cuda流的关系,可以总结为,一个cpu进程管理一个或多个流 [2]。

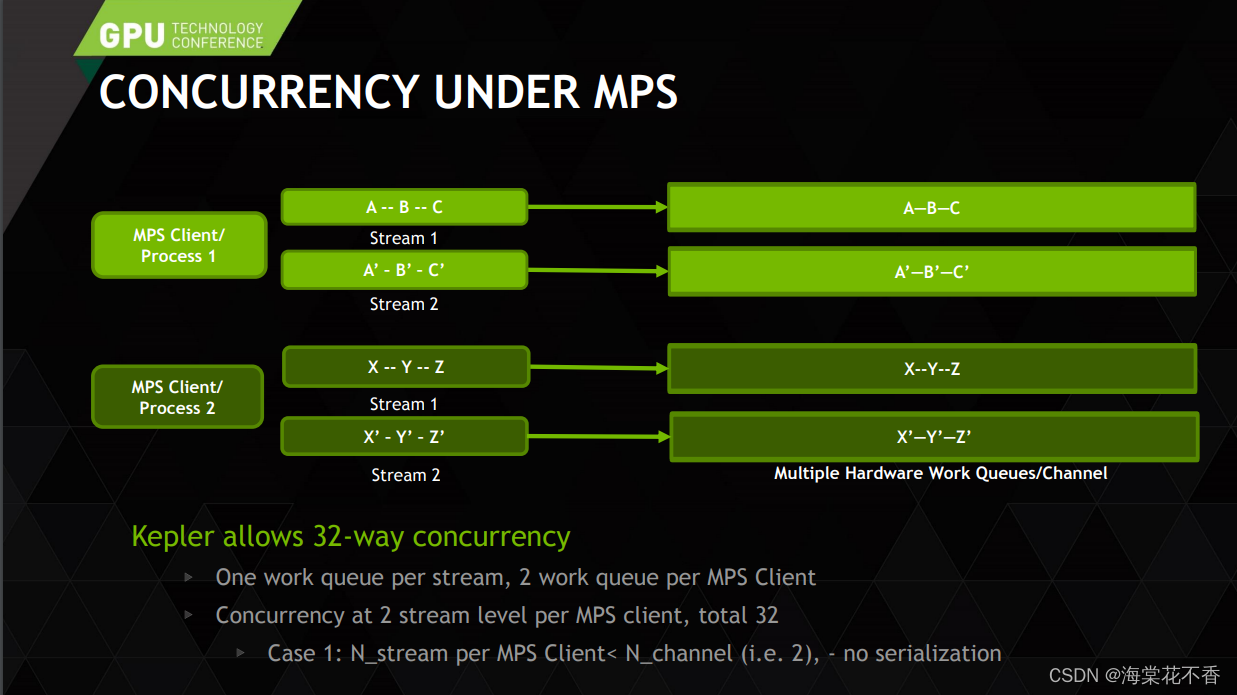
根据以上文献资料指导,编写基于Pytorch多进程客户端测试代码:
import torch
import torchvision
import time
import os
import torchvision.models as models
from PIL import Image
import copy
device = torch.device('cuda')
# 装饰器,用于计算推理耗时
def getCompDuration(func):
def warpper(*args, **kwargs):
print("%s is running" % func.__name__)
start = time.time()
result = func(*args, **kwargs)
end = time.time()
computeTime = end - start
print('forward time cost: %.5f sec' %computeTime)
return result
return wrapper
def getInputData(device = device):
img = Image.open('your/data.jpg').convert('RGB')
img = torchvision.transforms.ToTensor()(img)
print(f'img:{img.shape}, rquires_grad:{img.requires_grad}')
imgs = [img.to(device)]
return imgs
@getCompDuration
def modelForwardImage(input, model, nTimes, stream, device = device):
pid = os.getpid()
model.eval()
for i in range(nTimes):
with torch.no_grad(): # 非常重要,用于降低显存消耗
predictions = model(input)
pred = predictions[0]['boxes'].shape
print(f'pid:{pid}, stream:{stream}, predict result:{pred}')
def getModels(nProcess, device = device):
modellist = []
with torch.no_grad():
model = models.detection.maskrcnn_resnet50_fpn(pretrained = False, pretrained_backbone = False)
model.load_state_dict(torch.load('./your/dir/maskrcnn_resnet50_fpn_coco-bf2d0c1e.pth'))
for i in range(nProcess):
mod = copy.deepcopy(model)
mod.to(device)
modellist.append(mod)
return modellist
def funcInStream(input, model, nTimes):
stream = torch.cuda.Stream()
with torch.cuda.stream(stream):
modelForwardImage(input, model, nTimes, stream)
def test(nTimes, nProcess):
input = getInputData()
# spwan是多任务的一种方式
ctx = torch.multiprocessing.get_context('spawn')
models = getModels(nProcess)
pool = []
for i in range(nProcess):
p = ctx.Process(target = funcInStream, args = (input, models[i], nTimes))
pool.append(p)
for p in pool:
p.start()
if __name__ == '__main__':
nTimes = 50
nProcess = 2
test(nTimes, nProcess)
以上代码,可分别控制循环执行nTimes次的maskrcnn的前向推理任务,和nProcess的进程数,观察单进程及多进程执行相同任务的计算耗时。同时可观察打开或者关闭mps服务下,单/多进程执行相同任务的耗时表现。这里提供关闭/开启mps服务后,一组不同控制变量下的耗时记录。
关闭mps服务下,统计不同任务、不同进程数下的耗时情况
| nTimes/nProcess | 1 (单进程)/sec | 2 (双进程)/sec | 双进程耗时/单进程耗时 |
|---|---|---|---|
| 50 | 5.77 | (6.80, 5.69) | 1.08 |
| 100 | 11.49 | (19.87, 18.49) | 1.67 |
| 200 | 23.40 | (47.39, 46.01) | 1.99 |
| 400 | 45.00 | (100.18, 98.80) | 2.21 |
开启mps服务下,统计不同任务、不同进程数下的耗时情况
| nTimes/nProcess | 1 (单进程)/sec | 2 (双进程)/sec | 双进程耗时/单进程耗时 |
|---|---|---|---|
| 50 | 5.54 | (5.64, 5.48) | 1.00 |
| 100 | 11.08 | (13.73, 13.36) | 1.22 |
| 200 | 23.98 | (28.45, 27.53) | 1.17 |
| 400 | 46.57 | (59.85, 59.89) | 1.29 |
| 400* | 44.59 | (killed, 44.21) | 0.99 |
补充实验 400*,在双进程运行期间,手动关闭一个进程,kill -9 进程号。另一个进程会正常运行直至结束,其运行时间会接近单进程运行时间。
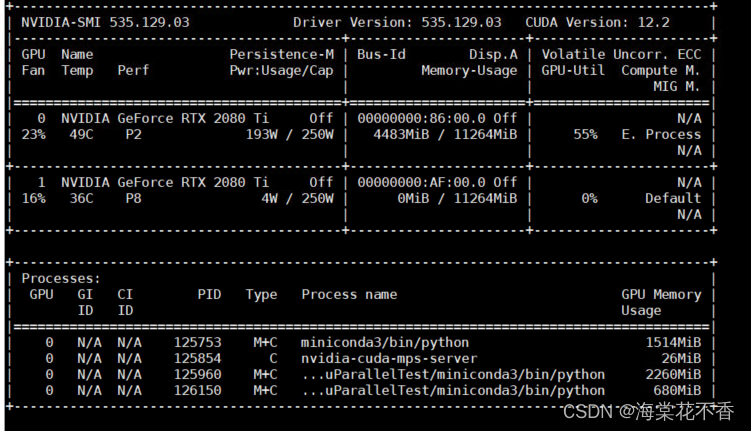
终端运行结果部分展示


总结
- 不开启mps服务下,相同任务的双进程耗时是单进程耗时的2倍,说明双进程是串行运行的。符合预期。
- 开启mps服务下,相同让任务的双进程耗时是单进程耗时的1~1.3倍,说明两个进程在并发运行,但是有抢占某种资源的情况,无法做到接近单进程耗时,需要进一步研究。
参考文档
[1] 如何使用MPS提升GPU计算收益
[2] IMPROVING GPU UTILIZATION WITH MULTI-PROCESS SERVICE (MPS)















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









